Executive Summary
이 글은 DataClinic 리포트 #204의 진단 결과를 바탕으로 작성되었습니다. 왕산들사거리 고정 CCTV에서 촬영된 61,545장의 교통 영상 프레임을 AI 렌즈로 관찰하면, 하나의 교차로가 두 개의 완전히 다른 데이터 분포로 갈라집니다. 주간에는 맑고 한산한 도로, 야간에는 헤드라이트 글레어와 차량이 밀집한 전혀 다른 장면입니다.
이 이분화는 단순한 데이터의 특성이 아닙니다. 이 데이터로 자율주행 인식 AI를 학습하면, AI는 "교차로 = 밝고 한산한 주간 도로"로 편향 학습하고 야간 교차로에서 인식 성능이 급락합니다. 6만 장이라는 양적 풍부함이 오히려 독이 되는 비디오 프레임 과적합 위험까지 동시에 존재합니다.
라벨이 없는 단일 클래스 데이터셋에서도 DataClinic은 환경 조건별 하위 구조를 정밀하게 포착합니다. 데이터를 학습에 투입하기 전, 데이터 자체를 먼저 진단해야 하는 이유를 이 사례가 명확하게 보여줍니다.
데이터셋 소개 — 왕산들사거리, 6만 프레임의 정체
왕산들사거리는 청계지하차도사거리 방면에 설치된 고정 CCTV가 24시간 촬영하는 교차로입니다. 공공 교통 영상분석 협회가 제공한 이 데이터셋은 해당 CCTV에서 추출한 61,545장의 프레임으로 구성되어 있습니다. 해상도는 1280x720 RGB, 총 용량은 약 20GB입니다.
특이한 점은 이 데이터셋에 라벨이 없다는 것입니다. 차량, 보행자, 신호등 같은 객체 레이블이 붙어 있지 않고, 단일 클래스로만 구성되어 있습니다. 그렇다면 라벨이 없는 데이터에 진단이 필요할까요? DataClinic은 라벨 없이도 데이터의 내부 구조를 들여다봅니다.
아래는 DataClinic이 생성한 콜라주입니다. 6만 장의 프레임 중 대표적인 샘플들을 한눈에 볼 수 있습니다. 같은 교차로를 촬영했지만, 밝은 주간 장면과 어두운 야간 장면이 섞여 있는 것이 눈에 띕니다.

▲ DataClinic 콜라주 — 왕산들사거리 61,545장 중 대표 샘플
| 항목 | 값 |
|---|---|
| 데이터셋 이름 | 2502_왕산들사거리 공공 교통 영상 협회 제공 |
| Report ID / Dataset ID | #204 / 599 |
| 이미지 수 | 61,545장 |
| 해상도 | 1280 x 720 (RGB) |
| 용량 | ~20 GB |
| 클래스 | 단일 (라벨 없음) |
| 출처 | 공공 교통 영상분석 협회 |
| 촬영 장비 | 고정 CCTV (왕산들사거리, 청계지하차도 방면) |
L1: 정합성은 완벽 — 그런데 왜 진단이 필요한가?
DataClinic Level 1은 데이터의 기본 무결성을 검사합니다. 이미지 크기, 채널 수, 결측값 여부, 클래스 균형 등을 확인하는 단계입니다. 왕산들사거리 데이터셋은 이 단계를 깨끗하게 통과합니다. 61,545장 모두 1280x720 RGB로 일관되고, 결측값은 0개, 단일 클래스이므로 균형 문제도 없습니다.
그렇다면 L1을 통과한 데이터에 왜 추가 진단이 필요할까요? 답은 평균 이미지(Mean Image)에 있습니다. 6만 장을 픽셀 단위로 평균하면, 변하지 않는 것과 변하는 것이 극명하게 분리됩니다.
아래 평균 이미지를 보면 차선과 도로 구조는 선명하게 남아 있지만, 차량은 유령처럼 흐릿합니다. 이것은 차선은 고정된 배경이고 차량은 위치가 계속 바뀌는 전경이라는 뜻입니다. 즉, 이 데이터 안에는 "항상 같은 것"과 "매번 다른 것"이 공존하고 있으며, 그 비율과 분포가 AI 학습 품질을 결정합니다.

