2026.03 · (주)페블러스 데이터 커뮤니케이션팀
읽는 시간: ~15분 · English
Executive Summary
본 포스팅은 페블러스 데이터클리닉을 이용한 한국 이미지(음식) 데이터셋의 품질 진단보고서 #59에 대한 핵심 인사이트를 담고 있습니다.
한국 이미지(음식) 데이터셋은 갈비탕부터 후라이드치킨까지 150개 클래스, 총 150,507장의 이미지로 구성된 대규모 한식 데이터셋입니다. L1(기초 품질) DataClinic 종합 진단 결과 품질점수 71점(보통)을 기록했습니다. 클래스 균형 측면에서는 최소 992장~최대 1,125장으로 표준편차 16.8에 불과한 교과서적 분포를 보여줍니다.
L2(특징 공간 분석) Wolfram ImageIdentify Net V2(1,280차원)에서는 범용 AI가 한식을 국물 있는 음식군과 건식 음식군이라는 두 클러스터로 구분하는 흥미로운 패턴이 발견되었습니다. 반면 L3(도메인 최적화 분석, 129차원 한식 특화)에서는 이 두 클러스터가 하나의 한식 공간으로 통합됩니다.
가장 '전형적인' 음식은 송편이었으며, 가장 이질적인 이미지는 김밥에서 발견되었습니다. 시각적 다양성이 낮은 클래스를 대상으로 Data Diet(중복 제거)가 권장됩니다.
데이터셋 소개 — 150가지 한식의 세계
한국 이미지(음식) 데이터셋은 AI Hub에서 공개된 한국 전통 음식부터 현대 분식까지 150개 클래스, 총 150,507장의 이미지로 구성된 대규모 한식 비전 데이터셋입니다. 상업적 이용도 가능하여 AI 기반 음식 인식 서비스 개발에 즉시 활용할 수 있습니다.
150개 클래스는 한국 음식 문화의 풍경을 고스란히 담고 있습니다:
- 국·탕·찌개류 — 갈비탕, 물냉면, 삼계탕, 추어탕, 육개장, 닭계장, 무국
- 구이류 — 갈비구이, 삼겹살, 갈치구이, 고등어구이
- 조림·볶음류 — 가지볶음, 깻잎장아찌, 간장게장, 갈비찜
- 분식류 — 김밥, 라면, 만두, 떡볶이, 순대
- 전통 떡류 — 송편, 경단, 꿀떡, 한과
- 해산물류 — 멍게, 과메기, 젓갈
- 기타 — 후라이드치킨(한국식), 짜장면, 짬뽕 등 외래 음식의 한국화 버전도 포함
음식 이름 하나하나가 한국 음식 문화의 맥락을 가집니다. 멍게(우렁쉥이)는 특유의 비린향과 주홍색 때문에 AI 모델이 인식하기 어려운 음식 중 하나이며, 과메기는 포항 지역 겨울 제철 음식으로 시각적으로는 일반 생선포와 구분이 쉽지 않습니다. 이런 '도메인 지식이 필요한 음식들'이 데이터 품질에 어떤 영향을 미치는지가 이번 진단의 핵심입니다.
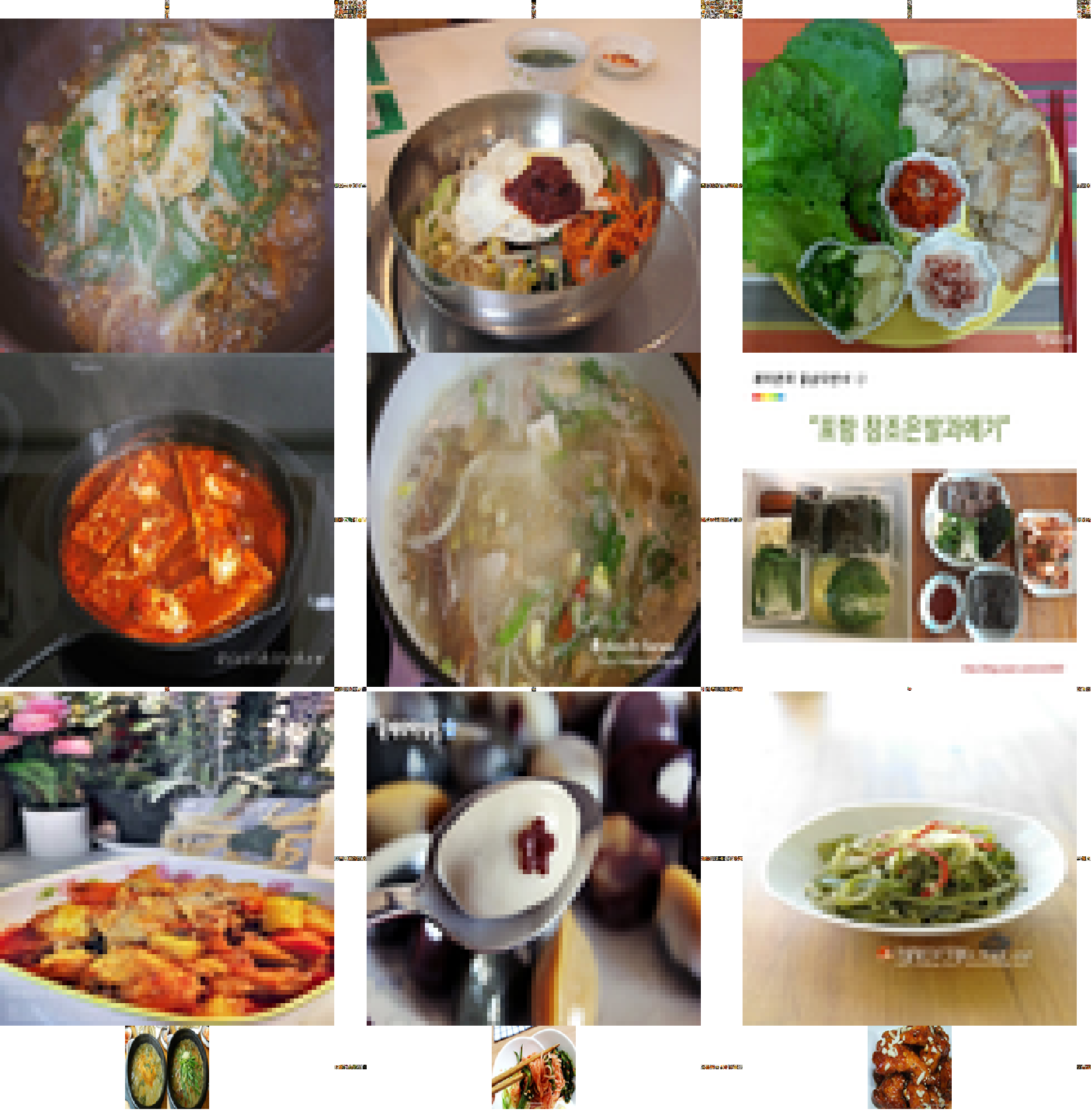
한국 음식 데이터셋 — 150종 한식 대표 이미지 콜라주 (DataClinic L1 분석)






▲ 클래스 평균 이미지 — 각 클래스의 1,000여 장을 픽셀 단위로 평균한 결과. 시각적 일관성이 높을수록 선명하게 나타납니다.