Executive Summary
이 글은 DataClinic 리포트 #42의 분석을 바탕으로 합니다. 진단 대상은 30VNFoods — 캐글(Kaggle)에 공개된 베트남 음식 30종, 모두 17,581장의 이미지 데이터셋입니다. 한국 음식 데이터셋이 15만 장 규모인 것과 비교하면 1/8 정도의 작은 데이터셋입니다. 작으니 더 깨끗할 거라 기대하기 쉽지만, DataClinic의 L2·L3 렌즈로 들여다보니 오히려 작은 데이터셋 특유의 균열이 더 선명하게 드러났습니다.
가장 눈에 띄는 발견은 같은 사진이 두 개의 다른 이름표를 달고 있다는 것입니다. 반지오(Banh gio) 폴더의 한 장과 반베오(Banh beo) 폴더의 한 장이 픽셀 수준으로 같은 사진인데, 서로 다른 정답 레이블이 붙어 있습니다. 이 쌍은 17,581장 전체에서 서로의 가장 가까운 이웃으로 잡혔고, 1,280차원을 61차원으로 줄이는 최적화 후에도 그대로 남았습니다. 모델의 문제가 아니라 데이터 자체의 무결성 문제라는 뜻입니다.
나머지 두 균열은 음식이 주인공이 아닌 사진들(아기가 든 반쯩, 개가 배경인 반미)과, 늘 같은 한 장면이었던 반짱느엉(야간 포장마차 그릴 한 가지 구도로 쏠린 수집)입니다. 세 균열 모두 "숫자는 충분한데 정보는 빈약한" AI 학습 데이터의 전형적 위험을 보여줍니다.
※ DataClinic #42는 공개 API로 종합 점수·등급이 제공되지 않아, 이 글은 점수 단정 대신 구조적·정성적 진단을 중심으로 서술합니다. 페블로스코프 스냅샷도 이 리포트에는 생성되어 있지 않아, 클러스터의 "왜"는 클래스별 밀도 플롯으로 대신 설명합니다.
베트남 거리의 30가지 맛
30VNFoods는 쌀국수 포(Pho)부터 바게트 샌드위치 반미(Banh mi), 후에식 소고기 국수 분보후에(Bun bo Hue)까지 베트남의 대표 음식 30종을 모은 이미지 분류 데이터셋입니다. 대부분 거리 노점과 가정식 식탁에서 찍힌 사진으로, 캐글에 공개되어 음식 인식 AI 연구에 자주 쓰입니다. 먼저 데이터셋 전체의 인상을 콜라주로 살펴봅니다.

▲ 30VNFoods 콜라주 (DataClinic L1) — 색감과 그릇, 촬영 환경이 클래스마다 제각각입니다.
콜라주의 인상을 숫자로 옮기면 데이터셋의 골격이 드러납니다. 30종 17,581장은 클래스당 평균 586장이지만 표준편차가 176장으로, 평균이라는 한 숫자 뒤에 적지 않은 쏠림이 숨어 있습니다. 아래 두 장의 카드는 데이터셋의 기본 사양(왼쪽)과, 그 쏠림의 가장 뚜렷한 형태인 클래스 불균형(오른쪽)을 정리한 것입니다.
📊 데이터셋 사양
- 17,581장 · 30개 클래스
- 클래스당 평균 586장 (표준편차 176)
- 이미지 크기 100×83 ~ 7,360×4,912px (편차 큼)
- 채널 전부 RGB, 결측치 없음
- 출처 Kaggle — quandang/vietnamese-foods
⚖️ 클래스 불균형 (3.5배)
가장 많은 클래스와 가장 적은 클래스의 이미지 수가 3.5배 차이 납니다.
DataClinic은 데이터를 세 단계의 렌즈로 진단합니다. L1은 이미지 크기·채널·결측치·클래스 균형 같은 기본 무결성을, L2는 범용 신경망(Wolfram ImageIdentify Net V2, 1,280차원)의 잠재 공간 구조를, L3는 그 1,280차원에서 클래스 구별력을 유지하는 61차원만 추려낸 특화 렌즈로 데이터를 다시 봅니다. 같은 데이터셋도 렌즈를 바꾸면 다른 균열이 드러납니다.
L1 — 평균 이미지가 말하는 것
L1 진단에서 30VNFoods는 기본기가 양호합니다. 라벨 정합성에 문제가 없고, 채널은 전부 RGB로 통일되어 있으며, 결측치도 없습니다. 다만 이미지 크기가 100픽셀짜리부터 7,360픽셀짜리까지 크게 벌어져 있어, 학습 전 리사이즈 전처리는 필요합니다.