▲ 전체 평균 이미지 — 차선은 선명하고 차량은 유령처럼 흐릿하다
평균 이미지의 의미: 유령처럼 사라진 차량은 "위치가 일정하지 않다"는 뜻이고, 선명한 차선은 "모든 프레임에서 동일하다"는 뜻입니다. AI 입장에서 차선은 항상 같은 신호이고, 차량은 매번 다른 노이즈입니다. 이 구조를 이해하지 못하면 학습 데이터의 양만 보고 품질을 판단하는 실수를 하게 됩니다.
L2: AI 렌즈가 포착한 두 개의 세계
Level 2는 사전학습된 범용 AI 모델(ImageNet 기반)의 눈으로 데이터를 분석합니다. 각 이미지를 고차원 임베딩 공간에 투영한 뒤, PCA로 2차원으로 압축하면 데이터의 전체 구조가 드러납니다.
3.1 PCA 분포 — 두 클러스터의 분리
아래 L2 PCA 차트를 보면, 6만 장의 데이터가 두 개의 뚜렷한 덩어리로 나뉩니다. 하나의 교차로를 촬영했는데 AI는 이것을 완전히 다른 두 장소로 인식하고 있는 것입니다. 왼쪽 클러스터는 주간 이미지, 오른쪽 클러스터는 야간 이미지입니다.
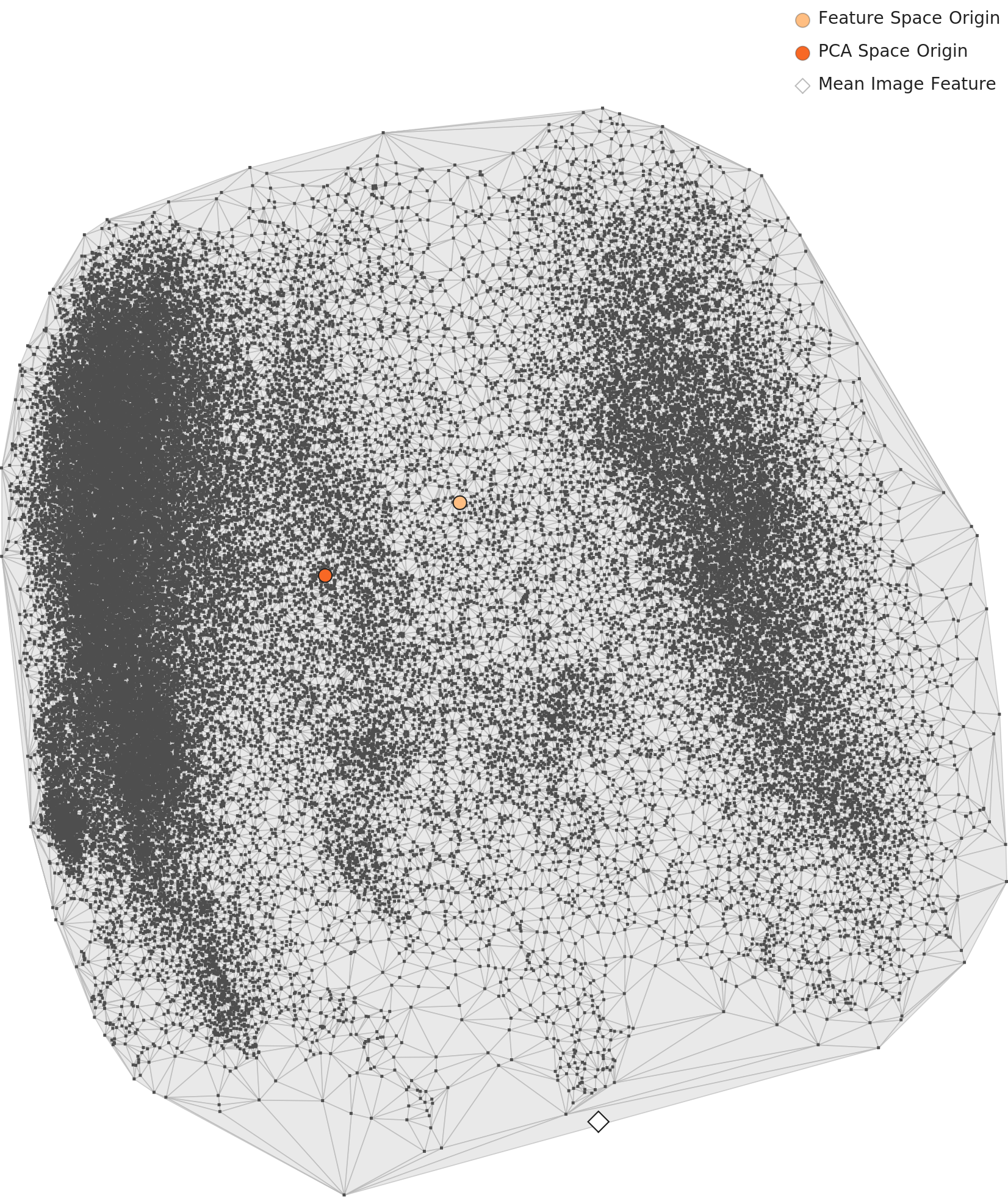
