Executive Summary
In August 2025, The Lancet Gastroenterology & Hepatology published a study that tracked four endoscopy centers in Poland. Before an AI assistance tool was introduced, the adenoma detection rate when doctors worked without AI was 28.4%. After the tool arrived, those same doctors examining again without AI saw their detection rate fall to 22.4%. The skill had eroded not while they were using AI, but in the moment they set it down. It is the first real-world evidence in medicine that automation-driven skill loss connects directly to patient outcomes.
The mechanism is simple. When a tool looks on your behalf, you practice looking less, and as practice fades the senses dull. The same signal turned up in radiology and pathology. Even seasoned specialists are pulled along by a wrong AI suggestion, and under time pressure they overturn their own correct first call. And this phenomenon does not stay inside the endoscopy suite: when the person reviewing AI output goes dull, the human baseline that holds up labels, ground truth, and quality standards goes dull with them.
So the question narrows to one. Is "human in the loop" a safeguard that works simply by inserting a person into the loop, or one that works only if that person's skill is kept sharp on its own? The deskilling research answers: the latter.
Key Figures
Source: Lancet Gastroenterology & Hepatology, ThePrint
28% → 22%
Adenoma detection without AI
Doctors working alone, before vs. after the AI tool (28.4% → 22.4%)
6.0 pts
Absolute decline
First time deskilling is tied to patient outcomes in medicine
77%
Doctors who fear skill loss
Worried AI over-reliance is dulling their clinical sense (2026 survey)
10 → 38%
Daily clinical AI use
Roughly 4× in a year — dependence outpacing the worry
They Missed More Once the AI Was Off
The setting was four endoscopy centers in Poland, all of which had brought AI polyp-detection tools into routine use. The researchers compared the three months before the tools arrived with the three months after, but they isolated one thing in particular. Not the exams run with AI switched on, but only the exams a doctor performed alone, with the AI switched off. The design was built to see what changes when a doctor who has the tool works without it.
The result pointed one way. Before the AI tool arrived, the adenoma detection rate doctors reached with the naked eye was 28.4%. After it arrived, under the same condition — exams with the AI off — the rate dropped to 22.4%. That is 6.0 percentage points gone in absolute terms. Adenoma detection rate is one of the most trusted quality metrics in colorectal cancer prevention, so those 6 points are not a bare statistic; they translate into missed lesions.
The telling part is the number with AI switched on. In exams run with the tool, the detection rate was 25.3% — performance held while the tool filled the gap. The tool did raise the doctors' capability. But that capability did not stay in the doctors' hands; it sat on the tool. The moment the tool was removed, the capability they thought had grown turned out to have shrunk.
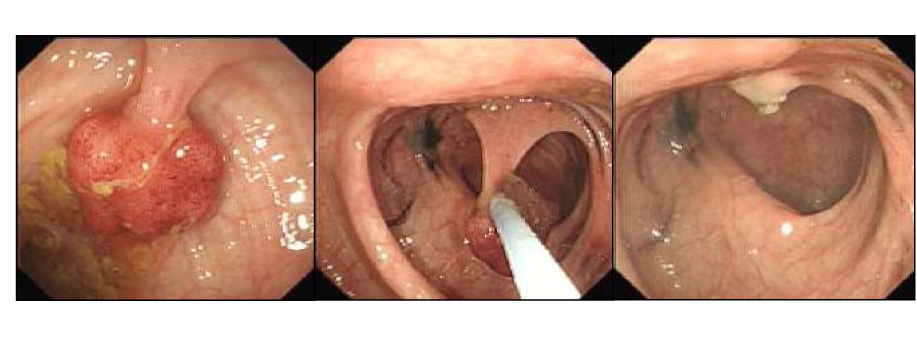
The point: 25.3% with AI on, 22.4% with AI off. The tool did add capability, but that capability was stored in the tool, not the person. It is the first case in medicine where automation deskilling was measured in patient outcomes.
Why the Edge Dulls
The path to dulling runs in two directions. One is the gap in practice. When AI draws a box around a suspicious lesion on one side of the screen, the doctor gradually eases off the tension of scanning the mucosa with their own eyes. Every exam is a training rep, and the intensity of that training drops. The other is automation bias. When a machine offers an answer, people lean toward following it rather than doubting it.
This bias has been observed outside the endoscopy suite too. A scoping review published in an ESMO journal in March 2026 found that when 27 radiologists reading breast images were deliberately shown wrong AI suggestions, their false-positive recall rate rose by up to 12%. Skilled experts, in other words, were pulled along by a wrong machine signal. In pathology, more than 30% of participants who received a wrong AI suggestion under time pressure reversed the correct diagnosis they had made at first.
