Executive Summary
이 글은 DataClinic 리포트 #194의 분석 결과를 바탕으로 작성되었습니다. "한국 전통 수묵 채색화 제작 데이터"는 3,995장의 이미지와 74개 클래스로 구성된 공공 데이터셋입니다. 그런데 이 데이터를 열어보면 호랑이와 국화 옆에 벤틀리 자동차, 탱크, 스마트폰이 나란히 놓여 있습니다. 74개 클래스 중 24개(1,651장)가 자동차, 비행기, 믹서기 같은 현대 인공물 — "전통"이라는 이름이 무색합니다.
DataClinic의 AI 렌즈는 이 모순을 정확히 포착합니다. Wolfram 1,280차원 범용 렌즈와 48차원 도메인 특화 렌즈 모두에서 전통 길상(吉祥) 소재인 박쥐(밀도 0.075)와 현대 운송수단 비행기가 특징 공간의 양 극단에 놓입니다. 하나의 데이터셋 안에 본질적으로 다른 두 세계가 공존하고 있다는 증거입니다.
종합 점수 57점(나쁨). 기법은 수채화/먹 기법으로 일관되지만, 피사체는 조선시대 산수부터 21세기 고급 승용차까지 무차별 혼합됩니다. 문제는 이미지 수가 아니라 도메인 정의 자체가 흔들린다는 것입니다.
DataClinic 등급 요약
데이터셋 개요 — "전통 수묵 채색화"의 이름 아래
"한국 전통 수묵 채색화 제작 데이터"는 AI Hub를 통해 공개된 공공 데이터셋입니다. 한국의 전통 회화 기법 — 먹과 붓, 수채 안료로 그린 그림들을 디지털화해 AI 학습에 활용하겠다는 취지로 구축되었습니다. 상업적 이용이 가능하며, DataClinic에서 리포트 #194로 진단할 수 있습니다.

▲ 3,995장의 "한국 전통 수묵 채색화" — 호랑이와 국화 사이에 벤틀리와 탱크가 보인다 (DataClinic L1 콜라주)
콜라주를 처음 보는 순간, 기대와 현실의 괴리가 눈에 들어옵니다. 산수화, 호랑이, 잉어, 국화처럼 전통 회화의 단골 소재가 있는가 하면, 그 옆에 고급 승용차, 전투기, 스마트폰이 나란히 놓여 있습니다. 모두 흰 배경 위에 단일 피사체가 중앙에 배치된 일관된 구도입니다. 기법은 수채화/먹 터치로 통일되어 있지만, 그려진 대상은 조선시대부터 21세기까지 시간을 무시합니다.
데이터셋 사양
- • 3,995장 이미지
- • 74개 클래스
- • 고해상도: 3,040×2,150 ~ 9,930×7,020px
- • RGB 채널 일관
- • 클래스당 평균 48장 (표준편차 17)
- • 상업적 이용 가능
클래스 구성
- • 자연물 50종 (동물, 식물, 풍경, 사람)
- • 인공물 24종 (차량, 가전, 가구, 건축물)
- • 자연물 평균 46.9장/클래스
- • 인공물 평균 68.8장/클래스
- • 최대: 집 85장
- • 최소: 곰 27장
여기 정말 전통 회화만 있는가?
"전통 수묵 채색화"라는 이름을 들으면 떠오르는 것이 있습니다. 호랑이는 산군(山君)이자 수호신, 잉어는 등용문(登龍門)의 상징, 국화는 사군자(四君子)의 하나로 은일(隱逸)을 뜻하며, 소나무는 지조와 절개를 나타냅니다. 이런 전통 화제(畫題)들은 수백 년 동안 한국 회화의 중심을 이뤄왔습니다.
그런데 이 데이터셋을 실제로 열어보면, 전통 화제와 나란히 자동차(79장), 오토바이(78장), 전화기(75장), 비행기(72장), 탱크(66장), 믹서기(57장)가 들어 있습니다. 아래에서 전통 화제 6종과 현대 사물 6종을 나란히 놓아봤습니다. 각 카드의 왼쪽은 실제 이미지, 오른쪽은 해당 클래스의 평균 이미지입니다.
