2026.03 · Pebblous Data Communication Team
Reading time: ~25 min · 한국어
Executive Summary
This post tells the technical and historical story behind Quality Diagnosis Report #123 for the ImageNet dataset, generated using Pebblous DataClinic.
ImageNet was the catalyst of the deep learning revolution. Before AlexNet trained on this dataset in 2012 and reduced the Top-5 error rate from 26% to 15.3%, computer vision was at a standstill. Without this dataset of 1,431,167 images across 1,000 classes, neither ChatGPT nor DALL-E would exist today.
DataClinic's diagnosis yielded a quality score of 60 (Fair). Class balance, missing values, and integrity are good, but lack of image diversity (statistical measurement: Poor) and 1 high-density cluster were detected. The visual similarity of 120 dog breeds, duplicate images between train and test sets, and label errors reaching 6% — even the dataset that gave birth to deep learning was not perfect.
And these findings go beyond a simple quality report, offering clues to understanding how AI datasets had to evolve from ImageNet to LLMs and then to Physical AI.
The Origin Story — 2006, a Conference Room in Princeton
In 2006, a young Stanford professor named Fei-Fei Li was facing skepticism from her colleagues. Her argument ran counter to the mainstream AI research of the time: "Scaling up data matters more than improving algorithms." Most researchers at the time were focused on designing cleverer algorithms.
The state of computer vision datasets at the time was bleak. The most widely used dataset, PASCAL VOC, had only 20 classes with about 10,000 images, and Caltech-101 had just 101 classes with 9,000 images. Given that the human visual system distinguishes hundreds of thousands of concepts, achieving general-purpose visual recognition with these datasets was nearly impossible.
Fei-Fei Li's idea was simple and bold: leverage WordNet's hierarchical concept system (~100,000 noun nodes) to crawl images from the internet and build a massive dataset. But the challenge was scale. Assigning accurate labels to millions of individual images would have taken decades with existing lab staff.
The Discovery of Amazon Mechanical Turk
The solution came from an unexpected place: Amazon Mechanical Turk — a crowdsourcing platform that pays small amounts for simple tasks. Using this platform, tens of thousands of people around the world could simultaneously work on image labeling.
Over three years, Fei-Fei Li's team completed the following:
- Selected approximately 5,247 visually meaningful categories from WordNet's ~22,000 synonym sets (synsets)
- Crawled hundreds to thousands of candidate images per category from the internet
- About 25,000 Mechanical Turk workers from 167 countries participated in image verification
- Completed a total of approximately 3.2 million labeled images
When first presented at CVPR in 2009, ImageNet was more than 100 times larger than any visual dataset in existence. That same year, the ILSVRC (ImageNet Large Scale Visual Recognition Challenge) was launched — the beginning of a competition that would change AI history.
📚 What is WordNet?
An English lexical database developed at Princeton University. It organizes words into a meaning-based network with a hierarchical structure. For example: "dog" → "mammal" → "animal" → "organism" — superordinate and subordinate concepts are connected in a tree structure. All 1,000 classes in ImageNet correspond to WordNet synsets (synonym sets).
September 30, 2012 — The Day Everything Changed
The day the ILSVRC 2012 results were announced. When the score from University of Toronto graduate student Alex Krizhevsky's submission appeared on screen, competitors could not believe it.
ILSVRC Top-5 Error Rate Change
Runner-up: 26.2% — AlexNet alone opened a gap of more than 10%p
AlexNet, designed by Krizhevsky, Sutskever, and Hinton, was not simply a better algorithm. It was the first success story combining three key elements:
- Deep Convolutional Neural Network (8 layers) — extremely deep by the standards of the time
- GPU Parallel Computing — trained on 2 NVIDIA GTX 580 GPUs for 6 days
- Large-Scale Data — 1.2 million ImageNet training images
If ImageNet had existed without AlexNet, or AlexNet without ImageNet — the deep learning revolution would not have happened with just one of the two. After that, history moved fast.
By the time ILSVRC ended, ImageNet had become more than a competition tool — it was the common lingua franca of the deep learning era. Thousands of papers worldwide were built on ImageNet pre-trained models, and the phrase "pre-trained on ImageNet" became an idiom in AI papers.
The Dataset — 1,431,167 Images and 1,000 Worlds

▲ ImageNet collage — an image mosaic of 1,000 classes including dogs, cats, vehicles, instruments, and more
Data source: image-net.org (Stanford Vision Lab) · DataClinic report: #123
The ImageNet diagnosed by DataClinic is a dataset of 1,431,167 images total, comprising 1,281,167 training images + 50,000 validation images + approximately 100,000 test images for ILSVRC.