▲ L2 PCA 분포 — 데이터가 두 개의 클러스터로 분리된다
3.2 밀도 분포 — 핫스팟과 주변부
밀도 차트는 임베딩 공간에서 이미지들이 얼마나 밀집해 있는지를 보여줍니다. 고밀도 핫스팟이 2개 이상 관찰되며, 그 사이에 저밀도 주변부가 존재합니다. 이것은 데이터 분포가 연속적이지 않고 불연속적인 간극을 갖고 있다는 뜻입니다.
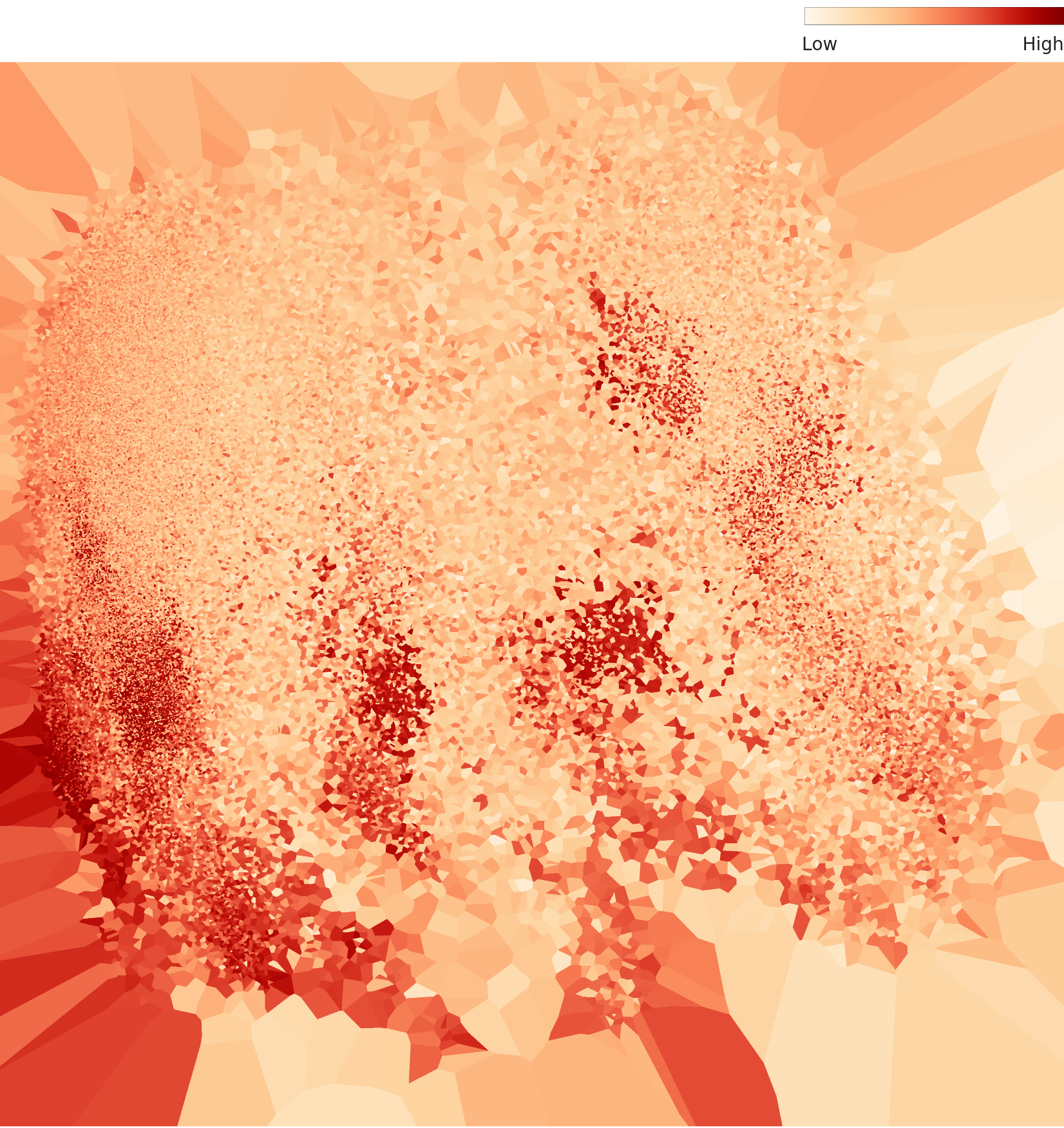
▲ L2 밀도 분포 — 핫스팟 사이 저밀도 간극이 보인다
3.3 고밀도 vs 저밀도 — 주간과 야간의 단면
두 클러스터의 실체를 확인하기 위해, 밀도가 가장 높은 이미지(전형적)와 가장 낮은 이미지(이상치)를 나란히 비교합니다. 고밀도 이미지는 주간, 맑은 날씨, 차량이 적고 차선이 선명합니다. 저밀도 이미지는 야간, 헤드라이트 글레어, 차량이 밀집하고 보행자가 횡단하는 장면입니다.
고밀도 샘플 (주간, 전형적)




저밀도 샘플 (야간, 이상치)