여기서 흥미로운 건 클래스 평균 이미지입니다. 한 클래스의 모든 사진을 픽셀 단위로 평균 내면, 그 클래스가 얼마나 균질한지가 한눈에 보입니다. 평균이 또렷하면 비슷한 구도가 반복됐다는 뜻이고, 평균이 뿌옇게 뭉개지면 그만큼 다양한 사진이 섞였다는 뜻입니다. 아래는 6개 클래스의 실제 샘플(왼쪽)과 평균 이미지(오른쪽)를 나란히 둔 것입니다.
 실제
실제
 평균
평균
 실제
실제
 평균
평균
 실제
실제
 평균
평균
 실제
실제
 평균
평균
 실제
실제
 평균
평균
 실제
실제
 평균
평균
▲ 각 카드 왼쪽: 클래스 대표 이미지(실제 샘플) / 오른쪽: 평균 이미지 (DataClinic L1)
반짱느엉의 평균 이미지는 윤곽이 꽤 또렷합니다. 야간 그릴 위 원형 라이스페이퍼라는 같은 구도가 반복됐다는 신호입니다. 반대로 반쯩의 평균은 형체를 알아보기 어렵게 뭉개져 있습니다. 잎으로 싼 것, 잘라 속을 보인 것, 사람이 든 것까지 너무 다양한 사진이 섞였기 때문입니다. L1의 평균 이미지는 L2·L3에서 본격적으로 드러날 "균질 vs 다양"의 예고편인 셈입니다.
L2 — 1,280차원이 본 음식
L2는 범용 신경망(Wolfram ImageIdentify Net V2)이 추출한 1,280차원 특징 공간에서 데이터를 봅니다. 먼저 전체 분포를 PCA로 2차원에 투영한 그림입니다. 30종이 또렷한 섬으로 갈라지기보다 가운데 하나의 큰 덩어리로 겹쳐 있습니다. 음식 사진은 그릇·배경·조명이 비슷해서 클래스 사이 경계가 흐릿한, 전형적인 미세 분류(fine-grained) 문제라는 뜻입니다.
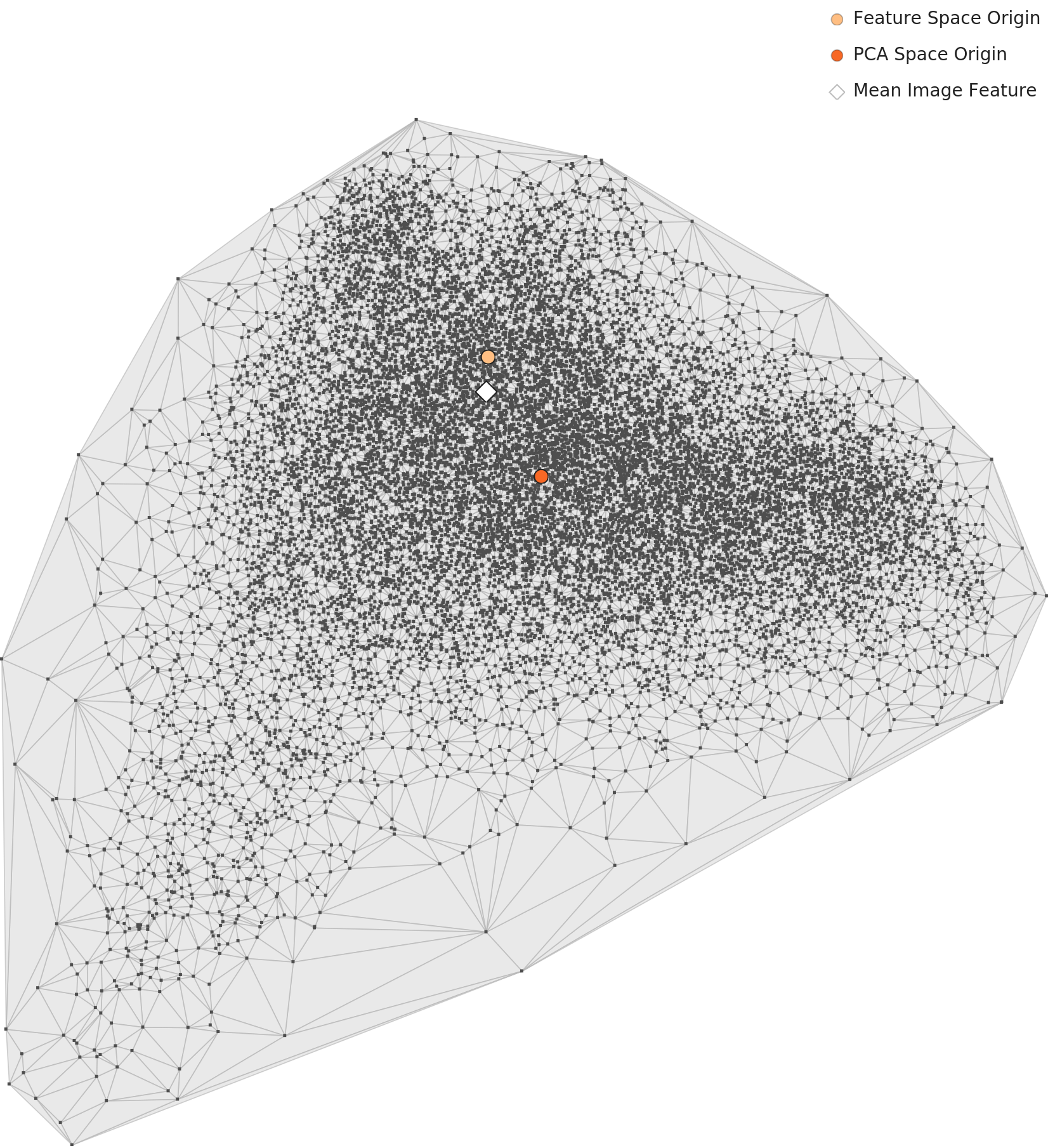
▲ L2 PCA 전체 분포 (Wolfram 1,280차원 렌즈).
