한국 음식 이야기 — AI가 발견한 국물 문화
"국물도 없다(Guk-mul-do eop-da)" — 직역하면 "국물도 없다"이지만 실제 뜻은 "아무것도 없다", "한 푼도 없다"는 한국 관용구입니다. 한국 문화에서 국물(broth)은 가장 기본적으로 나눠야 할 것, 식사의 최소 단위라는 인식에서 나온 표현입니다. 이 관용구 하나가 한식의 본질을 담고 있습니다.
전통 한국 식탁은 밥(bap) + 국(guk) + 반찬(banchan)의 삼각형 구조로 이루어집니다. 갈비탕, 삼계탕, 된장찌개, 미역국… 아무리 간소한 식사도 국 한 그릇은 갖추는 것이 한국의 식사 예의입니다. 한식 데이터셋 150개 클래스 중 상당수가 국물 음식인 것은 우연이 아닙니다. 그리고 이 사실은, 우리가 나중에 보게 될 것처럼, AI에도 고스란히 반영됩니다.
K-팝과 K-드라마의 세계적 확산(한류, Hallyu)은 한국 음식에 대한 관심을 폭발적으로 키웠습니다. 드라마 속 삼겹살을 구우며 소주를 기울이는 장면, 새벽에 라면 한 그릇을 끓여 먹는 장면은 이제 전 세계 팬들에게도 익숙합니다. 넷플릭스 드라마 한 편이 특정 한국 음식의 전 세계 검색량을 수십 배 끌어올리는 시대, 음식 인식 AI에서 한식 카테고리는 더 이상 선택이 아닙니다.
🌍 한국 음식이 처음인 분들을 위한 안내
- • 반찬(Banchan) — 메인 요리 옆에 놓이는 작은 사이드 디시들. 한 끼 식사에 3~10가지. 깻잎장아찌처럼 독립 접시에 담기면 낯설게 보이는 이유입니다.
- • 국물 문화(Guk-mul Culture) — 국·탕·찌개는 한국 식사의 필수 요소. 범용 AI가 한식을 두 덩어리로 나누는 이유가 바로 이것입니다.
- • 계절 음식(Seasonal Foods) — 송편은 추석(한국 추수감사절)에만 먹는 음식. 반달 모양·파스텔 색상의 정형화된 사진이 반복되어 AI에게 '가장 전형적'이 됩니다.
- • 조리 상태(Cooking State) — 삼겹살은 날것(분홍), 굽는 중(연기), 완성(갈색)이 모두 동일 클래스. 가장 많은 이상치가 나오는 구조적 이유입니다.
🤖 AI 연구자를 위한 관점: 왜 한식 데이터는 흥미로운가
한식 이미지 인식은 컴퓨터 비전의 여러 어려운 문제를 한 데이터셋에 압축한 것과 같습니다.
- Fine-grained 분류의 극한 — 물냉면과 비빔냉면은 같은 냉면이지만 국물 유무로 외관이 완전히 달라집니다. 된장찌개와 김치찌개는 비슷한 그릇 구도이지만 색상이 다릅니다. ImageNet 수준의 범용 모델만으로는 부족한 이유입니다.
- 클래스 내 분산 불균형 — 송편(매우 낮은 내부 분산) vs. 김밥(매우 높은 내부 분산)처럼, 클래스당 이미지 수가 거의 같아도 학습 난이도는 극단적으로 다릅니다. 균형 잡힌 데이터셋이 반드시 균형 잡힌 학습을 보장하지 않는다는 교훈입니다.
- 도메인 특화의 효과 — 범용 렌즈(L2)에서 2개 클러스터가 도메인 특화 렌즈(L3)에서 1개로 통합됩니다. 한식 전문 백본이 만드는 피처 공간은 근본적으로 다른 구조를 가집니다.
Executive Summary
본 포스팅은 페블러스 데이터클리닉을 이용한 한국 이미지(음식) 데이터셋의 품질 진단보고서 #59에 대한 핵심 인사이트를 담고 있습니다.