전통 화제 — 한국 회화의 단골 소재
 실제
실제
 평균
평균
 실제
실제
 평균
평균
 실제
실제
 평균
평균
 실제
실제
 평균
평균
 실제
실제
 평균
평균
/2_13_49_0026.jpg) 실제
실제
.png) 평균
평균
▲ 전통 화제 6종 — 평균 37.7장/클래스. 각 카드 왼쪽: 실제 샘플 / 오른쪽: 평균 이미지
현대 사물 — "전통 회화"에 들어온 21세기
 실제
실제
 평균
평균
 실제
실제
 평균
평균
/1_6_23_0010.jpg) 실제
실제
.png) 평균
평균
/1_2_7_0052.jpg) 실제
실제
.png) 평균
평균
 실제
실제
 평균
평균
 실제
실제
 평균
평균
▲ 현대 사물 6종 — 평균 69.5장/클래스. 전통 소재보다 거의 2배 많다
핵심 발견: "전통 회화" 데이터셋인데 전통 소재(호랑이 43장, 잉어 32장, 곰 27장)가 오히려 소수파입니다. 현대 인공물 24개 클래스는 평균 68.8장을 갖고 있는 반면, 자연물 50개 클래스는 평균 46.9장에 그칩니다. 전통의 이름을 빌렸지만, 데이터의 무게 중심은 현대 쪽에 기울어져 있습니다.
Level I 진단 — 겉보기에는 단정한 데이터
Level I은 이미지의 기본 물리적 속성을 진단합니다. 결측치는 없고 채널은 RGB로 일관됩니다. 그러나 이미지 크기에서 문제가 드러납니다.
이미지 크기 정합성: 나쁨
최소 해상도 3,040×2,150px부터 최대 9,930×7,020px까지, 크기 비율이 약 3.3배에 달합니다. DataClinic의 기준선인 1.5배를 크게 초과합니다. 모든 이미지가 고해상도 스캔(최소 약 650만 픽셀)이므로 다운샘플링으로 해결할 수 있지만, 현재 상태로는 모델 훈련 전에 반드시 리사이징 전처리가 필요합니다.
전체 평균 이미지가 말해주는 것
3,995장을 모두 겹치면 어떤 모습일까요? 전체 평균 이미지는 밝은 회색/베이지 배경 위에 흐릿한 갈색 덩어리가 중앙에 놓인 형태입니다. 어떤 구조도, 질감도, 형태도 식별할 수 없습니다.

▲ 3,995장의 전체 평균 이미지 — 모든 그림이 "흰 배경 위 중앙 피사체"라는 동일한 구도임을 보여준다
이것은 모든 이미지가 동일한 구성 패턴을 따른다는 증거입니다. 흰 배경 위에 단일 피사체가 중앙에 놓인 일러스트레이션 — 전통 수묵화의 여백과 구도 미학과는 거리가 있습니다. DataClinic이 "다양성이 낮다"고 진단한 것은 픽셀 수준의 시각적 다양성을 말합니다. 의미론적으로는 74개 종류의 피사체가 있지만, AI 렌즈가 보는 시각적 패턴은 놀라울 만큼 균일합니다.
클래스 균형: 불균형 비율 3.15(최대 85장 / 최소 27장)는 "보통" 수준입니다. 그러나 이 수치 뒤에 숨은 패턴이 있습니다. 인공물 클래스(평균 68.8장)가 자연물 클래스(평균 46.9장)보다 체계적으로 더 많습니다. "전통 회화" 데이터셋에서 현대 인공물이 더 두텁게 구축되어 있다는 아이러니입니다.
Level II 진단 — Wolfram 렌즈가 본 74개 세계
Level II는 Wolfram ImageIdentify Net V2의 1,280차원 범용 렌즈로 이미지를 관찰합니다. 픽셀이 아닌 고차원 특징 공간에서 데이터의 기하학적 구조와 밀도 분포를 진단합니다.
PCA — 단일 클러스터, 내부 밀도 기울기
1,280차원에서 2차원으로 투영한 PCA 차트를 보면, 3,995장의 이미지는 하나의 큰 클러스터를 형성합니다. 형태는 가로로 약간 길고 날씬합니다. 명확히 분리된 서브클러스터는 없지만, 클러스터 내부에는 밀도가 다른 구역이 존재합니다. 중심-좌측은 밀도가 높고, 주변부로 갈수록 점이 흩어집니다.