※ 이 PCA 그림의 점은 단색으로 찍혀 있어 클래스별 색 구분은 되지 않습니다. 따라서 "어느 클래스가 어디에 있는지"가 아니라 "전체가 한 덩어리로 겹친다"는 분포의 형태만 읽어야 합니다.
클래스 사이의 차이를 보려면 밀도 플롯이 더 분명합니다. DataClinic은 각 클래스가 특징 공간에서 얼마나 빽빽하게 뭉쳐 있는지를 밀도 값으로 매깁니다. 밀도가 높으면 비슷한 사진이 한곳에 몰려 있다는 뜻이고, 낮으면 넓게 흩어져 있다는 뜻입니다. L2에서 두 극단을 보여주는 것이 반짱느엉과 반쯩입니다.
 밀도
실제
밀도
실제
 밀도
실제
밀도
실제
▲ L2 밀도 플롯(좌) + 대표 이미지(우). 반짱느엉은 좁은 핵에 몰리고, 반쯩은 넓게 퍼집니다.
전체 밀도 지형도(아래)에서도 L2 단계에서는 색이 전반적으로 창백하고 고르게 퍼져 있습니다. 범용 렌즈로 보면 음식들이 비슷비슷한 "음식 사진"이라는 큰 공통점 안에 묻혀 있어, 이상치 신호가 아직 약하게만 잡힙니다. 이 신호는 L3에서 차원을 줄였을 때 비로소 또렷해집니다.

▲ L2 밀도 히트맵 — 전반적으로 창백하고 균일. 이상치 대비가 약합니다.
L3 — 61차원으로 좁힌 렌즈
L3는 1,280차원 중에서 클래스를 구별하는 데 실제로 기여하는 61차원만 남긴 특화 렌즈입니다. 차원의 95%를 덜어냈는데도 전체 위상(데이터의 큰 윤곽)은 보존됩니다. 대신 밀도 대비가 극적으로 커집니다. L2에서 0.04~0.27이던 밀도 값이 L3에서는 0.75~2.60으로 약 10배 증폭됩니다. 이 숫자가 데이터가 좋아졌다는 뜻은 아닙니다. 같은 점들이 더 좁은 공간에 모이면서 밀도 값 자체가 커진 것뿐입니다. 중요한 건 절대값이 아니라, 그 결과 전형적인 것과 이질적인 것의 대비가 또렷해졌다는 점입니다.
