Executive Summary
2025년 8월, Lancet Gastroenterology & Hepatology에 폴란드 4개 내시경 센터를 추적한 연구가 실렸습니다. AI 보조 도구를 도입하기 전, 의사들이 AI 없이 검사할 때의 선종 발견율은 28.4%였습니다. 도구를 들인 뒤, 같은 의사들이 다시 AI 없이 검사하자 발견율은 22.4%로 떨어졌습니다. AI를 쓸 때가 아니라, AI를 잠시 뗀 순간에 실력이 줄어 있었습니다. 의학에서 자동화로 인한 숙련 저하가 환자 결과에 직접 연결된 첫 실증입니다.
메커니즘은 단순합니다. 도구가 대신 봐 주면 사람이 직접 보는 연습이 줄고, 연습이 줄면 감각이 무뎌집니다. 같은 신호는 방사선과와 병리과에서도 잡혔습니다. 잘못된 AI 제안에 숙련 전문의도 끌려가고, 시간에 쫓기면 처음의 정답 판단을 뒤집습니다. 그리고 이 현상은 내시경실 안에만 머물지 않습니다. AI 출력을 검수하는 사람이 무뎌지면, 라벨과 정답과 품질 기준을 떠받치던 인간 기준선도 함께 흐려지기 때문입니다.
그래서 질문은 하나로 좁혀집니다. '휴먼 인 더 루프'는 루프 안에 사람을 끼워 넣기만 하면 작동하는 장치일까요, 아니면 그 사람의 숙련을 따로 지켜야 비로소 작동하는 장치일까요. 디스킬링 연구는 후자라고 답합니다.
주요 수치
출처: Lancet Gastroenterology & Hepatology, ThePrint
28% → 22%
AI 없이 검사한 선종 발견율
AI 도구 도입 전후, 의사 단독 진단의 변화 (28.4% → 22.4%)
6.0%p
절대 감소폭
의학 최초로 디스킬링이 환자 결과에 연결된 수치
77%
역량 상실을 우려한 의사
AI 과의존으로 임상 감각이 무뎌질까 걱정 (2026년 설문)
10 → 38%
임상 AI 일일 사용률
한 해 만에 약 4배 증가, 우려보다 빠른 의존 속도
AI를 떼자 의사가 더 많이 놓쳤다
연구의 무대는 폴란드의 내시경 센터 네 곳이었습니다. AI 폴립 검출 도구를 일상적으로 들여놓은 곳들입니다. 연구진은 도구가 들어오기 전 3개월과 들어온 뒤 3개월을 비교하되, 한 가지를 따로 봤습니다. AI를 켜고 한 검사 말고, AI를 끄고 의사가 혼자 한 검사만 골라낸 것입니다. 도구를 가진 의사가 도구 없이 일할 때 무엇이 달라지는지를 보려는 설계였습니다.
결과는 한 방향이었습니다. AI 도구가 들어오기 전, 의사들이 맨눈으로 찾아낸 선종 발견율은 28.4%였습니다. 도구가 들어온 뒤 같은 조건, 그러니까 AI를 끈 검사에서 발견율은 22.4%로 내려갔습니다. 절대치로 6.0%포인트가 빠진 셈입니다. 선종 발견율은 대장암 예방에서 가장 신뢰받는 품질 지표 가운데 하나라, 이 6%포인트는 단순한 통계가 아니라 놓친 병변의 수로 환산됩니다.
흥미로운 대목은 AI를 켰을 때의 숫자입니다. 도구를 켠 검사의 발견율은 25.3%로, 도구가 메워 주는 동안에는 성적이 유지됐습니다. 도구가 능력을 끌어올린 것은 맞습니다. 다만 그 능력은 의사의 몸에 남지 않고 도구에 얹혀 있었습니다. 도구를 빼는 순간, 늘어난 줄 알았던 능력이 실은 줄어 있었던 것입니다.