한국 이미지(음식) 데이터셋은 갈비탕부터 후라이드치킨까지 150개 클래스, 총 150,507장의 이미지로 구성된 대규모 한식 데이터셋입니다. DataClinic 종합 진단 결과 품질점수 71점(보통)을 기록했습니다. 클래스 균형 측면에서는 최소 992장~최대 1,125장으로 표준편차 16.8에 불과한 교과서적 분포를 보여줍니다.
L2(특징 공간 분석) Wolfram ImageIdentify Net V2(1,280차원)에서는 범용 AI가 한식을 국물 있는 음식군과 건식 음식군이라는 두 클러스터로 구분하는 패턴이 발견되었습니다. 반면 L3(도메인 최적화 분석, 129차원)에서는 이 두 클러스터가 하나의 한식 공간으로 통합됩니다.
가장 '전형적인' 음식은 송편이었으며, 가장 이질적인 이미지는 김밥에서 발견되었습니다. 시각적 다양성이 낮은 클래스를 대상으로 Data Diet(중복 제거)가 권장됩니다.
데이터셋 소개 — 150가지 한식의 세계
한국 이미지(음식) 데이터셋은 한국 전통 음식부터 현대 분식까지 150개 클래스, 총 150,507장의 이미지로 구성된 대규모 한식 비전 데이터셋입니다. AIHub에서 제공하며 상업적 이용도 가능하여 AI 기반 음식 인식 서비스 개발에 즉시 활용할 수 있습니다.
150개 클래스는 한국 음식 문화의 풍경을 고스란히 담고 있습니다. 아래는 주요 카테고리별 분류입니다:
육개장, 된장찌개, 무국
시래기국, 북어국 등
짜장면, 짬뽕
콩나물국밥 등
갈치구이, 고등어구이
닭갈비 등
메추리알장조림, 가지볶음
간장게장 등
열무김치, 깍두기
배추김치 등
만두, 라볶이
후라이드치킨 등
한과, 약식
인절미 등
홍어, 꼬막
전복구이 등
음식 이름 하나하나가 한국 음식 문화의 맥락을 가집니다. 멍게(우렁쉥이)는 특유의 비린향과 주홍색 때문에 AI 모델이 인식하기 어려운 음식 중 하나이며, 과메기는 포항 지역 겨울 제철 음식으로 시각적으로는 일반 생선포와 구분이 쉽지 않습니다. 후라이드치킨은 한국식으로 재해석된 외래 음식입니다. 이런 '도메인 지식이 필요한 음식들'이 데이터 품질에 어떤 영향을 미치는지가 이번 진단의 핵심 관전 포인트입니다.






▲ 클래스 평균 이미지 — 각 클래스의 약 1,000장을 픽셀 단위로 평균한 결과. 선명할수록 시각적 일관성이 높습니다. 경단·꿀떡은 선명, 김밥은 상대적으로 흐릿한 점을 주목하세요.
종합 진단 결과 — 품질점수 71점(보통)
종합 71점은 '보통' 등급으로, 대규모 공개 데이터셋 중에서는 상위권에 해당합니다. 클래스 균형이라는 근본 체력은 탁월하지만, 일부 클래스에서의 시각적 다양성 부족이 점수를 제한합니다. 상업적 이용이 허가되어 있어 실전 AI 개발에 바로 투입할 수 있는 수준의 데이터셋입니다.
| 진단 항목 | 결과 | 비고 |
|---|---|---|
| 클래스 균형 | ✅ 좋음 | 표준편차 16.8 (교과서적) |
| 결측치 | ✅ 좋음 | 0.07% (103장/150,610장) |
| 채널 구성 | ✅ 좋음 | 99.42% RGB |
| 이미지 해상도 | ⚠️ 보통 | 121×91px ~ 6,048×4,032px |
| 클래스 내 다양성 | ⚠️ 보통 | 송편·물냉면 등 중복 밀집 |
| 상업적 이용 | ✅ 허가 | AIHub 출처 |
Level 1: 기초 품질 점검 — 픽셀 수준의 체력 검사
Level 1은 이미지 무결성, 결측치, 클래스 균형, 픽셀 통계를 검사합니다. DataClinic이 원본 데이터를 받아 가장 먼저 실행하는 기초 체력 검사입니다.