| 항목 | L2 (1,280차원) | L3 (61차원) |
|---|---|---|
| 관측 차원 | 1,280 | 61 (−95.2%) |
| 밀도 값 범위 | 0.04 – 0.27 | 0.75 – 2.60 (약 10배) |
| 밀도 히트맵 | 창백·균일 | 짙은 적색 코어 + 방사형 가지 |
| 최고밀도 클래스 | 반짱느엉 | 반짱느엉 (Top 5 독점) |
| 최저밀도 변화 | 반삐어 등 | 반미·차오롱 신규 진입 |
| 반지오 ↔ 반베오 중복 | 최근접 쌍 | 여전히 최근접 쌍 (미해소) |
L3 밀도 히트맵(아래)을 보면 L2의 창백한 분포가 가운데 짙은 적색 코어와 바깥으로 뻗는 방사형 가지로 바뀝니다. 코어는 30종이 겹치는 일반적인 "음식 사진" 영역이고, 왼쪽 위로 길게 뻗은 가장 짙은 가지가 반짱느엉이 만든 별도의 고밀도 줄기입니다. 가장자리의 창백한 삼각형 칸들은 저밀도 이상치, 곧 음식이 주인공이 아닌 사진들입니다.
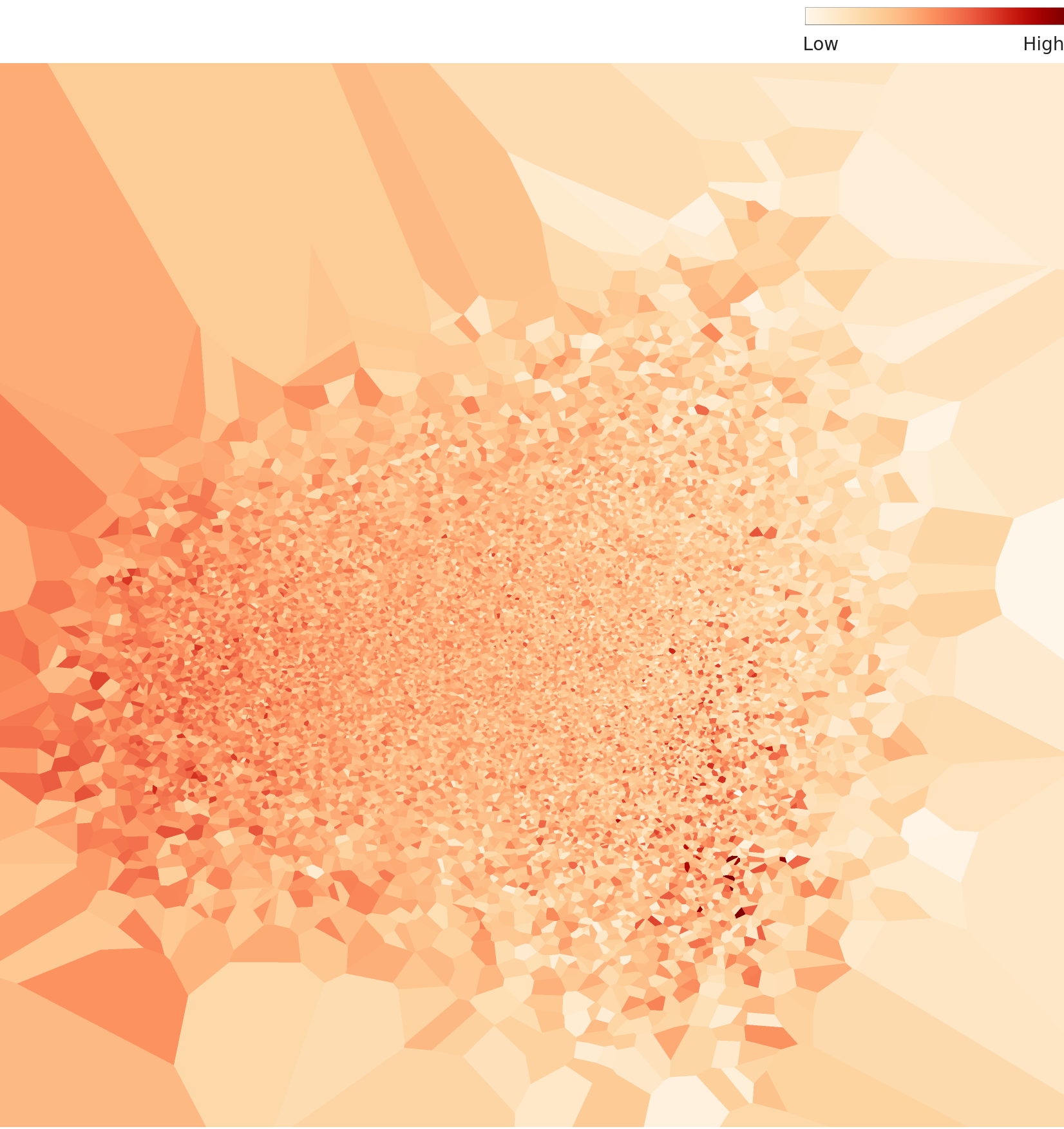
▲ L3 밀도 히트맵 — 차원을 95% 줄이자 밀도 대비가 또렷해졌습니다. (L2 대비 같은 데이터, 다른 렌즈)
클래스별 밀도 플롯에서 가장 주목할 것은 반지오입니다. 본체는 옅게 퍼져 있는데, 본체에서 떨어진 곳에 작고 짙은 점 하나가 외딴섬처럼 찍혀 있습니다. 이 고립된 노드가 바로 다음 섹션에서 자세히 볼 반베오와 사실상 같은 사진입니다. 반짱느엉은 여전히 가장 좁고 짙은 핵을, 반쯩은 가장 넓은 확산을 보입니다.