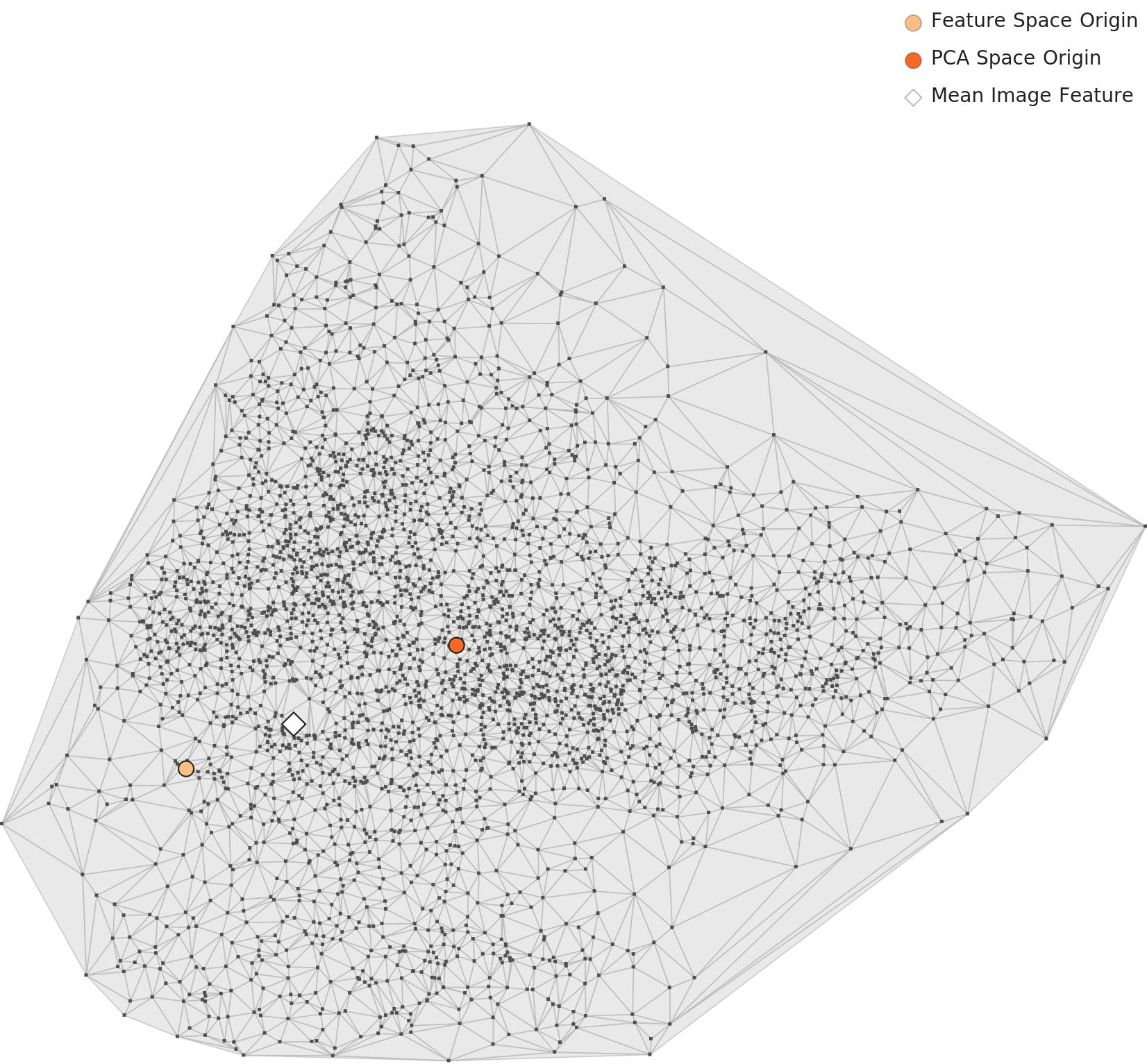
▲ L2 PCA — 단일 클러스터이지만 내부에 밀도 기울기가 존재한다. 주황 점: 특징 공간 원점, 빨강 점: PCA 공간 원점.