✅ 클래스 균형: 교과서적 수준
150개 클래스의 이미지 수는 최소 992장 ~ 최대 1,125장으로, 표준편차가 단 16.8에 불과합니다. 이는 인위적으로 균형을 맞춘 수준의 분포입니다. 비교 대상으로, WikiArt 데이터셋의 클래스 균형 표준편차는 수천에 달합니다. AI 모델 학습 시 특정 음식에 편향될 위험이 극히 낮다는 의미입니다.
단, 숫자의 균형이 학습의 균형을 보장하지는 않습니다. 송편 1,003장과 김밥 1,003장은 같은 수지만, 송편은 거의 모든 이미지가 비슷하고 김밥은 촬영 각도마다 전혀 다릅니다. 클래스 내 다양성(intra-class variance)은 L2/L3에서 더 자세히 드러납니다.
⚠️ 이미지 해상도: 광범위한 스펙트럼
이미지 크기는 최소 121×91px에서 최대 6,048×4,032px까지 매우 넓게 분포합니다. 스마트폰 스냅샷부터 DSLR 전문 촬영까지 다양한 출처에서 수집된 흔적입니다. AI 학습을 위해서는 입력 해상도를 표준화하는 전처리가 필수입니다. 최소 해상도인 121×91px 이미지는 ResNet-50(224×224px 입력 요구) 등 표준 모델에서 업스케일링이 필요합니다.
✅ 채널 구성: 안정적
전체 이미지의 99.42%가 표준 RGB 3채널입니다. 0.33%는 알파 채널 포함 RGBa, 0.25%는 기타 포맷으로, 전처리 시 알파 채널 제거 또는 RGB 변환이 필요한 이미지는 전체의 0.58%에 불과합니다.
✅ 결측치: 무시 가능한 수준
원본 150,610장 중 103장(0.07%)이 누락되어 150,507장이 실제 진단에 사용됐습니다. 0.07%는 대규모 웹 크롤링 기반 데이터셋 기준으로 매우 낮은 수준입니다.
🔍 평균 이미지가 말해주는 것
Level 2: 범용 AI의 눈으로 본 한식 — 두 개의 세계
Level 2는 Wolfram ImageIdentify Net V2(1,280차원 특징 벡터)로 전체 데이터셋의 특징을 추출하고 분포를 분석합니다. 이 신경망은 음식 도메인에 특화되지 않은 범용 이미지 인식 모델입니다. 즉, 한식의 맥락을 모르는 외국인의 시선으로 사진을 바라보는 것과 같습니다.
🌊 두 개의 클러스터: 국물 vs. 건식
PCA와 밀도 지형도 분석 결과, 범용 렌즈에서 한식은 두 개의 뚜렷한 클러스터로 나뉩니다. 도메인 지식으로 해석하면:
이것이 바로 한식 특유의 '국물 문화'가 이미지 데이터에도 고스란히 반영된다는 증거입니다. 범용 AI가 레시피나 재료를 알지 못해도, 시각적 구조만으로 '국물 있음/없음'을 자연스럽게 학습합니다.