The 1,000 classes follow WordNet's hierarchical structure and encompass a vast world. Animals (dogs, cats, birds, fish, insects, reptiles), plants, food, instruments, vehicles, furniture, sports equipment, and man-made tools — literally a cross-section of the world.
Of these, 120 classes are dog breeds. Pomeranian, Siberian Husky, Golden Retriever, Dalmatian, Bulldog, Chihuahua, Beagle, Dachshund... The fact that 12% of all classes are dog breeds later turns out to be the cause of the 'one massive high-density cluster' that DataClinic discovers.






▲ L1 class mean images — the result of pixel-wise averaging all images in each class. Sharpness indicates visual consistency.






▲ Notice how the Sports Car and Convertible mean images are similarly blurry. The visual boundary between these two classes is ambiguous.
Level 1: Basic Quality Check — The Secret Behind a Score of 60
Level 1 is a pixel-level basic health check. DataClinic evaluates four aspects: image integrity, missing values, class balance, and statistical measurement.
| Evaluation Item | Grade | Details |
|---|---|---|
| Image Integrity | ✅ Good | 98.43% RGB, 1.57% Grayscale, RGBa 0.0% |
| Missing Values | ✅ Good | No missing values |
| Class Balance | ✅ Good | Mean 1,281 images, Std Dev 70.2 |
| Statistical Measurement | ❌ Poor | Low image diversity |
🔍 Statistical Measurement: Poor — What It Means
Among otherwise good grades, statistical measurement was the only one rated 'Poor'. DataClinic's statistical measurement evaluates the diversity of pixel distributions within classes. A low score means many images share similar color distributions, brightness, and composition.
There are structural reasons for this phenomenon:
- The 120 Dog Breed Effect — 12% of classes are dog breeds. Pet photos with similar lighting, backgrounds, and poses homogenize the pixel distribution.
- Crawling Bias — Internet image crawling tends to over-collect photos with specific styles (JPEG compression, bright lighting, centered subjects).
- Limitations of the Era — Internet images from the late 2000s were dominated by certain photography styles, quite different from today's diverse smartphone photography environments.
📏 Resolution: From 20×17px to 7,056×4,488px
The range of image sizes is extremely wide. The minimum of 20×17px is practically unidentifiable, while the maximum of 7,056×4,488px is a high-resolution DSLR photo. This gap is inevitable given the data collection method (internet crawling), which is why resolution standardization (typically 224×224px) is essential during training.
Additionally, 1.57% of images are Grayscale, amounting to approximately 22,500 images. Standard models that assume RGB 3-channel input (AlexNet, ResNet, etc.) require special handling for these images.
Level 2: Feature Space Analysis — One Giant Cluster
Level 2 analyzes the feature space of the entire dataset using Wolfram ImageIdentify Net V2 (1,280 dimensions). Each of the 1,431,167 images is converted into a 1,280-dimensional vector, and their distribution is observed.
🔵 Key Finding: 1 High-Density Cluster
DataClinic's most notable finding is that "1 distinct high-density cluster exists". Data from 1,000 classes is not evenly distributed in the feature space; instead, an extremely dense mass forms in a specific region.
What is the identity of this cluster? It becomes clear when we look at the data composition. Of ImageNet's 1,000 classes, 120 are dog breeds, and when combined with cats, birds, and small animals, roughly 25-30% are animal classes. Images of these animals — photos taken in similar settings like lawns, indoors, couches, and yards with similar compositions — have feature vectors that are very close to each other from a general-purpose neural network's perspective.

▲ L2 PCA — mean feature vectors of 1,000 classes projected to 2D. A dense cluster is visible in the upper right.
📊 Overall Density Distribution: Bell-shaped — But Skewed
The overall density distribution maintains a bell-shaped curve, but a distribution with significant deviation from the mean is observed. This means that the distribution's tail is skewed to one side due to the high-density cluster. The density gap between high-density regions (animal cluster) and low-density regions (rare and unique classes) is substantial.