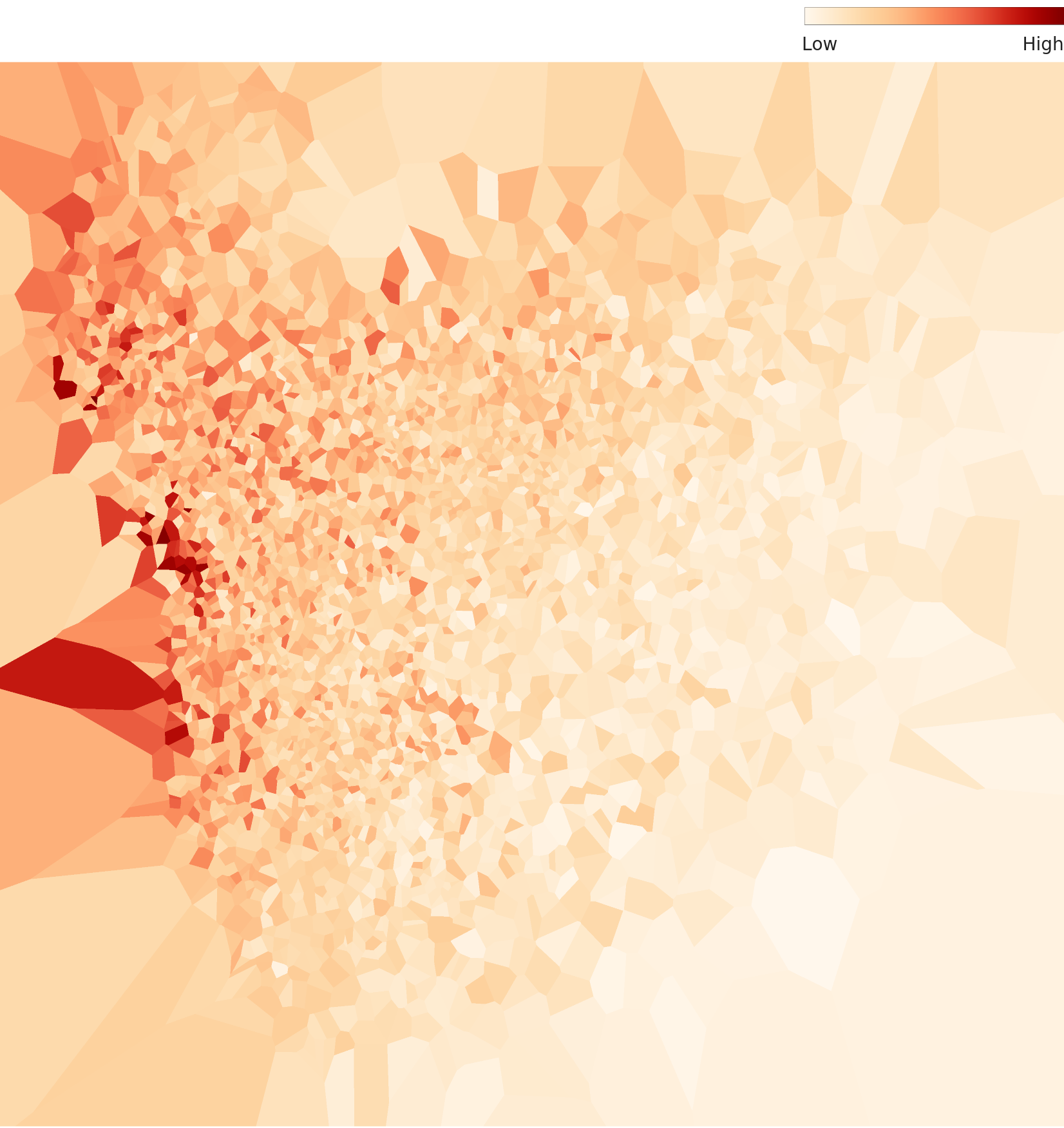
밀도 히트맵 — API 주장과 시각적 현실의 차이
DataClinic API는 이 분포를 "원점과 데이터 중심에서 종모양(bell-shaped)"이라고 설명합니다. 그러나 실제 밀도 히트맵을 보면 분포는 비대칭적으로 한쪽 구석에 집중되어 있습니다. 고밀도 핵심부(짙은 적색)는 제한된 영역에 몰려 있고, 나머지 공간은 저밀도로 넓게 퍼져 있습니다. "종형"보다는 "비대칭 집중"이 더 정확한 표현입니다.