아래 PCA 시각화에서 클래스별 평균 특징의 분포를 확인할 수 있습니다:
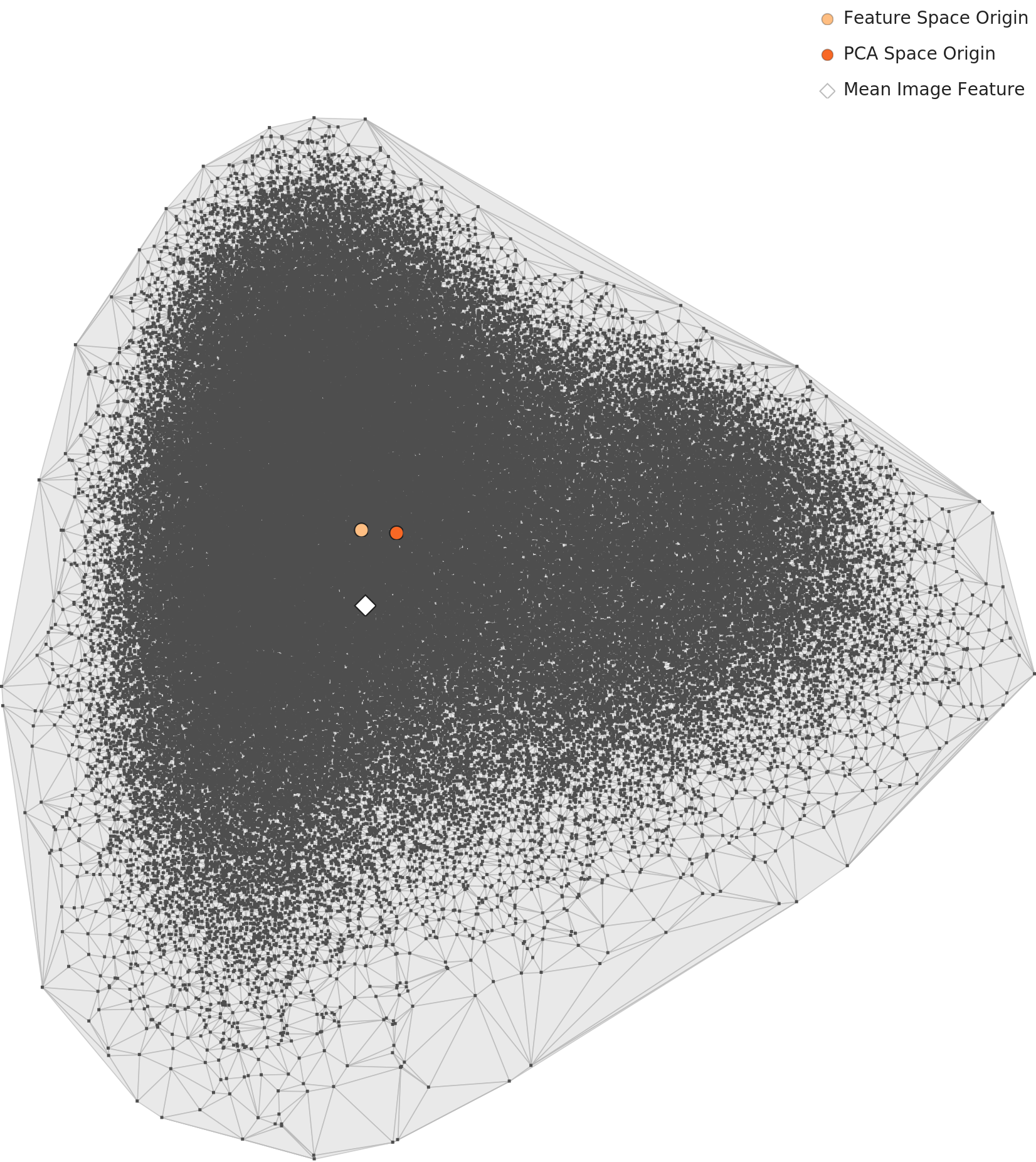
📊 분포: 종형(Bell-shaped) — 양호
전체 밀도 분포는 종형 곡선을 유지합니다. 대부분의 이미지가 특징 공간 중심부에 밀집하고, 양 극단에 소수 이상치가 분포합니다. 정규 분포에 가까운 건강한 데이터 구조입니다.

