Pebblous Data Communication Team · 한국어
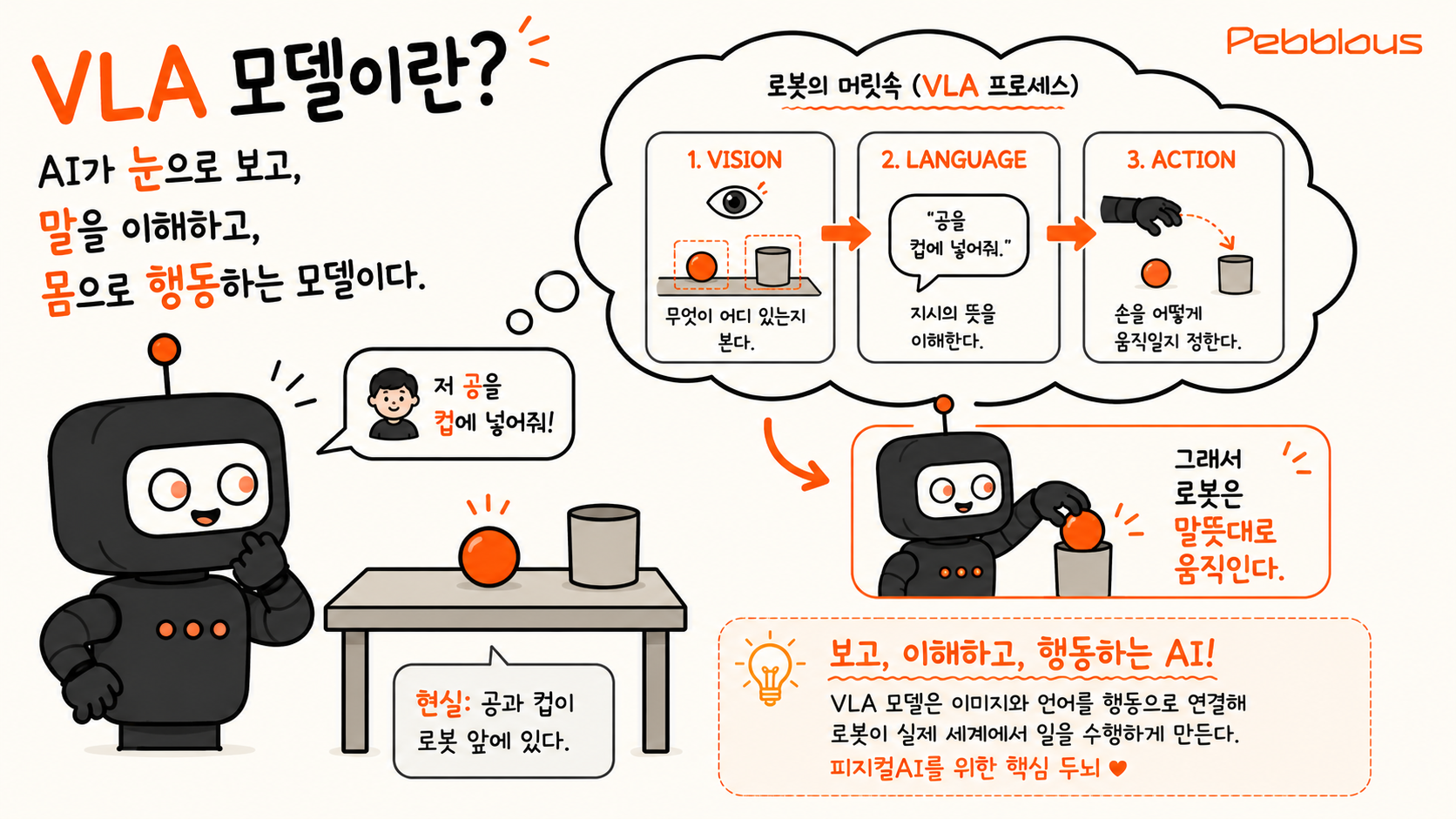
A VLA (Vision-Language-Action) model connects, in a single pipeline, an AI's ability to see through a camera, understand human language, and act with a robot's body. Told "put that ball in the cup," it figures out where the ball and cup are on the table, decides how to move its arm, and actually does it. Moving beyond LLMs (which handle only text) and VLMs (which see and talk), VLA is, in effect, AI that has finally gained a body.
VLA matters because it is the brain of Physical AI. Robot arms on factory floors, autonomous robots in warehouses, household humanoids — the moment AI steps out of the digital world into the physical one, it needs exactly this ability to translate images and language into action. That's why teams like NVIDIA (GR00T), Google DeepMind (Gemini Robotics), and Physical Intelligence (π) are competing to build "robot brains" with very different architectures.
Pebblous's angle on VLA is clear — data. Training a VLA requires vast amounts of robot behavior data captured from seeing and moving, yet collecting it in the real world is slow and expensive. So strategies to synthesize data with 3DGS and simulation, the problem of guaranteeing that data's quality, and even the critiques of whether VLA is the right answer at all (neuro-symbolic, world models) are all tied together. This hub gathers Pebblous's articles on VLA so you can follow that thread from introduction to depth.
Series Guide
Start here. How an LLM (text only), a VLM (seeing and talking), and a VLA (seeing, understanding, and acting) differ — a from-scratch introduction to the concept.
For the big picture. A side-by-side comparison of how NVIDIA, Google, and Physical Intelligence solve the same VLA goal with different architectures.
The real bottleneck for VLA is data. A deep look at synthesizing hard-to-collect robot behavior data with 3D Gaussian Splatting and simulation — Pebblous's core concern.
Is VLA the answer? Through a case where a rule-aware neuro-symbolic robot moved more accurately on a fraction of the energy, we examine VLA's strengths and limits critically.
What comes next? Seeing is not the same as truly understanding the world. We trace the limits VLA ran into and why world models are emerging as the next step.