▲ L2 밀도 히트맵 — 비대칭적으로 집중된 분포. API의 "종형" 설명과 시각적 현실 사이에 차이가 있다.
클래스별 밀도 — 고밀도 vs 저밀도
Wolfram 렌즈의 눈으로 각 클래스를 들여다보면, 단순하고 대칭적인 형태의 객체(그릇, 병)는 높은 밀도로 꽉 뭉치고, 비정형적인 생물(박쥐, 문어, 가오리)은 낮은 밀도로 넓게 흩어집니다.
.png) 밀도
밀도
/1_1_3_0071.jpg) 실제
실제
 밀도
밀도
 실제
실제
 밀도
밀도
 실제
실제
 밀도
밀도
 실제
실제
▲ 각 카드 왼쪽: L2 밀도 차트 / 오른쪽: 클래스 대표 이미지(실제 샘플)
최근접/최원거리 이웃 — 데이터 안의 두 세계
DataClinic의 유사도 분석은 특징 공간에서 가장 가까운 이웃과 가장 먼 이웃을 찾아냅니다. 가까운 이웃은 시각적 형태가 비슷한 클래스끼리 뭉칩니다. 박쥐-공룡-나비-가오리는 어두운 실루엣이라는 공통점으로 묶이고, 수달-햄스터-토끼는 작은 포유류의 유사한 체형으로 가까워집니다.
반면, 가장 먼 쌍이 드러내는 것은 이 데이터셋의 근본적 모순입니다. 특징 공간에서 가장 멀리 떨어진 두 클래스는 박쥐와 비행기입니다.
밀도 0.075
현대 운송수단
▲ 특징 공간에서 가장 먼 두 클래스: 전통 길상 소재 박쥐와 현대 운송수단 비행기. 하나의 데이터셋 안에 본질적으로 다른 두 세계가 공존한다.
아이러니: 박쥐(蝙蝠)는 한자 발음이 복(福)과 같아 전통 회화에서 행운과 복록을 상징하는 대표적 길상 소재입니다. 그런데 "전통 회화" 데이터셋에서 이 전통의 핵심 소재가 가장 낮은 밀도(0.075)로 AI에게 가장 불확실한 존재이고, 가장 현대적인 소재인 비행기와 특징 공간에서 가장 멀리 떨어져 있습니다. 전통의 심장부가 도리어 AI의 사각지대인 셈입니다.
Level III 진단 — 48차원 특화 렌즈, 더 선명한 내부 구조
Level III는 3백만 이미지로 학습된 265층 신경망에서 추출한 48차원 최적화 렌즈를 적용합니다. 범용 렌즈(1,280차원)에서 보이지 않던 도메인 특화 구조를 더 선명하게 드러내는 것이 목적입니다.
PCA — 더 콤팩트하지만 내부 구조는 더 뚜렷
48차원 렌즈로 투영한 PCA 차트는 L2보다 더 콤팩트하고 둥근 분포를 보여줍니다. 최적화된 렌즈가 데이터를 더 가깝게 당겼다는 뜻입니다. 그러나 그 안에서 밀도의 편차는 오히려 더 뚜렷합니다. 넓은 범주 — 인공물 vs 자연물, 큰 동물 vs 작은 객체 — 에 따른 서브그룹이 드러납니다.