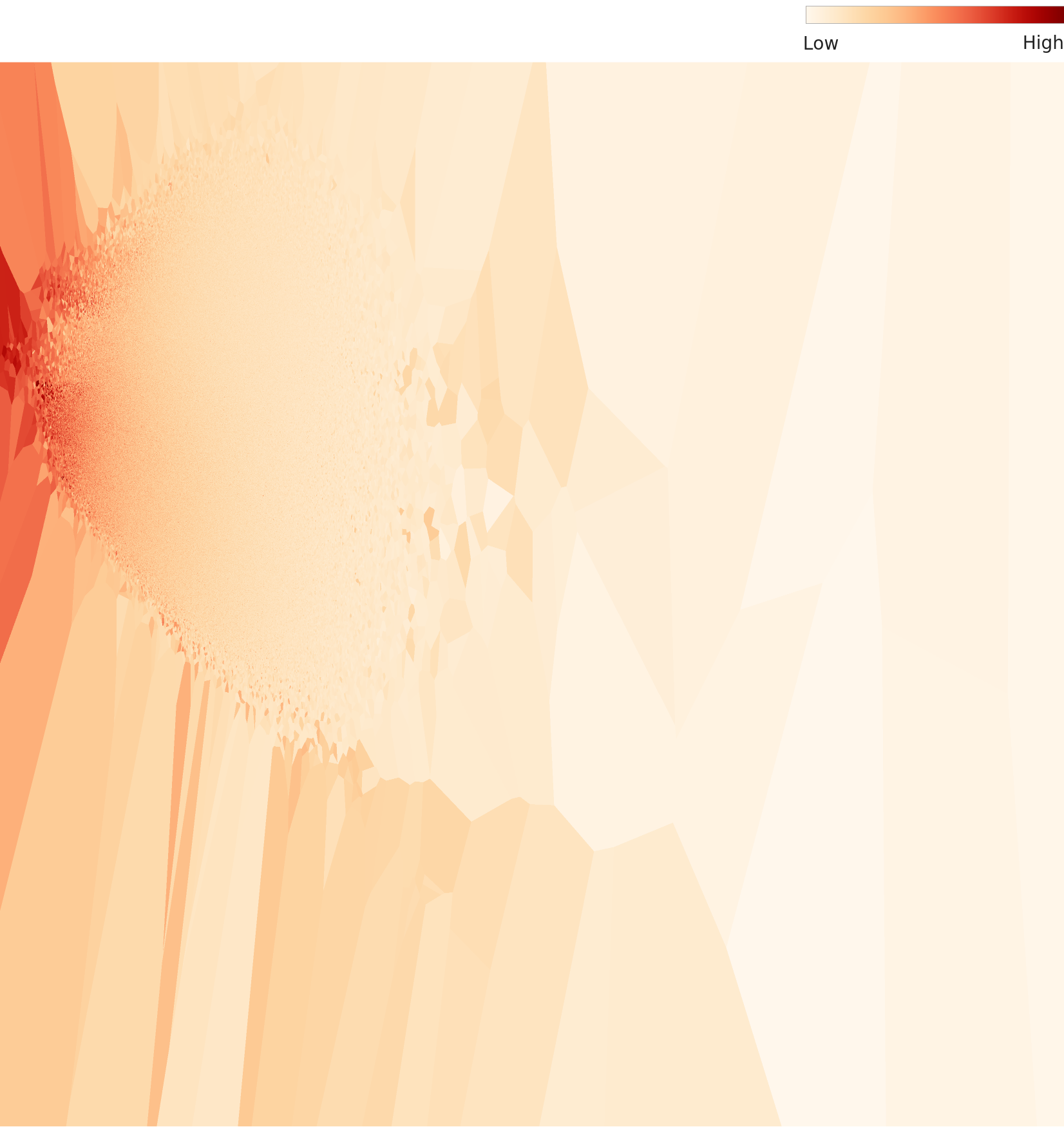
▲ L2 overall density distribution. Maintains bell shape but shows asymmetry with significant deviation from the mean.
🔬 Per-Class Density Comparison
Comparing density distributions by class reveals stark differences:






▲ L2 per-class density distributions. Dalmatian and Tench show high density, while Scorpion shows low density.
Level 3: Domain-Optimized Lens — Precision Observation in 122 Dimensions
Level 3 applies a 122-dimensional lens optimized for the ImageNet dataset on top of the same Wolfram ImageIdentify Net V2 backbone. Reducing from 1,280 to 122 dimensions reveals the dataset's inherent structure more clearly.
🎯 What L3 Reveals
L3 results reinforce the same conclusions as L2. The single high-density cluster persists, and outliers are observed. This carries an important implication — ImageNet's inherent structural issues (excessive dog breed clustering, similar class crowding) do not disappear even when dimensions change.

