2026.03 · Pebblous Data Communication Team
Reading time: ~15 min · 한국어
Executive Summary
This post presents key insights from Quality Diagnosis Report #59 of the Korean Image (Food) dataset, generated using Pebblous DataClinic.
The Korean Image (Food) dataset is a large-scale Korean cuisine dataset comprising 150 classes and 150,507 images, ranging from Galbitang(갈비탕, short rib soup) to Korean fried chicken. L1 (Basic Quality) DataClinic overall diagnosis scored a quality score of 71 (Fair). In terms of class balance, it shows a textbook-level distribution with a minimum of 992 and maximum of 1,125 images per class, with a standard deviation of just 16.8.
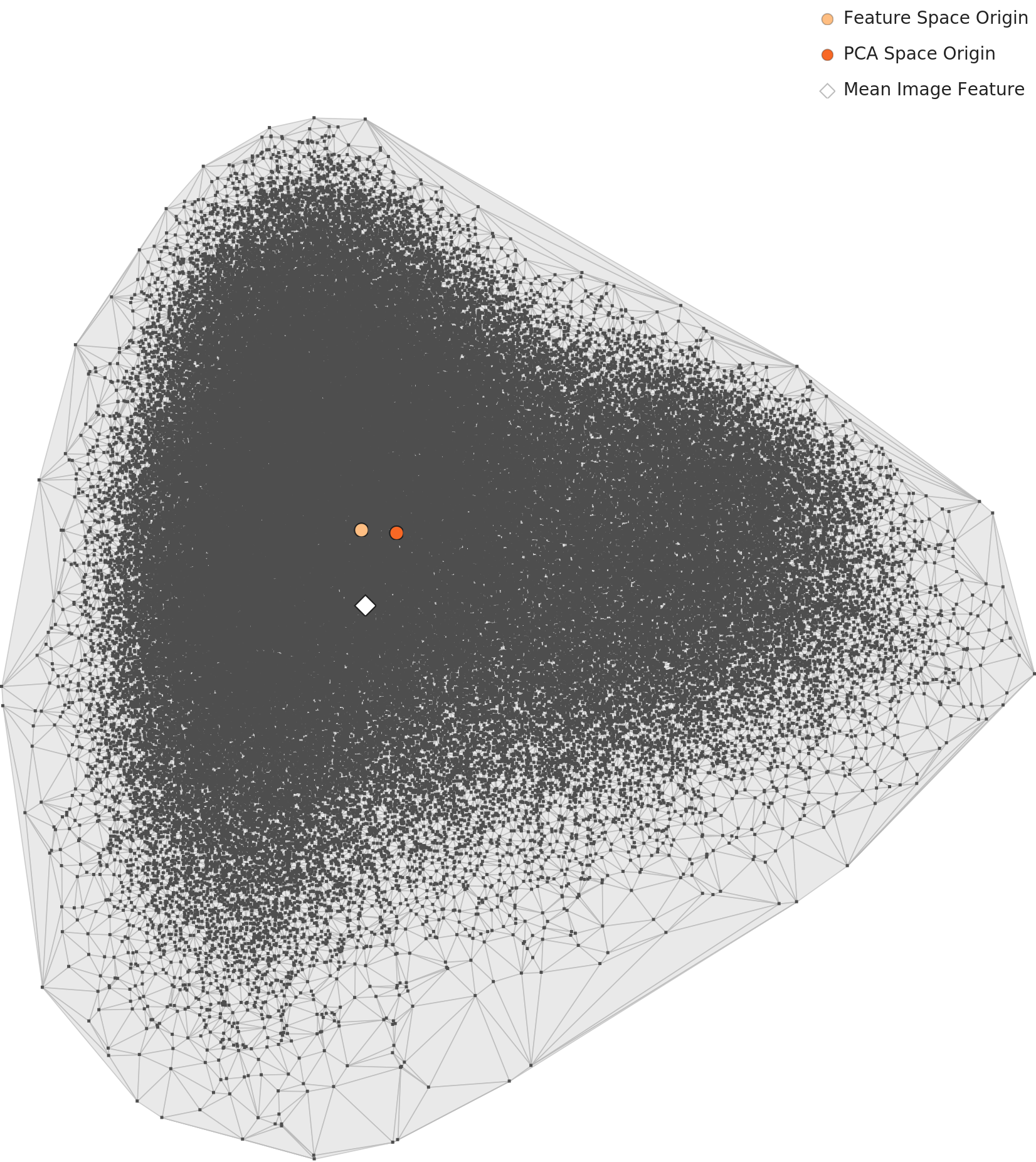
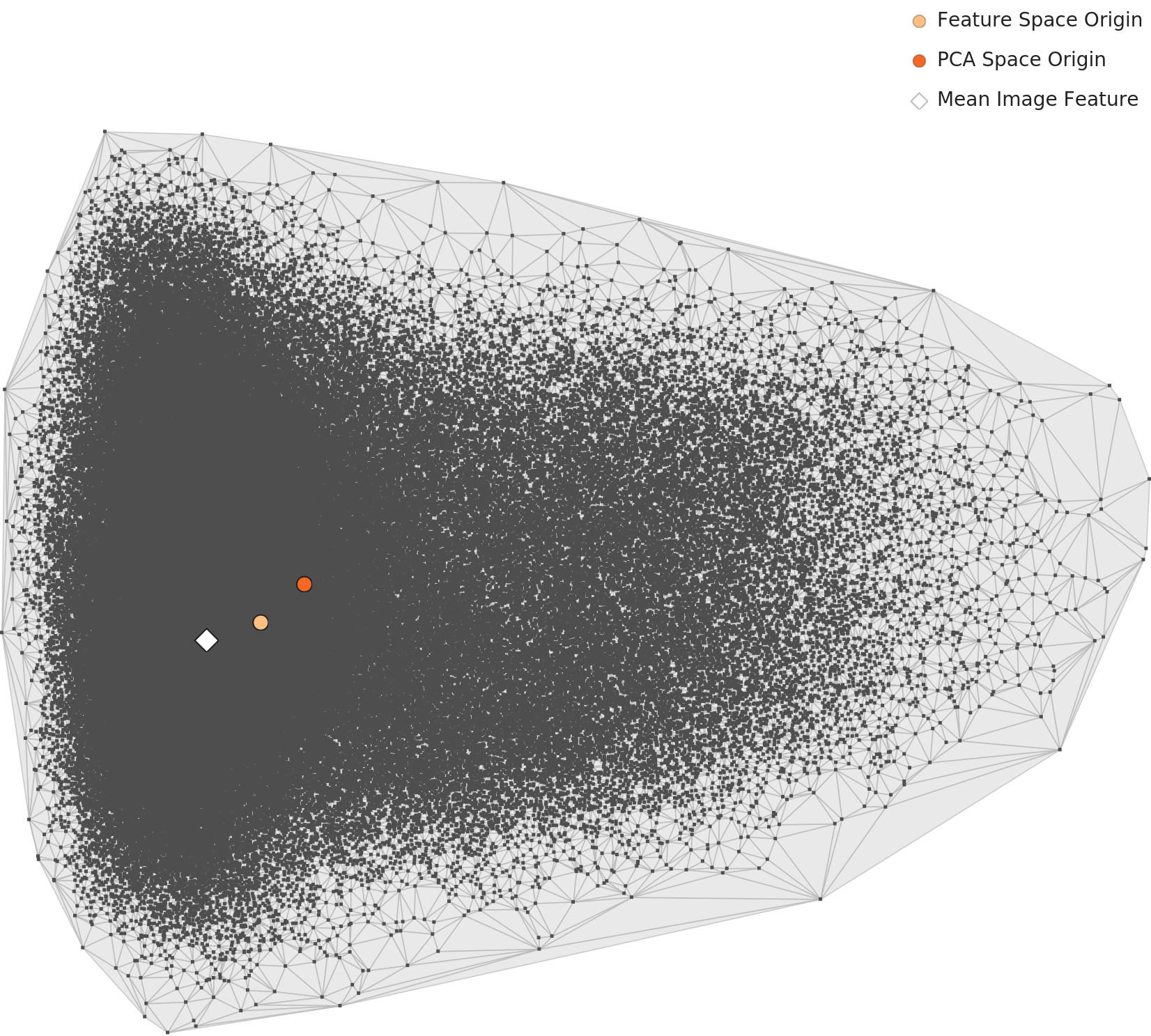
L2 (Feature Space Analysis) Wolfram ImageIdentify Net V2 (1,280 dimensions) revealed an intriguing pattern: general-purpose AI splits Korean food into two clusters -- soup-based dishes and dry dishes. In contrast, L3 (Domain-Specific Analysis, 129-dimension Korean food-specialized lens) merges these two clusters into a single unified Korean food space.