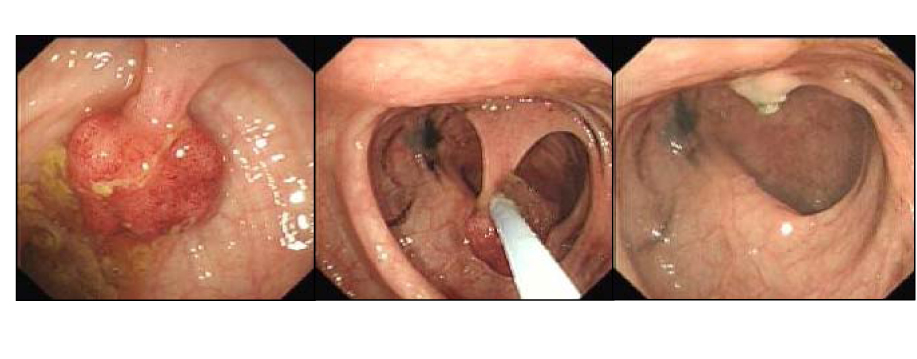
핵심: AI를 켜면 25.3%, AI를 끄면 22.4%. 도구가 능력을 보태 준 것은 맞지만, 그 능력은 사람이 아니라 도구에 저장돼 있었습니다. 의학에서 자동화 디스킬링이 환자 결과로 측정된 첫 사례입니다.
왜 무뎌지는가
무뎌지는 길은 두 갈래로 나 있습니다. 하나는 연습의 공백입니다. 화면 한쪽에서 AI가 의심 병변에 네모를 그려 주면, 의사는 자기 눈으로 점막을 훑는 긴장을 조금씩 내려놓게 됩니다. 매 검사가 곧 훈련인데, 그 훈련의 강도가 낮아집니다. 다른 하나는 자동화 편향(automation bias)입니다. 기계가 답을 내밀면 사람은 그 답을 의심하기보다 따르는 쪽으로 기웁니다.
이 편향은 내시경실 밖에서도 관찰됐습니다. 2026년 3월 ESMO 학술지에 실린 스코핑 리뷰를 보면, 유방 영상을 읽는 방사선과 전문의 27명에게 일부러 틀린 AI 제안을 보여 주자 위양성 재검 비율이 최대 12% 늘었습니다. 숙련된 전문가도 잘못된 기계 신호에 끌려갔다는 뜻입니다. 병리과에서는 시간 압박 아래 틀린 AI 제안을 받은 참가자의 30% 이상이 처음에 내린 정답 진단을 뒤집었습니다.
디스킬링은 한 곳에서만 일어나지 않습니다. 같은 리뷰는 디스킬링이 세 층위에서 진행된다고 정리합니다. 첫째, 쓰던 사람이 연습 부족으로 기존 역량을 조금씩 잃습니다. 둘째, 처음 배우는 사람은 AI가 대신해 주는 일을 아예 배우지 않아 새 역량이 자라지 않습니다. 셋째, 그렇게 한 세대가 지나면 그 역량을 몸으로 기억하는 사람이 직업군 전체에서 사라집니다. 영국이 자궁경부 세포검사를 HPV 1차 선별로 바꾸자 검사 물량이 80% 넘게 줄고 실험실이 45곳에서 8곳으로 통합되면서, 판독 역량의 훈련 기반 자체가 무너진 사례가 셋째 층위에 해당합니다.
현장은 이 위험을 이미 감지하고 있습니다. 2026년 6월 미국 의료진을 대상으로 한 설문에서 의사 77%, 간호사 70%가 AI 과의존으로 자기 역량이 무뎌질까 걱정한다고 답했습니다. 그런데 같은 기간, 임상 현장의 AI 일일 사용률은 10%에서 38%로 약 4배 뛰었습니다. 걱정의 속도보다 의존의 속도가 빠릅니다.
의료만의 문제가 아니다
내시경 의사를 데이터 라벨러로, 폴립 검출 모델을 자동 어노테이션 도구로 바꿔 읽어 보면 이야기가 낯설지 않습니다. AI를 검수하는 사람이 일하는 거의 모든 자리에 같은 구조가 깔려 있기 때문입니다. 데이터 어노테이션, 콘텐츠 모더레이션, 모델 출력 검토, 코드 리뷰. 사람이 마지막에 한 번 봐 주기로 한 일들입니다.
문제는 그 사람의 판단이 모델을 떠받친다는 데 있습니다. AI 훈련 데이터의 품질은 결국 사람 라벨러의 독립적인 판단력에서 나옵니다. 그런데 자동 어노테이션이 먼저 답을 채워 주고 사람은 확인만 하는 구조가 되면, 라벨러의 판단은 검사받는 자리에서 추인하는 자리로 내려앉습니다. 내시경 의사가 AI 네모를 따라 시선을 옮기던 것과 같은 일이, 라벨링 화면에서도 벌어집니다.