▲ 위: 주간 고밀도 샘플 (전형적) / 아래: 야간 저밀도 샘플 (이상치) — 같은 교차로의 완전히 다른 두 얼굴
핵심 발견: 같은 CCTV, 같은 교차로에서 촬영했지만 AI 임베딩 공간에서 주간과 야간 이미지는 마치 서로 다른 장소에서 찍은 것처럼 분리됩니다. 밀도 0.698(주간)과 0.136(야간) 사이에는 5배 이상의 격차가 있습니다. 이것이 학습에 반영되면, AI는 주간 패턴에 과도하게 의존하게 됩니다.
L3: 도메인 렌즈가 더 깊이 본 것
Level 3는 범용 렌즈 대신 835차원 도메인 최적화 렌즈를 사용합니다. 해당 데이터셋의 특성에 맞게 파인튜닝된 임베딩 공간에서 데이터를 다시 관찰합니다. L2에서 포착된 주간/야간 이분화가 L3에서는 어떻게 달라지는지가 핵심입니다.
4.1 L3 PCA — 더 뚜렷한 분리
L3 PCA 차트에서 두 클러스터의 분리는 L2보다 더 선명해집니다. 도메인 최적화 렌즈가 교통 영상의 특성을 더 정밀하게 포착하기 때문입니다. 주간과 야간 사이의 간극이 더 넓어졌다는 것은, 이 두 조건이 AI 관점에서 근본적으로 다른 도메인이라는 의미입니다.