🔬 클래스별 밀도 비교 — 6가지 음식의 초상
클래스별 밀도 분포를 비교하면 음식마다 극적으로 다른 패턴이 나타납니다. 아래 6개 클래스는 고밀도(시각적으로 일관된)부터 저밀도(다양한)까지의 스펙트럼을 보여줍니다:
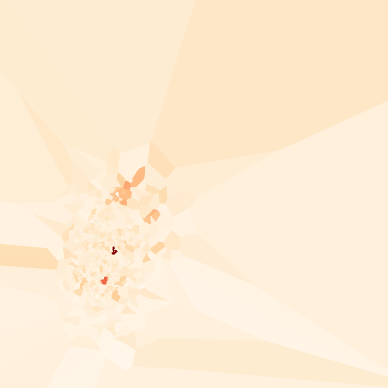
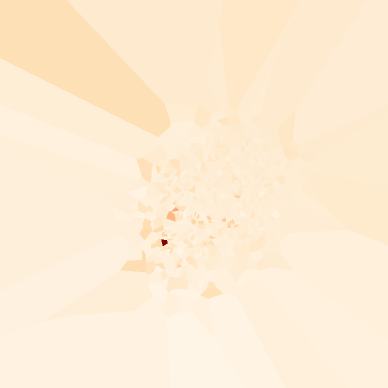




▲ L2 클래스별 밀도 분포. 클러스터가 촘촘하고 밀도가 높을수록 시각적으로 일관된 음식, 분산이 넓고 낮을수록 촬영 다양성이 큰 음식입니다.
Level 3: 한식 전문 렌즈 — 두 세계가 하나로
Level 3는 Wolfram ImageIdentify Net V2를 기반으로 한식 데이터셋에 특화된 129차원 렌즈를 적용합니다. 범용 시선이 아닌, 한식을 이해하는 전문가의 시선으로 데이터를 다시 바라봅니다.
🎯 클러스터 통합: 두 개 → 하나
가장 주목할 변화는 Level 2에서 보였던 두 클러스터가 하나로 합쳐진다는 점입니다. 범용 렌즈가 '국물 유무'라는 시각적 구조에 반응했다면, 도메인 특화 렌즈는 '한식'이라는 공통 정체성을 우선 인식합니다.