▲ L3 PCA (122 dimensions). Cluster structures are more clearly separated compared to L2.



Confusing Classes — The Dilemma of 120 Dog Breeds
One of ImageNet's most famous design controversies is the dog breed problem. Following WordNet's hierarchical classification, 120 visually very similar breeds — Dalmatian, Siberian Husky, Malamute, Alaskan Klee Kai, and more — are separated into distinct classes.
🐟 Tench vs. Goldfish — Twins of the Water
This is a classic case of classification confusion. In ImageNet, tench (a freshwater fish of the carp family) is photographed in a remarkably specific way — photos of anglers holding fish in their hands dominate. As a result, models end up identifying not "tench" but "the scene of an angler holding a fish."
Goldfish, in contrast, is dominated by images inside glass fishbowls. The photographic context becomes a stronger signal than the biological differences between the two fish. This is a prime example of Context Bias — where AI learns background rather than the essence of the subject.
Tench — in angler's hands
Goldfish — in a fishbowl
▲ The difference between the two fish mean images reflects the difference in photography environment more than biological differences.
🚗 Sports Car vs. Convertible — The Absence of a Sharp Boundary
A convertible (open-top sports car) is a subconcept of sports car. A sports car with an open roof is both a convertible and a sports car. In fact, according to a Stanford research team's analysis, sports car and convertible are among the most frequently confused class pairs in ImageNet. The nearly identical mean images of the two classes below prove this.
Sports Car
Convertible
▲ The mean images of these two classes are visually indistinguishable to the naked eye. Models feel the same way.
🐯 Tiger vs. Tabby Cat — The Stripe Trap
Tiger and Tabby Cat belong to the same feline family and share similar stripe patterns. Although image sizes and backgrounds differ, these two classes are closer than expected in feature space. A close-up of a cat face can have a feature vector very similar to a tiger.
📌 Limits of Fine-grained Recognition
Many of ImageNet's 1,000 classes inherently involve Fine-grained Recognition challenges. 120 dog breeds, various feline species, vehicle types... Teaching AI to learn boundaries that "even humans find difficult to distinguish" is fundamentally hard without high-quality labels and diverse training data. The 'high-density cluster' discovered by DataClinic is a direct reflection of these fine-grained classes excessively overlapping in feature space.
Outlier Analysis — The Extremes of Data
DataClinic uses density-based outlier analysis to identify high-density (typical) and low-density (atypical) samples in each class. In ImageNet, outliers are often not simple data errors — they are windows that reveal the limits of labeling philosophy.
🏆 High Density — Classes Where Context Dominates the Label
High-density samples — the most 'typical' images in each class — are often determined by photographic context rather than the class label:
- Tench — The majority of high-density images show anglers holding fish. Human hands become a more important feature than the fish itself. In this class, a photo of tench in a fishbowl actually becomes an 'outlier.'
- Banana — Yellow banana bunches on store shelves are typical. Green bananas on trees or half-cut bananas are low-density outliers.
- Dalmatian — Standing dalmatians in side-profile shots with black spots on white are high-density. A dalmatian next to a fire truck — despite the cultural association — can become an outlier.
⚠️ Low Density — The Most Interesting Images
Low-density outliers fall into two groups:
(1) Genuine Label Errors — Misclassified images. According to one study (Northcutt et al., 2021), approximately 6% of the ImageNet validation set contains label errors. Examples:
- A Welsh Corgi dog photo tagged with the "cardigan" label → confusion between Cardigan Welsh Corgi (dog breed) and cardigan (clothing)
- An image labeled "stretcher" → contains a stretching frame (canvas stretcher) instead of a medical stretcher
- Images with multiple subjects where the intended label subject is in the corner
(2) Genuine Diversity — Atypical but correctly labeled. These images are not candidates for deletion but opportunities for improving model robustness. DataClinic's outlier analysis guides users to distinguish between these two groups through manual review.
🔬 DataClinic Finding: Distribution Range of Outliers
In the L2 analysis, density ranges are observed as high-density 0.079-0.344 and low-density 0.023-0.054. This range shows that even though ImageNet is a single dataset, it has extremely different internal cohesion across classes. DataClinic's improvement recommendations are to remove high-density duplicates with Data Diet and reinforce low-density regions with Data Bulk-up.