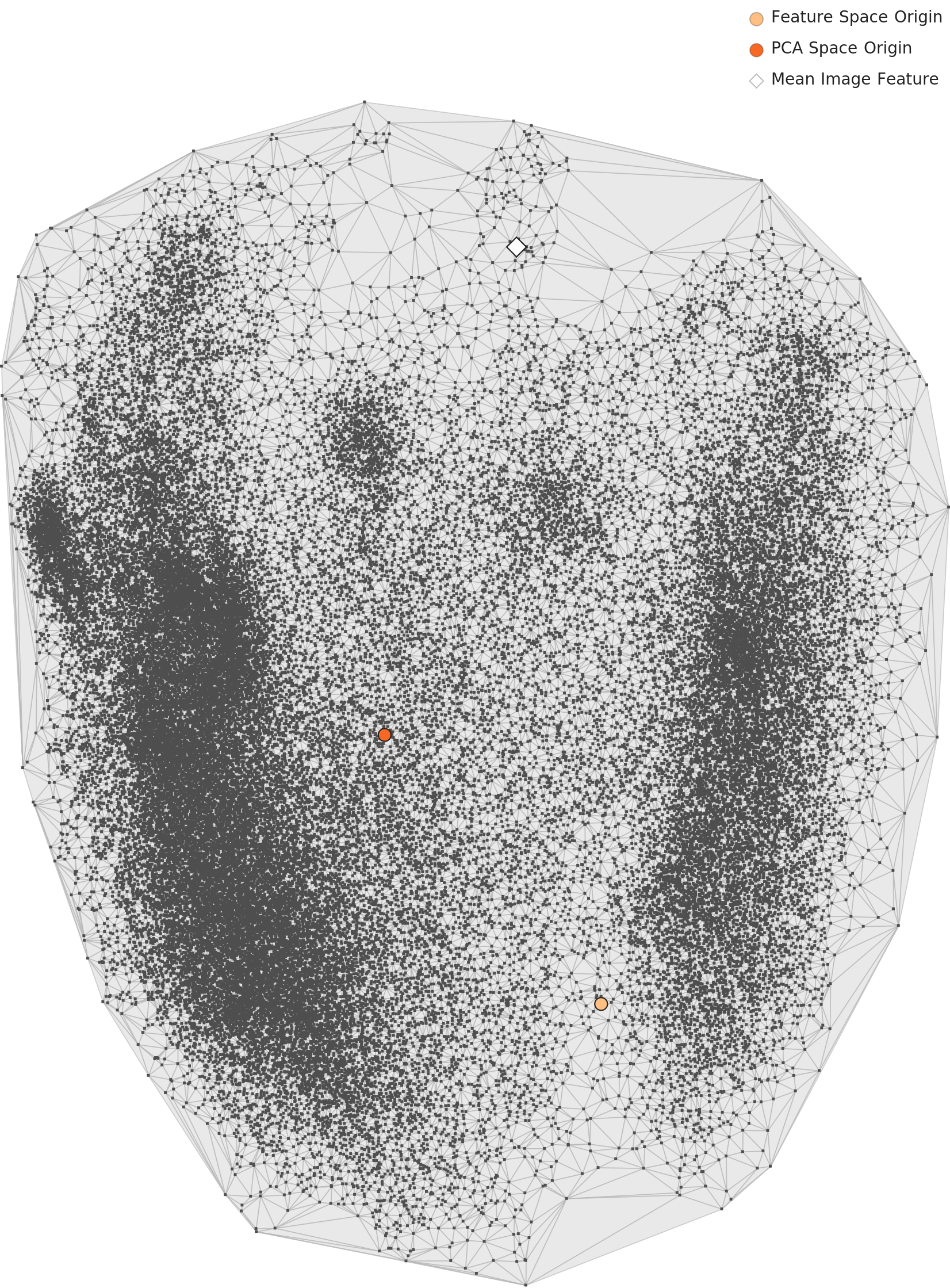
▲ L3 PCA 분포 — 835차원 도메인 최적화 후, 두 클러스터 분리가 더 뚜렷하다
4.2 L3 밀도 — 세분화된 하위 구조
L3 밀도 차트에서는 L2의 2개 핫스팟이 3개 이상으로 세분화됩니다. 주간 클러스터 내부에서도 맑은 날과 흐린 날, 또는 이른 아침과 한낮이 구분되기 시작합니다. 야간 클러스터 역시 헤드라이트 방향이나 차량 밀도에 따라 하위 구조가 형성됩니다.