 밀도
실제
밀도
실제
 밀도
밀도
 실제
실제
▲ L3 클래스별 밀도 플롯. 반지오의 본체에서 떨어진 고립 노드가 중복 라벨의 시각적 근거입니다.
차원을 95% 줄이는 최적화는 위상은 보존하면서 신호를 날카롭게 다듬습니다. 그래서 반짱느엉처럼 균질한 클래스는 더 극단으로 몰리고, 반쯩·반뗏처럼 다양한 클래스는 여전히 넓게 흩어집니다. 하지만 반지오와 반베오의 중복은 L2에서도, L3에서도 그대로입니다. 차원 최적화로 풀리지 않는다는 것은, 이것이 렌즈(모델)의 문제가 아니라 데이터 자체에 박힌 문제라는 가장 강한 증거입니다.
실전 임팩트 — 세 가지 균열
진단 결과를 "그래서 이 데이터로 AI를 학습시키면 무슨 일이 벌어지나"로 옮겨 봅니다. 30VNFoods에는 발견 강도 순으로 세 가지 균열이 있습니다.
균열 ① 한 접시, 두 개의 이름표
반지오 폴더의 Banh gio_427과 반베오 폴더의 Banh beo_434를 나란히 놓으면, 두 사진은 사실상 같은 한 장입니다. 같은 파란 꽃무늬 접시, 같은 바나나잎 받침, 오른쪽의 같은 빨간 소스 그릇, 왼쪽의 같은 나무 포크, 배경의 "VIETNAM" 표지판까지 일치합니다. 그런데 한 장은 반지오, 다른 한 장은 반베오라는 다른 정답을 달고 있습니다. 둘 중 하나는 틀린 라벨입니다.

So What: 분류기는 "반지오와 반베오를 가르는 경계"를 학습해야 하는데, 정작 같은 사진이 두 클래스에 동시에 들어 있으면 그 경계를 배울 수가 없습니다. 모델은 "반지오 = 반베오"라고 배우고, 두 클래스의 정확도가 함께 떨어집니다. 이런 노이즈 라벨은 한 쌍만 있어도 해당 클래스 학습을 흔들고, 여러 쌍이 숨어 있다면 데이터셋 전체의 신뢰도를 갉아먹습니다.
균열 ② 음식이 주인공이 아닌 사진들
L3에서 밀도가 가장 낮은 이미지들을 직접 열어 보면 공통점이 분명합니다. 라벨은 정확한데, 정작 음식이 화면의 주인공이 아닙니다. 61차원 특화 렌즈는 이런 맥락 오염(context contamination)에 L2보다 더 민감해서, 반미와 차오롱이 새로 저밀도 목록에 올라왔습니다.

분홍 옷 아기가 화면 70~80%. 반쯩은 손에 든 작은 소품.

손에 든 반미 뒤로 개와 콘크리트 바닥이 60%. 길거리 라이프스타일 샷.

잎으로 통째 싸여 끈으로 묶인 상태 + 타일 벽. 음식이 보이지 않음.
▲ L3 최저밀도 이상치 3종. 라벨은 맞지만 음식이 시각적 주체가 아닙니다.
So What: 이런 사진으로 학습하면 모델은 "아기 얼굴 → 반쯩", "개와 콘크리트 → 반미" 같은 엉뚱한 연관을 배웁니다. 정작 깨끗한 음식 사진의 정확도는 떨어지고, 사람이나 배경이 큰 사진을 해당 음식으로 오인합니다. 이런 이미지는 무조건 삭제할 대상이라기보다, 라벨 정의가 "음식 자체"인지 "음식이 등장하는 장면"인지부터 정해야 할 신호입니다.