The most 'typical' food was Songpyeon(송편) (rice cake), while the most heterogeneous images were found in Gimbap(김밥) (seaweed rice rolls). Data Diet (deduplication) is recommended for classes with low visual diversity.
Dataset Overview — The World of 150 Korean Foods
The Korean Image (Food) dataset, published on AI Hub, is a large-scale Korean food vision dataset comprising 150 classes and 150,507 images, spanning from traditional Korean dishes to modern street food. It is commercially licensed, making it immediately available for developing AI-powered food recognition services.
The 150 classes capture the full landscape of Korean food culture:
- Soups & Stews — Galbitang(갈비탕, short rib soup), Mul-naengmyeon(물냉면, cold noodles), Samgyetang(삼계탕, ginseng chicken), Chueotang(추어탕, loach soup), Yukgaejang(육개장, spicy beef soup), Dakgaejang(닭개장, spicy chicken soup), Muguk(무국, radish soup)
- Grilled — Galbi-gui(갈비구이, grilled ribs), Samgyeopsal(삼겹살, pork belly), Galchi-gui(갈치구이, grilled hairtail), Godeungeo-gui(고등어구이, grilled mackerel)
- Braised & Stir-fried — Gaji-bokkeum(가지볶음, stir-fried eggplant), Kkaennip-jangajji(깻잎장아찌, pickled perilla leaves), Ganjang-gejang(간장게장, soy-marinated crab), Galbi-jjim(갈비찜, braised ribs)
- Street Food — Gimbap(김밥, seaweed rice rolls), Ramyeon(라면, instant noodles), Mandu(만두, dumplings), Tteokbokki(떡볶이, spicy rice cakes), Sundae(순대, blood sausage)
- Traditional Rice Cakes — Songpyeon(송편), Gyeongdan(경단, rice balls), Kkultteok(꿀떡, honey rice cake), Hangwa(한과, traditional confections)
- Seafood — Meongge(멍게, sea squirt), Gwamegi (semi-dried fish), Jeotgal (fermented seafood)
- Others — Korean fried chicken, Jajangmyeon (black bean noodles), Jjamppong (spicy seafood noodles), and other Korean-adapted versions of foreign dishes
Each food name carries the context of Korean food culture. Meongge(멍게, sea squirt) is one of the most difficult foods for AI models to recognize due to its distinctive fishy aroma and vermillion color. Gwamegi is a winter seasonal food from the Pohang region that is visually hard to distinguish from regular dried fish. How these 'domain-knowledge-demanding foods' affect data quality is at the core of this diagnosis.