이는 실제 AI 서비스 개발에 중요한 시사점을 줍니다. 한식 인식 모델을 만들 때 범용 백본을 그대로 쓰면 국물 음식과 건식 음식을 서로 다른 분야처럼 취급할 수 있지만, 한식에 특화된 피처 추출기를 사용하면 더 통합된 인식 공간이 형성됩니다.
L3 PCA 시각화에서 통합된 분포를 확인할 수 있습니다:
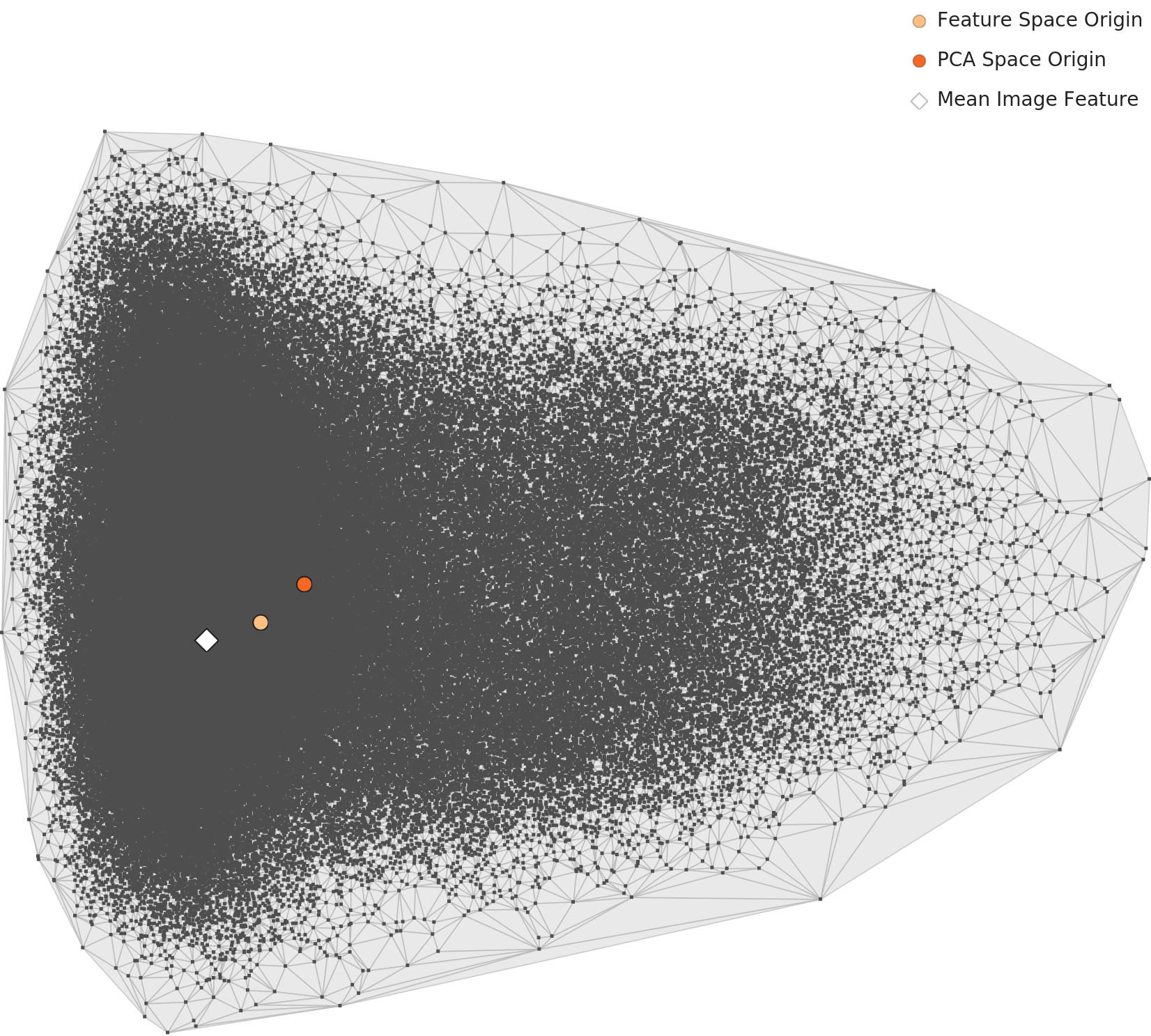
📈 분포: 여전히 종형 — 안정적
도메인 특화 렌즈에서도 전체 분포는 종형을 유지합니다. 클러스터가 통합되면서도 분포의 건강한 형태가 유지된 것은 도메인 특화가 단순 압축이 아닌 의미 있는 표현 학습임을 보여줍니다.

🔬 L3 클래스별 밀도 — 도메인 렌즈가 바꾼 것들
L2에서 L3로 넘어가면서 클래스별 분포가 어떻게 바뀌었을까요? 주목할 변화를 6개 클래스로 확인합니다:






▲ L3 클래스별 밀도 분포. L2와 비교해 전체 클러스터는 통합되었으나, 개별 클래스의 내부 분산 패턴은 음식의 고유한 특성에 따라 유지됩니다.
이상치 분석 — 왜 송편이 가장 '전형적'인가
DataClinic은 밀도 기반 이상치 분석을 통해 데이터셋에서 가장 전형적인 샘플(고밀도)과 가장 이례적인 샘플(저밀도)을 식별합니다.