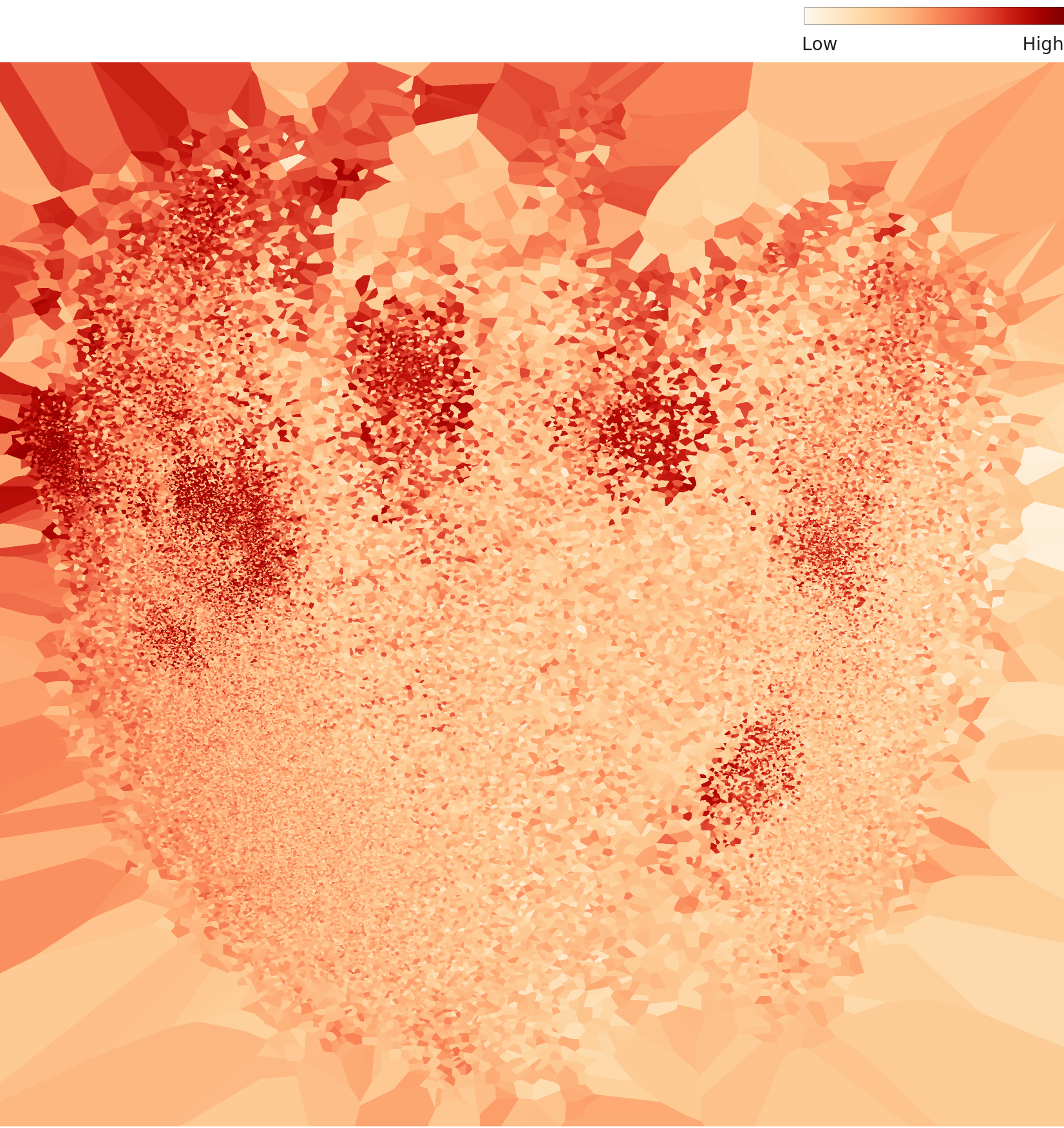
▲ L3 밀도 분포 — L2의 2개 핫스팟이 3개 이상으로 세분화되었다
L2 vs L3 차이: 범용 렌즈(L2)는 "주간 vs 야간"이라는 큰 구분을 포착하고, 도메인 렌즈(L3)는 그 안에서 날씨, 시간대, 교통량까지 구분합니다. 단일 클래스 데이터셋이라도 내부에는 AI 학습에 영향을 미치는 다층적 구조가 존재합니다.