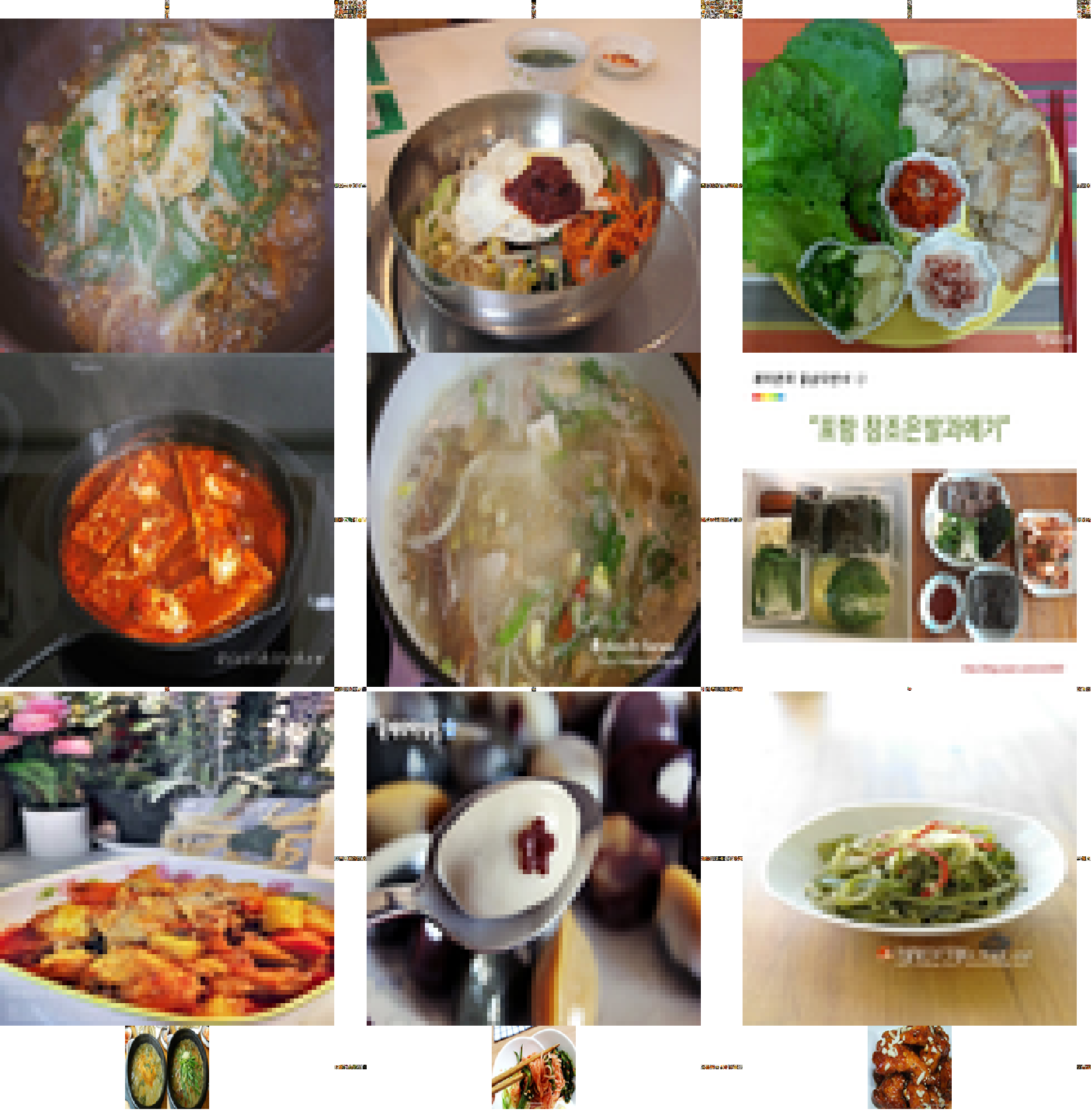
Korean Food Dataset — Representative image collage of 150 Korean food classes (DataClinic L1 analysis)






Class mean images -- pixel-level averages of ~1,000 images per class. Higher visual consistency produces sharper results.