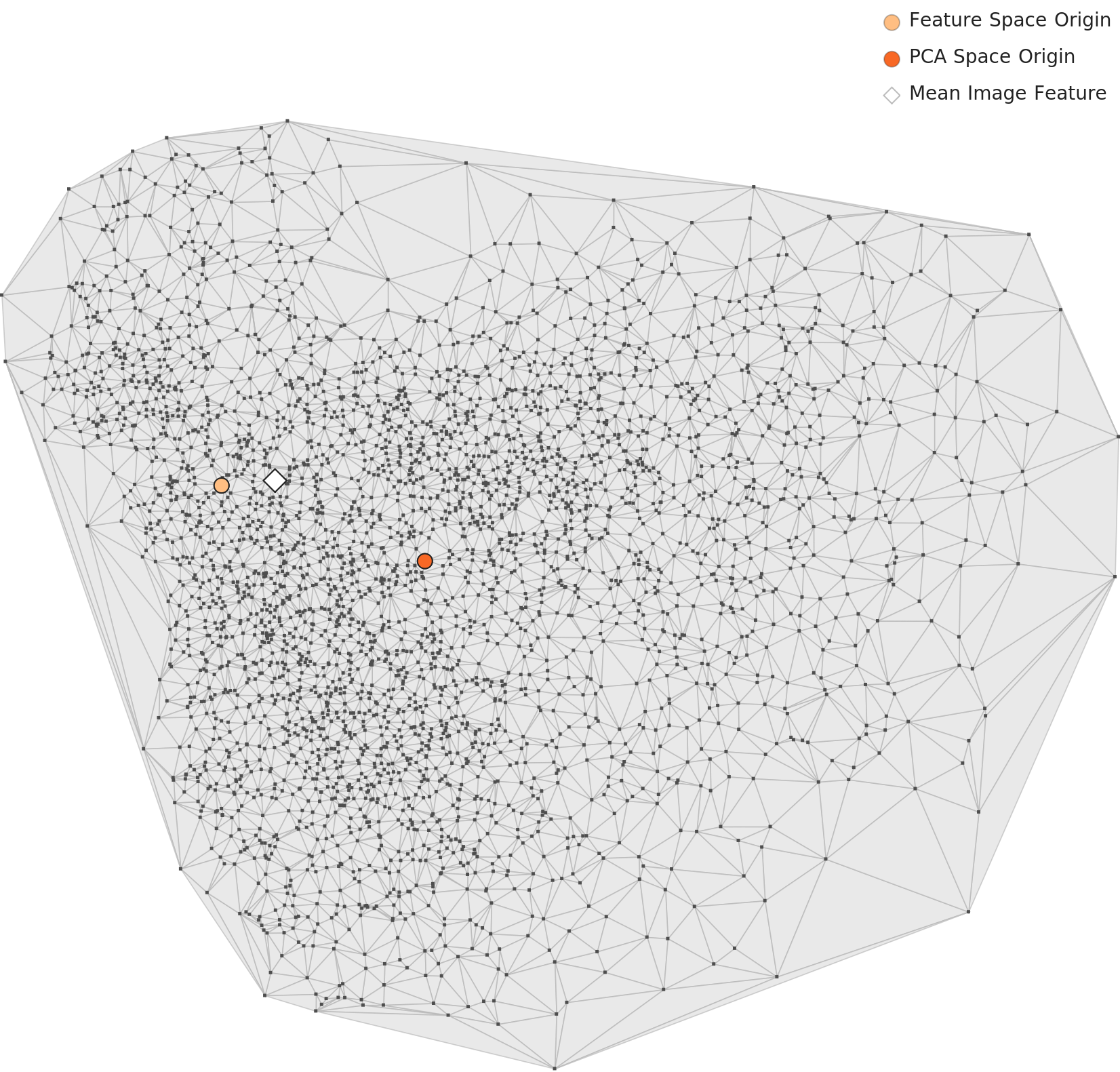
▲ L3 PCA — L2보다 콤팩트하지만 내부 밀도 편차가 더 두드러진다.
밀도 히트맵 — 이봉형(bimodal) 구조
L3 밀도 히트맵에서는 L2에서 보이지 않던 이봉형 구조가 뚜렷해집니다. 한쪽에 고밀도 집중 구간이 있고, 떨어진 위치에 또 다른 밀도 핵이 보입니다. 48차원 렌즈가 데이터 안의 두 계열 — 아마도 인공물 계열과 자연물 계열 — 을 분리하기 시작한 것입니다.
▲ L3 밀도 히트맵 — L2보다 이봉형(bimodal) 구조가 뚜렷하다. 관련성 0.999로 L2와 L3가 같은 현상의 다른 해상도를 보여준다.