비디오 프레임 함정 — 6만 장의 양이 독이 되는 순간
이 데이터셋에는 한 가지 더 중요한 문제가 숨어 있습니다. DataClinic의 nearest(가장 유사한) 이미지 분석에서, 상위 유사 이미지들이 연번으로 몰려 있습니다.



▲ 연번 프레임 00003741~00003745 — 거의 동일한 주간 교차로 장면이 5장의 "독립" 데이터로 취급된다
00003741, 00003742, 00003743 — 이것은 같은 시간대에 연속으로 촬영된 프레임입니다. 비디오 CCTV에서 초당 수십 프레임이 추출되므로, 인접 프레임끼리는 거의 동일한 장면을 담고 있습니다. 또 다른 연번 그룹인 00058638~00058642도 마찬가지입니다.
과적합 경고
연속 프레임이 독립 샘플로 취급되면, AI는 "같은 장면을 여러 번 외우는" 결과를 낳습니다. 6만 장이라는 숫자가 크게 보여도, 프레임 샘플링 없이는 실질적으로 수천 장 수준의 정보량만 담고 있을 수 있습니다. 학습 데이터의 양이 아니라 다양성이 AI 성능을 결정합니다.
반대로, farthest(가장 다른) 이미지들은 야간 장면에 집중되어 있습니다. 00039949(density 0.268), 00050352(0.179), 00050330(0.136) — 이 이미지들은 전형적인 주간 패턴과 가장 동떨어진, 헤드라이트 글레어가 강하고 차량이 밀집한 야간 장면입니다.
비디오 프레임 함정의 핵심: 연속 촬영된 프레임은 통계적으로 독립이 아닙니다. 이 데이터를 그대로 학습에 사용하면 (1) 주간 프레임의 중복이 학습을 지배하고, (2) 야간 이상치는 더욱 소외되며, (3) 모델은 "낮의 교차로"만 잘 인식하는 편향된 AI가 됩니다. 프레임 간격 샘플링(N프레임마다 1장 추출)이나 임베딩 기반 중복 제거가 필수적입니다.
실전 임팩트 — 이 데이터로 자율주행 AI를 학습하면
왕산들사거리 데이터셋의 주간/야간 이분화와 비디오 프레임 중복이 실제 AI 시스템에 미치는 영향을 시나리오별로 살펴봅니다. 이것은 가상의 이야기가 아닙니다. 교통 영상 데이터로 학습하는 모든 자율주행, 스마트 시티, 교통 관제 AI에 해당하는 현실적인 위험입니다.
시나리오 1: 주간 편향 학습
고밀도(전형적) 이미지가 주간에 집중되어 있으므로, AI는 "교차로 = 밝고 한산한 도로"로 학습합니다. 주간 테스트에서는 높은 정확도를 기록하지만, 이것은 데이터의 주류를 반영한 결과일 뿐 실제 일반화 성능이 아닙니다.
