(주)페블러스 데이터 커뮤니케이션팀 · English
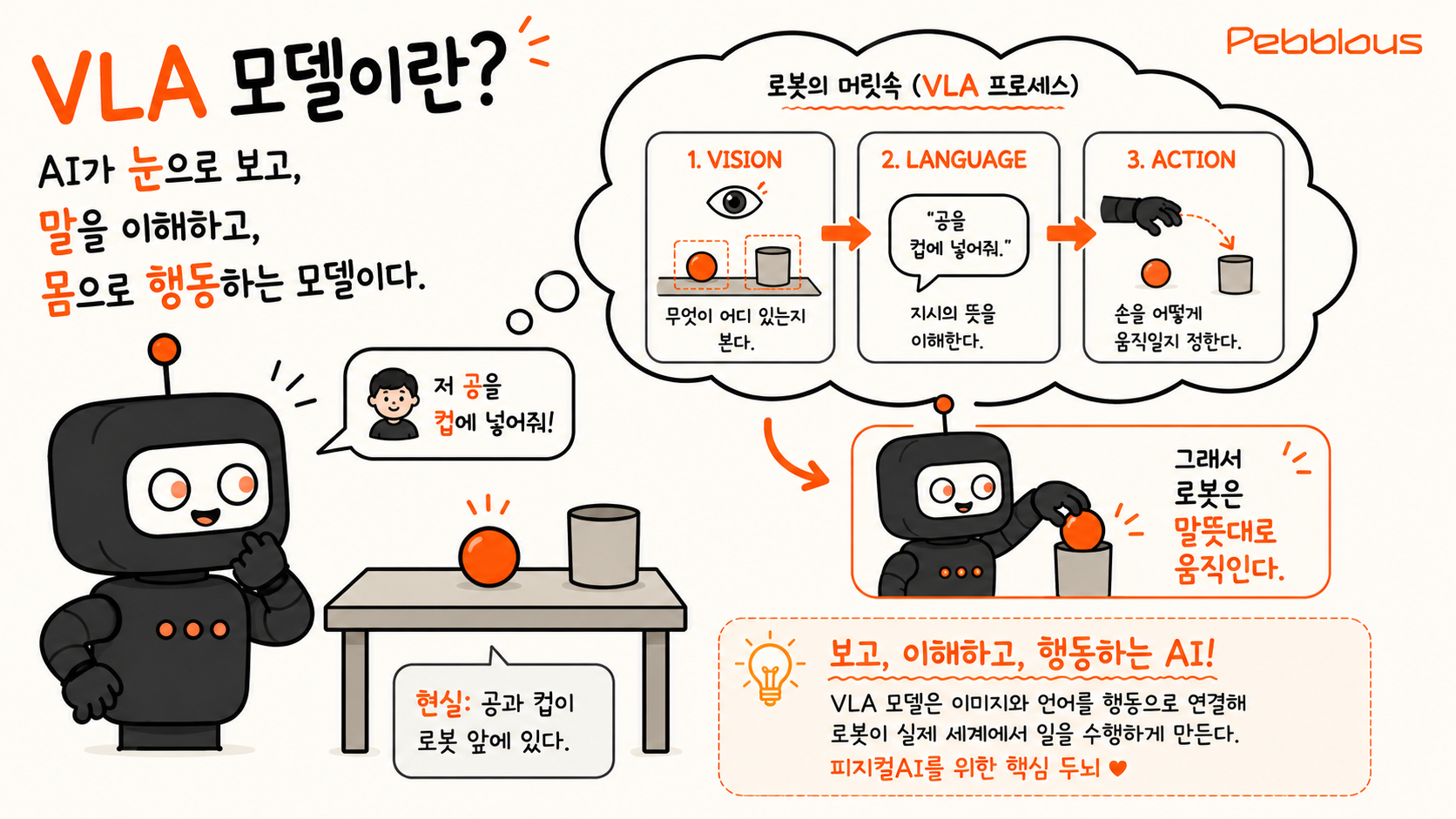
VLA(Vision-Language-Action) 모델은 AI가 카메라로 보고, 사람의 말을 이해하고, 로봇의 몸으로 행동하기까지를 하나로 잇는 모델입니다. "저 공을 컵에 넣어줘"라는 한마디를 듣고, 책상 위 공과 컵이 어디에 있는지 눈으로 파악한 뒤, 팔을 어떻게 움직일지 스스로 정해 실제로 집어 넣습니다. 글만 다루던 LLM, 보면서 말까지 하던 VLM에서 한 걸음 더 나아가, 마침내 몸을 갖게 된 AI인 셈입니다.
VLA가 중요한 이유는 그것이 피지컬 AI(Physical AI)의 두뇌이기 때문입니다. 공장의 로봇 팔, 물류 창고의 자율 로봇, 가정용 휴머노이드 — 디지털 세계에 머물던 AI가 물리 세계로 나오는 순간 필요한 것이 바로 이미지와 언어를 행동으로 번역하는 능력입니다. 그래서 NVIDIA(GR00T), Google DeepMind(Gemini Robotics), Physical Intelligence(π) 같은 팀들이 저마다 다른 구조의 '로봇 뇌'를 만들며 경쟁하고 있습니다.
페블러스가 VLA를 주목하는 자리는 분명합니다 — 데이터입니다. VLA를 학습시키려면 로봇이 보고·움직인 방대한 행동 데이터가 필요하지만, 현실에서 그런 데이터를 모으는 일은 느리고 비쌉니다. 그래서 3DGS·시뮬레이션으로 합성하는 전략, 데이터의 품질을 보증하는 문제, 그리고 "정말 VLA가 답인가"라는 비판(뉴로심볼릭·월드 모델)까지가 모두 한 묶음으로 얽힙니다. 이 허브는 그 흐름을 입문에서 심화로 따라가도록, 페블러스가 VLA를 다룬 글을 한곳에 모았습니다.
시리즈 가이드
여기서 시작하세요. 글만 아는 LLM, 보고 말하는 VLM, 그리고 보고·이해하고·행동하는 VLA가 어떻게 다른지 — 개념을 처음부터 차근히 풀어 주는 입문 글입니다.
큰 그림을 잡고 싶다면 이 글로. NVIDIA·Google·Physical Intelligence가 같은 'VLA'라는 목표를 두고 서로 다른 아키텍처로 푸는 방식을 나란히 비교합니다.
VLA의 진짜 병목은 데이터입니다. 현실에서 모으기 어려운 로봇 행동 데이터를 3D 가우시안 스플래팅과 시뮬레이션으로 합성하는 전략을 깊게 들여다봅니다 — 페블러스의 핵심 관심사.
VLA가 정답일까? 규칙을 아는 뉴로심볼릭 로봇이 훨씬 적은 에너지로 더 정확하게 움직인 사례를 통해, VLA 접근의 강점과 한계를 비판적으로 짚습니다.
그다음은? 보는 것과 세계를 진짜로 이해하는 것은 다릅니다. VLA가 부딪힌 한계를 짚고, 월드 모델이 왜 다음 단계로 떠오르는지 설명합니다.