세 개의 밀도 존
L2와 L3 분석을 종합하면, 이 데이터셋의 74개 클래스는 밀도에 따라 세 구역으로 나뉩니다.
그릇, 병, 햄스터, 아기 등 — 단순하고 대칭적인 형태. AI가 가장 확신 있게 인식하는 클래스들.
고양이, 개, 자동차, 가구 등 — 보통 수준의 자세 변이를 가진 일반적 피사체.
박쥐, 문어, 가오리, 공룡 등 — 비정형 체형에 극심한 자세 변이. AI의 사각지대.
L2 vs L3 비교: 두 렌즈의 관련성은 0.999로 거의 동일한 현상을 관찰하고 있습니다. 차이는 해상도입니다. L2(1,280차원)가 하나의 넓은 클러스터로 뭉뚱그리는 구조를, L3(48차원)는 그 안에서 인공물과 자연물의 밀도 핵이 분리되는 것까지 포착합니다. 48차원 최적화 렌즈가 도메인 부합성 문제를 더 날카롭게 드러내는 셈입니다.
WikiArt와의 비교 — 같은 미술, 다른 실패
미술 데이터셋이라면 WikiArt을 빼놓을 수 없습니다. DataClinic 리포트 #115로 진단된 WikiArt은 81,471장의 서양 미술 작품을 27개 화풍(Impressionism, Baroque 등)으로 분류한 데이터셋입니다. 종합 점수 53점(나쁨) — 한국 전통 수묵 채색화의 57점과 비슷한 수준입니다. 두 데이터셋 모두 "미술"이라는 도메인에서 "나쁨" 등급을 받았지만, 실패의 원인은 정반대입니다.
| 항목 | WikiArt #115 | 한국 전통 수묵 채색화 #194 |
|---|---|---|
| 점수 | 53 (나쁨) | 57 (나쁨) |
| 이미지 수 | 81,471장 | 3,995장 |
| 클래스 | 27개 (화풍) | 74개 (피사체) |
| 분류 기준 | 화풍 (Impressionism 등) | 피사체 (호랑이, 자동차 등) |
| 핵심 문제 | 화풍 간 경계 모호 | 전통/현대 피사체 혼재 |
| 도메인 부합성 | 높음 (실제 미술 작품) | 낮음 (현대 사물 다수 포함) |
| 실패 본질 | AI가 미술을 이해하기 어려움 | 사람이 데이터셋을 잘못 정의함 |
WikiArt의 어려움은 본질적입니다. 모네와 르누아르의 경계는 미술사학자들조차 논쟁합니다. 화풍을 분류하는 것 자체가 AI에게 극도로 어려운 과제이고, 이것은 데이터셋의 결함이 아니라 도메인의 본질적 난이도입니다.
반면 #194의 문제는 구조적입니다. 호랑이와 자동차의 분류는 어렵지 않습니다 — 어떤 AI도 둘을 헷갈리지 않습니다. 문제는 "이것을 왜 같은 데이터셋에 넣었는가?"입니다. 탱크를 수묵화 기법으로 그렸다고 해서 그것이 전통 회화가 되지는 않습니다.
두 미술 데이터셋의 교훈: 서양 미술(WikiArt)은 경계의 모호함으로 실패하고, 한국 전통 미술(#194)은 정체성의 혼란으로 실패합니다. 데이터 품질은 이미지 수가 아니라 "무엇을 담았는가"에 달려 있습니다. 81,471장이든 3,995장이든, 도메인 정의가 흔들리면 점수도 흔들립니다.
So What — 이 데이터로 AI를 학습시키면
데이터 품질 진단은 그 자체로 끝나지 않습니다. "이 데이터셋으로 실제 AI 시스템을 구축하면 무슨 일이 벌어지는가?" — 이 질문에 답해야 진단이 완결됩니다.
문화재 분류 AI의 오작동
국립중앙박물관이 소장 회화 자동 분류 시스템을 구축한다고 가정합니다. 이 데이터셋으로 "한국 전통 수묵 채색화"를 학습한 AI는 벤틀리 자동차, 탱크, 스마트폰이 그려진 수채화를 "전통 한국 회화"로 분류할 것입니다. 실제 조선시대 산수화와 현대 자동차 일러스트가 같은 카테고리에 놓이는 상황입니다.