시나리오 2: 야간 성능 급락
야간 이미지는 저밀도 이상치로 분류되어 학습 시 영향력이 약합니다. 결과적으로, 야간 교차로에서 보행자 횡단, 차량 정체, 신호 변경 같은 핵심 상황을 인식하지 못합니다. 가장 위험한 시간대에서 가장 낮은 성능을 보이는 역설이 발생합니다.
시나리오 3: Sim-to-Real Gap
혼합 교통 시뮬레이션에서 이 데이터의 주간 분포만 학습한 가상 환경은, 실제 야간 교차로 상황을 재현하지 못합니다. 시뮬레이터와 현실 사이의 간극(Sim-to-Real Gap)이 데이터 수집 단계에서 이미 시작되는 것입니다. 이것은 혼합 교통 AI 시뮬레이션 리포트에서 지적한 Evaluation Crisis의 데이터 버전입니다.
DataClinic이 사전에 경고할 수 있는 것: L2/L3 밀도 분석은 데이터의 주간/야간 불균형을 수치로 보여주고, nearest 분석은 비디오 프레임 중복을 탐지합니다. 학습 전에 이 진단을 받았다면, 프레임 샘플링 + 야간 데이터 보강이라는 명확한 처방을 내릴 수 있었습니다. "6만 장이니까 충분하다"는 판단이 얼마나 위험한지, DataClinic은 데이터로 증명합니다.
결론 — 라벨 없는 데이터도 진단이 필요하다
왕산들사거리 데이터셋은 라벨이 없는 단일 클래스 데이터입니다. 클래스 분류도, 객체 검출 레이블도 없습니다. 그럼에도 DataClinic은 이 데이터 안에 숨겨진 환경 조건별 하위 구조를 정밀하게 포착했습니다.
같은 교차로에서 촬영한 6만 장이 주간과 야간이라는 두 개의 세계로 갈라지고, 연속 프레임 중복이 실질적 다양성을 떨어뜨리며, 이 데이터로 학습한 AI가 야간 교차로에서 실패할 수 있다는 사실은, 데이터 품질 진단이 라벨 유무와 무관하게 필수적이라는 것을 보여줍니다.
아래는 DataClinic으로 진단한 다른 데이터셋들과의 구조적 비교입니다. 도메인과 클래스 수가 달라도, "데이터 내부의 숨겨진 구조"라는 공통 과제가 존재합니다.
| 비교 항목 | #204 왕산들사거리 | #227 드론 분류 | #225 군사 3종 |
|---|---|---|---|
| 클래스 수 | 1 (라벨 없음) | 12 | 3 |
| 이미지 수 | 61,545 | 28,801 | 1,947 |
| 핵심 패턴 | 주간/야간 이분화 | 배경 반복 | 카메라 각도 클러스터 |
| 비디오 프레임 이슈 | 연번 프레임 과적합 | 시뮬레이션 프레임 중복 | 해당 없음 |
| DataClinic 발견 | 환경 조건별 하위 구조 | 완벽한 균형의 함정 | 카메라 각도별 클러스터 |
DataClinic 진단의 핵심 가치는 "라벨에 의존하지 않는 데이터 품질 분석"입니다. 라벨이 있든 없든, 이미지가 1천 장이든 6만 장이든, 데이터의 내부 구조를 먼저 이해하지 않으면 학습 결과를 예측할 수 없습니다. 왕산들사거리 사례가 그것을 증명합니다.
DataClinic 리포트 원본
이 글의 분석 기반이 된 전체 진단 리포트는 DataClinic Report #204에서 확인하실 수 있습니다.
References
- [1] DataClinic Report #204 — 왕산들사거리 공공 교통 영상. dataclinic.ai/en/report/204
- [2] 혼합 교통 AI 시뮬레이션 리포트 — Evaluation Crisis와 Sim-to-Real Gap. /report/mixed-traffic-ai-simulation/ko/
- [3] DataClinic Report #227 — PBLS_Drone_classification 드론 분류 진단. dataclinic.ai/en/report/227
- [4] DataClinic Report #225 — PBLS_Military_vehicle_3class 군사 차량 진단. dataclinic.ai/en/report/225