이 침식이 위험한 이유는 되먹임 때문입니다. 사람이 무뎌진 채로 통과시킨 라벨이 다음 모델의 정답이 되고, 그 모델의 출력을 다시 무뎌진 사람이 검수합니다. AI가 만든 데이터로 AI를 학습시키며 다양성과 사실성이 조금씩 닳는 모델 붕괴(model collapse)는 그 극단입니다. 자동화가 인간의 판단을 없애는 것이 아니라 슬그머니 이전(shift)시킨다는 점, 그래서 판단이 사라진 자리를 아무도 지키지 않게 된다는 점이 핵심입니다.
같은 구조: AI 출력을 검수하는 사람의 감각이 흐려지면 라벨·정답·품질 기준을 떠받치던 인간 기준선(human baseline)도 함께 흐려집니다. 검수자가 무뎌진 파이프라인은 오류를 걸러 내는 것이 아니라 통과시킵니다.
사람만 끼우면 되는가
'휴먼 인 더 루프'는 보통 안전장치로 불립니다. 법적으로도 운영상으로도 "마지막에 사람이 한 번 본다"는 조건이 책임의 근거가 됩니다. 그런데 디스킬링 연구는 이 안전장치의 전제를 건드립니다. 루프 안의 사람이 AI에 기대며 무뎌지면, 사람이 자리에 있어도 검수는 빈 의식이 됩니다. STAT News의 심혈관 펠로우 Vishal Khetpal은 이를 의료계의 "자동 조종 순간"이라 부르며, AI를 감독할 준비가 안 된 사람에게 책임만 넘기는 구조를 지적했습니다.
그러니 '사람을 끼워 넣는 것'과 '사람의 숙련을 유지하는 것'은 다른 과제입니다. 앞은 구조의 문제이고, 뒤는 역량의 문제입니다. 휴먼 인 더 루프를 안전장치로 쓰려면 두 번째 과제를 따로 설계해야 합니다. 다행히 방향은 의료계가 먼저 제시하고 있습니다.
- • AI-off 드릴: AI를 끄고 정기적으로 맨눈 진단을 연습해, 도구에 얹힌 능력을 사람 몸으로 되돌립니다.
- • 감독 역량의 별도 훈련: AI를 쓰는 법이 아니라 AI를 의심하고 판정하는 법을 따로 가르칩니다. 검수자의 일은 추인이 아니라 검증입니다.
- • 기준선의 정기 측정: 라벨러·검수자의 독립 판단 정확도를 주기적으로 잽니다. 무뎌짐은 천천히 오므로, 측정하지 않으면 보이지 않습니다.
시라큐스대 정보과학자 Kevin Crowston의 말이 이 설계의 원칙을 압축합니다. 어떤 역량을 유지하고 어떤 역량을 도구에 위임할지를 의식적으로 골라야 한다는 것입니다. 위임 자체가 문제는 아닙니다. 무엇을 위임하는지 모른 채 위임하는 것이 문제입니다.
Editor's Note
페블러스가 "사람이 AI의 마지막 검수자"라고 말할 때, 그 문장의 무게는 검수자의 숙련에 걸려 있습니다. 좋은 데이터 위에서만 좋은 모델이 자라듯, 무뎌지지 않은 사람 위에서만 검수가 검수로 작동합니다. 디스킬링 연구가 우리에게 돌려주는 숙제는 분명합니다. 루프에 사람을 넣는 일과, 그 사람을 날카롭게 지키는 일을 같은 비중으로 설계하는 것입니다.
참고문헌
학술 논문
- 1.Budzyń, K. et al. (2025). "Endoscopist deskilling risk after exposure to artificial intelligence in colonoscopy: a multicentre, observational study." The Lancet Gastroenterology & Hepatology. — 폴란드 4개 센터 ACCEPT 트라이얼, AI 미지원 ADR 28.4% → 22.4%.
- 2.ESMO Real World Data and Digital Oncology. (2026). "Artificial intelligence in medicine: a scoping review of the risk of deskilling and loss of expertise among physicians." — 방사선과 위양성 +12%, 병리과 30% 진단 번복, 디스킬링 3층위 정리.
- 3.PMC. (2025). "Deskilling dilemma: brain over automation." PubMed Central. — 디스킬링이 개인·신규·직업 전체 세 지점에서 발생하는 메커니즘.
보도·논평
- 4.Khetpal, V. (2025, 11월 19일). "Medical AI has a 'human in the loop' problem." STAT News. — '의료계의 자동 조종 순간'과 휴먼 인 더 루프의 책임 이양 구조.
- 5.ThePrint. (2026, 6월). "77% of doctors scared of losing their skills due to AI." — 의사 77%·간호사 70% 우려, 임상 AI 일일 사용 10%→38%.