Duplicates and Label Noise — The Hidden Quality Crisis
DataClinic structurally exposes the two quality issues that remained buried the longest in ImageNet — duplicate images and label noise.
📋 Train-Test Image Overlap (Data Leakage)
The analysis by the Stanford/MIT research team (Recht et al., 2019) was shocking. A significant number of images in the ImageNet validation set (50,000 images) also existed in the training set, or were essentially different crops of the same image. This is known as 'Data Leakage'.
A more systematic study (Barz & Denzler, 2020) found 12,195 pairs of near-duplicate images in ImageNet. These duplicates include:
- Different crop/resize versions of the same image
- Burst shots of the same subject
- Mirrored or slightly edited versions
DataClinic's Data Diet recommendation most directly targets these duplicate images. Removing nearly identical images within high-density clusters allows models to learn more diverse patterns.
🏷️ Label Noise: 6% Error Rate
The study by Northcutt et al. (2021) from Cornell AI Lab found approximately 6% label errors in the ImageNet validation set. That is about 3,000 images out of the 50,000 in the validation set. Major error types:
- Multi-label Problem — When an image contains multiple objects, the question of 'which one is the answer.' In a dog + frisbee image, neither "Labrador Retriever" nor "Frisbee" alone can be the correct answer.
- Hierarchical Label Ambiguity — "Persian cat" and "tabby" can be simultaneously valid. Some Persian cats have tabby stripe patterns.
- WordNet Inconsistency — "Cardigan" has two meanings: 'Cardigan Welsh Corgi (dog breed)' and 'cardigan (knit garment),' causing confusion.
💡 The Paradox of Label Noise
Interestingly, ResNet trained on ImageNet with 6% label errors achieved 97%+ accuracy. This is one of deep learning's remarkable properties — with sufficiently large-scale data, a certain degree of label noise is naturally averaged out during training. However, this does not mean label quality can be neglected. In small-scale domain-specific datasets, label noise is fatal.
The Evolution of AI Data — From ImageNet to Physical AI
ImageNet was the largest dataset of its time in 2009. By 2026 standards, it is a relatively small dataset. How have AI datasets evolved?
🔮 What the Paradigm Shift Tells Us
The journey from ImageNet to Physical AI data reveals three fundamental changes:
(1) The Liberation of Labels — Manual labels (ImageNet) → weak labels → self-supervised learning. AI has evolved toward learning meaning without labels. Yet even in the LLM era, the value of high-quality curated data (human feedback for RLHF) has actually increased.
(2) From Closed World to Open World — ImageNet's 1,000 classes assume a 'Closed World.' GPT-4V describes any image without a class list. The boundaries of datasets have vanished.
(3) From Digital to Physical Interaction — Physical AI faces problems ImageNet never solved. Data about a robot grasping an object cannot be collected with cameras alone. Tactile information like force, resistance, and surface texture is needed. The data quality challenges of the next decade exist in an entirely different dimension from ImageNet.
📐 DataClinic's Role: What Every Era Needs
No matter how much datasets evolve, the need for data quality diagnosis never disappears. ImageNet's 6% label errors, high-density clusters, and train-test overlap were problems in 2009, and LAION-5B's NSFW content contamination, bias in LLM training data, and collection distribution imbalances in Physical AI data are problems of the same essence. The tools change, but the question remains the same: "What problems exist in my data?"
Conclusion — An Imperfect Dataset That Sparked a Perfect Revolution
DataClinic gave ImageNet a score of 60 (Fair). This might seem harsh for a dataset that ignited the deep learning revolution. But this is precisely the core value of DataClinic — it evaluates based solely on data quality standards, not historical stature.
In fact, the score of 60 is a kind of paradox. ImageNet's quality issues — lack of statistical diversity, high-density clusters, duplicate images, and 6% label noise — are also evidence that this dataset worked too well. It was only as algorithms and GPUs advanced that the dataset's limitations finally became visible.
📊 Diagnosis Results at a Glance
| Item | Result | Key Implication |
|---|---|---|
| Overall Score | 60 (Fair) | Objective quality assessment regardless of historical status |
| L1 Statistics | Poor | Lack of image diversity — dog breed cluster effect |
| High-Density Cluster | 1 | 120 dog breeds + similar animal classes crowded together |
| Label Noise | ~6% | Inevitable result of large-scale crowdsourcing |
| Improvement Direction | Diet + Bulk-up | Remove high-density duplicates + reinforce low-density areas |
Explore more dataset quality diagnostics and learn how to use DataClinic at dataclinic.ai.