Deskilling does not happen in one place only. The same review frames it as advancing on three levels. First, those already working lose existing competence bit by bit through lack of practice. Second, newcomers never learn the work AI does for them, so the new competence never grows. Third, once a generation passes that way, the people who carry that competence in their hands disappear from the profession entirely. When the UK switched cervical cytology to HPV primary screening, test volume fell by more than 80% and labs consolidated from 45 down to 8 — a case where the very training base for reading skill collapsed, the third level made concrete.
The field already senses the risk. In a June 2026 survey of US clinicians, 77% of doctors and 70% of nurses said they worried AI over-reliance would dull their own competence. Yet over the same stretch, daily AI use in clinical settings jumped from 10% to 38%, roughly fourfold. Dependence is moving faster than the worry.
Not a Medicine-Only Problem
Swap the endoscopist for a data labeler and the polyp-detection model for an auto-annotation tool, and the story is not unfamiliar. The same structure underlies almost every seat where someone reviews AI. Data annotation, content moderation, model-output review, code review — the jobs we decided a person would look at one last time.
The trouble is that this person's judgment is what holds up the model. The quality of AI training data comes, in the end, from the independent judgment of human labelers. But once auto-annotation fills the answer in first and the human only confirms it, the labeler's judgment sinks from a seat that examines to a seat that rubber-stamps. The very thing the endoscopist did when their gaze followed the AI's box happens on the labeling screen too.
What makes this erosion dangerous is the feedback. A label that a dulled person waves through becomes the ground truth for the next model, and a dulled person reviews that model's output in turn. Model collapse — where AI trains on AI-made data while diversity and factuality wear down bit by bit — is the extreme of this. The key is that automation does not erase human judgment so much as quietly shift it, and so no one is left guarding the spot where judgment used to be.
The same structure: when the senses of the person reviewing AI output blur, the human baseline that held up labels, ground truth, and quality standards blurs with them. A pipeline whose reviewer has gone dull does not filter errors out — it passes them through.
Is Adding a Person Enough?
"Human in the loop" is usually called a safeguard. Legally and operationally, the condition that "a person looks at it one last time" becomes the basis for accountability. But the deskilling research touches the premise of that safeguard. If the person in the loop leans on AI and goes dull, then even with a person present, the review becomes an empty ritual. STAT News cardiovascular fellow Vishal Khetpal calls this medicine's "autopilot moment," pointing to a structure that hands responsibility to people who are not equipped to supervise AI.
So "inserting a person" and "maintaining that person's skill" are different tasks. The first is a problem of structure; the second is a problem of competence. To use human in the loop as a safeguard, the second task has to be designed separately. Helpfully, medicine is already pointing the way.
- • AI-off drills: switch the AI off and practice unaided diagnosis on a regular schedule, returning the capability that sat on the tool back into the person.
- • Separate training in oversight: teach not how to use AI but how to doubt it and judge it. The reviewer's job is verification, not endorsement.
- • Regular baseline measurement: periodically measure the independent-judgment accuracy of labelers and reviewers. Dulling arrives slowly, so it stays invisible unless you measure it.
Syracuse University information scientist Kevin Crowston captures the principle of this design: we have to consciously choose which competencies to keep and which to delegate to tools. Delegation itself is not the problem. Delegating without knowing what you are delegating is.
Editor's Note
When Pebblous says "a human is AI's last reviewer," the weight of that sentence rests on the reviewer's skill. Just as good models grow only on good data, review works as review only on top of a person who has not gone dull. The homework the deskilling research hands back to us is clear: design the task of putting a human in the loop and the task of keeping that human sharp with equal weight.
References
Academic Papers
- 1.Budzyń, K. et al. (2025). "Endoscopist deskilling risk after exposure to artificial intelligence in colonoscopy: a multicentre, observational study." The Lancet Gastroenterology & Hepatology. — Four Polish centers (ACCEPT trial), non-AI ADR 28.4% → 22.4%.
- 2.ESMO Real World Data and Digital Oncology. (2026). "Artificial intelligence in medicine: a scoping review of the risk of deskilling and loss of expertise among physicians." — Radiology false positives +12%, 30% of pathologists reversed diagnoses, the three levels of deskilling.
- 3.PMC. (2025). "Deskilling dilemma: brain over automation." PubMed Central. — The mechanism by which deskilling occurs at the individual, novice, and whole-profession levels.
News & Commentary
- 4.Khetpal, V. (2025, November 19). "Medical AI has a 'human in the loop' problem." STAT News. — Medicine's "autopilot moment" and the responsibility-shift in human in the loop.
- 5.ThePrint. (2026, June). "77% of doctors scared of losing their skills due to AI." — 77% of doctors and 70% of nurses worried; daily clinical AI use 10% → 38%.