균열 ③ AI에겐 늘 같은 한 장면이었던 반짱느엉
L3 고밀도 상위 5장은 전부 반짱느엉입니다. 밀도 값도 2.53~2.60으로 다른 클래스를 크게 앞섭니다. 실제 이미지를 열어 보면 이유가 분명합니다. 야간 포장마차의 숯불 그릴, 원형 라이스페이퍼, 집게, 칠리소스와 파 고명까지 거의 같은 구도가 반복됩니다. 일부 사진에는 같은 촬영자의 워터마크까지 보여, 소수의 노점·촬영자에서 집중 수집된 정황이 읽힙니다.
야간 그릴 + 원형 라이스페이퍼 + 집게
거의 같은 구도, 같은 조명, 같은 고명

조금 더 넓은 컷이지만 같은 템플릿
▲ 반짱느엉 L3 고밀도 상위 샘플. AI가 보는 반짱느엉은 사실상 한 장면입니다.
So What: 모델은 "야간 그릴 위 원형"이라는 한 가지 템플릿에만 과적합합니다. 낮에 찍었거나, 포장됐거나, 단면을 보인 반짱느엉은 같은 음식인데도 못 알아봅니다. 클래스 내 다양성(within-class variance)이 부족하면, 배달앱 자동 태깅이나 칼로리 추정 앱처럼 현실의 다양한 사진을 다뤄야 하는 서비스에서 성능이 급락합니다.
결론 — 작은 데이터셋의 큰 교훈
30VNFoods는 17,581장으로, 같은 음식 도메인의 한국 음식 데이터셋(15만 장 규모)에 비하면 1/8 정도의 작은 데이터셋입니다. 규모가 작으니 깨끗할 거라 기대하기 쉽고, 실제로 L1 무결성은 양호했습니다. 하지만 L2·L3 렌즈로 들여다보니 작은 데이터셋 특유의 균열이 더 선명하게 드러났습니다. 중복 라벨, 맥락 오염, 단일 출처 편중 — 모두 데이터가 적게 모일 때 한 장 한 장의 영향력이 커지기 때문에 두드러지는 문제들입니다.
| 항목 | 30VNFoods (#42, 본 글) | 한국 음식 (#59) |
|---|---|---|
| 클래스 수 | 30종 | 150종 |
| 총 이미지 | 17,581장 | 150,507장 |
| 클래스당 평균 | 586장 | 약 1,003장 |
| 출처 | Kaggle (베트남 거리·가정식) | AI Hub (한국 음식) |
| 대표 균열 | 중복 라벨 · 맥락 오염 · 단일 출처 | #59 진단기 참고 |
※ #42는 공개 API로 종합 점수가 제공되지 않아 점수 대 점수 비교는 하지 않습니다. 위 표는 규모·구조 비교입니다. DataClinic 데이터셋 전반의 점수 분포는 데이터셋 통계 스토리에서 볼 수 있습니다.
AI-Ready 데이터의 관점에서 30VNFoods의 처방은 분명합니다. 먼저 클래스 간 중복 이미지를 임베딩 유사도로 찾아 제거하고(반지오 ↔ 반베오 같은 쌍의 라벨을 바로잡고), 음식이 주인공이 아닌 사진은 라벨 정의를 다시 정해 분류하거나 걸러내며, 반짱느엉처럼 한 장면에 쏠린 클래스는 다른 시간대·구도·출처의 사진으로 다양성을 보강해야 합니다.
숫자가 많다고 좋은 데이터가 아니고, 적다고 나쁜 데이터도 아닙니다. 중요한 건 한 장 한 장이 모델에게 무엇을 가르치고 있는가입니다. DataClinic의 L1·L2·L3 렌즈는 그 "무엇"을 눈으로 볼 수 있게 만들어 줍니다.
참고자료
- 1.quandang. (2023). Vietnamese Foods — 30 Vietnamese Food Categories Image Dataset (30VNFoods). Kaggle. kaggle.com/datasets/quandang/vietnamese-foods
- 2.DataClinic. (2025). DataClinic Diagnosis Report #42: 30VNFoods. DataClinic. dataclinic.ai/report/42 — 이 글의 모든 시각화(콜라주·평균 이미지·밀도 플롯·PCA)의 원천.