🏆 고밀도 샘플 — AI가 인식하는 '전형적 한식'
고밀도 샘플, 즉 특징 공간에서 가장 중심에 위치한 이미지들에는 송편과 물냉면이 주를 이룹니다. 이는 우연이 아닙니다.
송편은 한국의 추석(Chuseok, 음력 8월 15일) 명절 음식으로, 쌀가루 반죽 안에 깨·팥·밤을 넣어 반달 모양으로 빚어 솔잎 위에 쪄서 만듭니다. 시각적으로 매우 일관된 음식입니다:
- 반달 모양의 동일한 실루엣
- 흰색·분홍색·초록색의 정형화된 색상 팔레트
- 접시 위에 가지런히 놓인 정형화된 구도
- 배경이 단순하고 조명이 균일한 경우가 많음
AI 입장에서 송편은 "예측 가능한" 이미지입니다. 거의 모든 송편 사진이 비슷한 특징 벡터를 가지기 때문에 밀도가 높게 측정됩니다. 역설적으로 이 '전형성'이 Data Diet 대상 1순위이기도 합니다.




⚠️ 저밀도 샘플 — 이상치의 정체
저밀도 이상치로는 김밥, 순대, 깻잎장아찌, 삼겹살이 상위권을 차지합니다. 이들의 공통점은 촬영 각도, 플레이팅 방식, 조리 상태가 제각각이라는 것입니다:
- 김밥 — 단면 노출(단무지·계란 구성 노출) vs. 옆면(원통형 외관). 외국인들이 종종 일본 마키롤과 혼동하지만, 김밥은 참기름을 바른 밥과 한국식 재료를 사용하는 전혀 다른 음식입니다. 이 시각적 다양성이 낮은 밀도의 원인입니다.
- 삼겹살 — 구워지기 전 분홍빛 vs. 구워진 후 갈색빛. 색상이 극단적으로 달라집니다.
- 깻잎장아찌 — 접시에 단독으로 담긴 형태 vs. 쌈으로 활용된 형태. 전형적인 반찬의 딜레마.
- 순대 — 통째로 vs. 잘린 단면 노출 형태.




↔️ 가장 다른 쌍: 한과 vs. 김밥
유사도 분석에서 특징 공간상 가장 거리가 먼 이미지 쌍이 발견되었습니다. 한과와 김밥의 조합이 대표적입니다. 한과는 황금색·갈색의 건조하고 정형화된 과자 형태인 반면, 김밥은 흑백 원통형에 알록달록한 단면으로 — 색상, 질감, 형태 모든 면에서 대극적입니다.
한과(Korean confectionery)는 쌀·콩·꿀로 만든 전통 과자로, 혼례·제사 등 의례에 빠지지 않는 음식입니다. 외관이 정갈하고 형태가 정형화되어 있어 AI에게는 고밀도 음식입니다. 반면 김밥은 어떤 각도로 찍느냐에 따라 완전히 다른 이미지가 됩니다.

한과 (Korean confectionery)

김밥 (Gimbap)
▲ 특징 공간에서 가장 멀리 떨어진 쌍. 색상·질감·형태 모든 면에서 대극적입니다.
💡 이상치 분석의 실전 활용
개선 제안 — Data Diet 처방
DataClinic은 이 데이터셋에 Data Diet(데이터 다이어트)를 권장합니다. 품질점수 71점(보통)은 클래스 균형의 교과서적 품질에도 불구하고, 특정 클래스의 시각적 다양성 부족이 발목을 잡고 있기 때문입니다.
🥗 Data Diet란?
Data Diet는 단순히 데이터를 줄이는 것이 아닙니다. 고밀도 영역에 밀집한 거의 동일한 이미지를 식별하고 중복을 제거하여 모델이 더 다양한 패턴을 학습할 수 있도록 돕습니다.