전통 화풍 생성 AI의 왜곡
"한국 전통 수묵화 스타일로 그려줘"라는 프롬프트에 이 데이터로 학습한 생성 AI가 응답하면? 호랑이와 소나무 사이에 오토바이와 믹서기가 등장하는 기괴한 결과물이 나올 수 있습니다. "전통"이라는 레이블이 현대 사물까지 포괄하고 있기 때문입니다.
문화 데이터 수출의 신뢰 문제
한국 전통 미술 데이터셋이라는 이름으로 해외 연구자에게 공개되었을 때, 탱크와 비행기가 포함된 것을 발견한 연구자는 한국 문화 데이터 전체의 신뢰성을 의심하게 됩니다. 데이터 하나의 도메인 정의 오류가 국가 문화 데이터 인프라에 대한 신뢰를 훼손할 수 있습니다.
밀도가 말해주는 오분류 위험
밀도 분석에서 가장 역설적인 결과를 비교해봅니다.
한자 蝙蝠의 발음이 福과 같아, 전통 회화에서 복과 행운의 상징. 그런데 AI가 가장 불확실하게 보는 클래스입니다.
현대 정물화 소재. 전통 회화의 핵심 화제가 아닌데, AI가 가장 확신 있게 인식하는 클래스입니다.
"전통 회화" 데이터셋에서 AI가 가장 잘 아는 것은 그릇이고, 가장 모르는 것은 박쥐(복의 상징)입니다. 전통의 심장부가 도리어 AI의 사각지대 — 이것이 도메인 정의 오류가 만들어내는 구조적 왜곡입니다.
처방 — DataClinic의 제안과 추가 진단
DataClinic은 이 데이터셋에 데이터 벌크업(Data Bulk-up)을 권장합니다. 클래스별 샘플 수가 불균형하고 전반적 밀도가 낮으므로, 이미지를 보충해야 한다는 진단입니다. 맞는 지적이지만, 근본적인 문제는 더 깊은 곳에 있습니다.
우선순위 1: 도메인 큐레이션
가장 시급한 것은 이미지를 더 넣는 것이 아니라, 현재 들어 있는 이미지를 재정리하는 것입니다. 두 가지 방향이 있습니다.
- A. 현대 사물 분리: 자동차, 비행기, 탱크, 스마트폰 등 비전통 소재를 별도 데이터셋으로 분리합니다. 남은 자연물 + 전통 건축 클래스로 순수 전통 회화 데이터셋을 재구성합니다.
- B. 데이터셋 재명명: "한국 전통 수묵 채색화"를 "수묵/수채 기법 다종 피사체 데이터"로 변경합니다. 기법은 일관되므로, 기법 중심 명명이 더 정확합니다.
우선순위 2: 전통 소재 클래스 보강
곰(27장), 잉어(32장), 가오리(28장) 등 전통 화제의 샘플 수를 70장 이상으로 보강합니다. 인공물 클래스 평균(68.8장)과 대등한 수준으로 맞추는 것이 목표입니다.
우선순위 3: 저밀도 클래스 자세 통제
박쥐(0.075), 문어(0.075), 가오리(0.079) 등 저밀도 클래스는 이미지를 추가할 때 자세와 구도를 어느 정도 통일하여 클러스터를 응집시켜야 합니다. 수를 늘리되, 통제된 변이 안에서 늘려야 밀도가 개선됩니다.
우선순위 4: 이미지 크기 표준화
3.3배에 달하는 크기 비율을 해소해야 합니다. 모든 이미지가 고해상도이므로, 공통 해상도(예: 4,000×3,000px)로 다운샘플링하는 것이 현실적입니다.
핵심: DataClinic의 "데이터 벌크업" 처방은 양적 보강입니다. 그러나 이 데이터셋의 근본 문제는 양이 아니라 도메인 정의입니다. 벤틀리를 수묵화 기법으로 그렸다고 해서 그것이 전통 회화가 되지는 않습니다. 이미지를 더 넣기 전에, 먼저 "이 데이터셋이 무엇인가"를 다시 정의해야 합니다.