- 송편 — 반달 모양·파스텔 색상의 이미지가 밀집. 빚는 장면, 러스틱 스타일, 다양한 조명 조건의 이미지를 보강하면 모델이 실제 환경에서 더 강건하게 작동합니다.
- 물냉면 — 그릇 중앙 구도가 반복적. 다양한 앵글과 플레이팅 스타일 보강을 권장합니다.
- 고밀도 클래스 전반 — 중복 이미지 제거 후 식당·가정·길거리 등 다양한 촬영 환경 이미지로 대체하는 것이 이상적입니다.
💊 Data Bulkup(데이터 보강)은 필요없나요?
현재 클래스 균형이 매우 훌륭하기 때문에, 소수 클래스 보강보다는 Diet가 더 시급합니다. 단, 멍게·과메기·젓갈 같은 비전형적 해산물 클래스는 시각적 다양성이 자연적으로 낮으므로, 다양한 촬영 조건의 이미지를 추가하면 모델 강건성이 크게 향상될 수 있습니다.
🎯 핵심 요약
✅ 클래스 균형: 교과서적 (표준편차 16.8)
✅ 결측치: 0.07% 무시 가능
✅ 채널 구성: 99.42% RGB
⚠️ 해상도 범위: 전처리 표준화 필요
⚠️ 고밀도 클래스 중복: Data Diet 권장
📈 예상 개선 점수: Data Diet 적용 시 71 → 80점대 상승 가능
전체 진단 결과와 150개 클래스별 상세 분석은 DataClinic 리포트 #59에서 직접 확인하실 수 있습니다.
결론 — 150가지 한식, 데이터로 본 세 가지 발견
한국 이미지(음식) 데이터셋 #59 진단에서 우리는 세 가지 핵심 발견을 얻었습니다.
첫째, 국물 문화는 데이터에도 나타난다. 범용 AI(Wolfram ImageIdentify Net V2)가 한식을 학습했을 때 자연스럽게 국물 음식군과 건식 음식군이라는 두 클러스터를 형성했습니다. 레시피나 재료 정보 없이, 순수한 시각적 패턴만으로 한국 음식 문화의 본질적 구조를 포착한 것입니다. 한식을 한 번도 먹어본 적 없는 AI가 "한식에는 항상 국물이 있다"는 사실을 스스로 발견했습니다.
둘째, 도메인 특화는 단절이 아닌 통합을 만든다. 한식 특화 렌즈(L3, 129차원)를 적용했을 때 두 클러스터가 하나로 통합되었습니다. 이는 도메인 지식이 데이터를 어떻게 재해석하는지를 잘 보여줍니다. 한식을 아는 렌즈는 갈비탕과 삼겹살의 시각적 차이보다 둘이 모두 '한식'이라는 공통성을 더 중요하게 봅니다.
셋째, 균형 잡힌 수가 균형 잡힌 학습을 보장하지 않는다. 표준편차 16.8이라는 교과서적 클래스 균형에도 불구하고, 송편(내부 분산 극히 낮음)과 김밥(내부 분산 극히 높음) 사이의 학습 난이도 차이는 엄청납니다. Data Diet로 고밀도 중복을 제거하면 71점에서 80점대로의 점수 향상이 예상됩니다.
📊 진단 결과 한눈에
| 레벨 | 핵심 발견 | 시사점 |
|---|---|---|
| L1 | 클래스 균형 표준편차 16.8 | 편향 학습 위험 극히 낮음 |
| L2 | 범용 AI가 국물/건식 2클러스터 형성 | 범용 백본 사용 시 국물-비국물 혼동 가능 |
| L3 | 한식 특화 렌즈에서 클러스터 통합 | 도메인 특화 피처 추출기 도입 효과 확실 |
| 이상치 | 송편 고밀도, 김밥 저밀도 | Data Diet 타겟: 고밀도 클래스 중복 제거 |
더 많은 데이터셋 진단 사례와 DataClinic 활용법은 dataclinic.ai에서 확인하세요.