Executive Summary
While TradingAgents was crossing 60K stars on GitHub, multi-agent LLMs quietly became the default narrative in finance — the most structured domain we have. Then an independent reproducibility study at ACM Fintech 2026 reported that the same system could not consistently beat a plain buy-and-hold strategy. 60K stars verifies that the direction is interesting; it does not verify that the pattern transfers outside finance.
Take the TradingAgents pattern out of finance and drop it into industrial data operations — manufacturing, logistics, healthcare, and the grid. Where does it break? Three findings stand out. First, multi-agent architectures have already converged across domains — specialized roles, central orchestration, tool calls, a verification layer. Second, industry, unlike finance, has no clean post-hoc ground truth: backtesting collapses. Third, none of today's multi-agent infrastructures (LangGraph, DeerFlow, Anthropic Managed Agents) standardize a data-quality assurance layer. The evidence is damning on all three fronts: Shumailov et al. (Nature 2024) showed model collapse triggered by synthetic data at 1/1000 of the training mix; A2A baselines leaked 60–100% of payloads; MCP exhibited 5.5% tool-poisoning surface; 88% of AI pilots fail. Different faces, same root cause.
Pebblous DataGreenhouse and DataClinic are positioned to close that gap. Standardize a data-readiness verification layer on top of MCP and you have an "Agentic Data Operations Quality OS" that any agent ecosystem can call into. Korea's sovereign-AI consortium, CJ Logistics' NextGen AI, Samsung's AI Factory roadmap, and KEPCO's grid paradigm shift are all waiting for the same middleware. The report proposes a triangulated architecture — DeerFlow + DataGreenhouse + domain adapters — and a "complement, not compete" strategy that places Pebblous's quality and trust layer above the orchestrator and LLM camps rather than against them. This piece is the industrial-operations chapter of the Physical AI series — where multi-agent patterns meet manufacturing and logistics, and where they break.
TradingAgents at 60K Stars — The Inflection Point of the Multi-Agent Era
As of May 1, 2026, Tauric Research's TradingAgents repository carried 62,306 stars on GitHub, growing at roughly +2,000 per day. Version 0.2.0 from the same quarter cut single-vendor lock-in by supporting GPT-5, Claude 4, Gemini 3, and Grok 4 in parallel — a multi-provider architecture that accelerated adoption among academic groups and fintech start-ups.
What 60K stars points to is not the romance of "automated trading." The deeper signal is social validation of a generalizable pattern: specialized LLM roles + domain knowledge + multi-round consensus. TradingAgents lays out a five-tier, twelve-agent topology — four Analysts (markets, news, social, fundamentals) → two Researchers (Bull / Bear) → Trader → three Risk Managers → Portfolio Manager. The decision structure of a human hedge fund, mapped directly onto LLMs through debate, consensus, and review.
1.1What the ACM Fintech 2026 Reproducibility Study Exposed
In the same quarter, an independent reproducibility study published at ACM Fintech 2026 reached a different conclusion. TradingAgents could not consistently beat a simple buy-and-hold benchmark. The two limits the authors highlight are sharp — a strong assumption about input data quality, and a tendency for multi-round debate to overfit market noise.
60K stars and an underperformance against buy-and-hold are not contradictions. The first is social validation that "this pattern is worth examining"; the second is the absence of performance validation that "this pattern actually generates alpha." Separating the two is the only way the conversation about industrial transferability becomes possible.
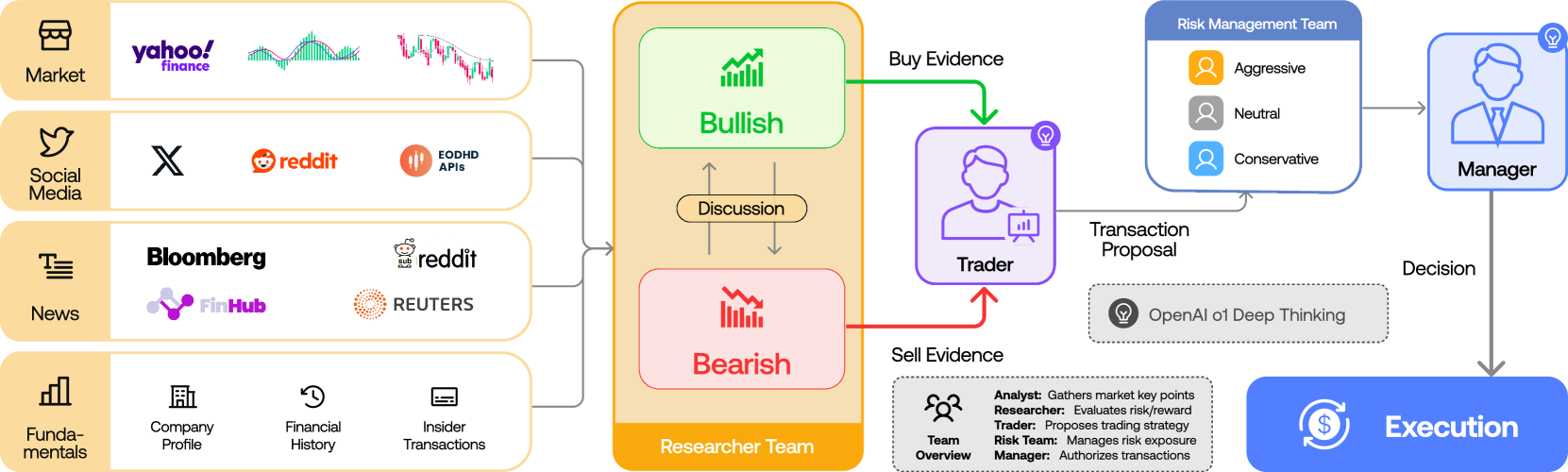
1.2Du et al. 2023's Ceiling and B05's New Warning
The evidence for multi-agent debate is already there. Multi-round debate reduces hallucination and improves factuality compared to a single LLM call — Du et al. showed exactly that at ICML 2024 in a paper they called "Society of Minds." But in November 2025, arXiv 2511.07784 drew a more precise boundary: "the ceiling of debate success is effectively bounded by the strongest participant." A committee of weak LLMs cannot beat a single strong one.
In September 2025, FREE-MAD (arXiv 2509.11035) reported a different asymmetry. When agents calibrate trust between their own outputs and external ones, consensus becomes easier — but reasoning accuracy drops. "Garbage debate, garbage consensus." Multi-agent systems beat single-LLM systems only when the inputs are clean. In industrial settings, that condition is essentially never met.
→ Related Pebblous reading: DeerFlow 2.0 — When the Researcher Becomes a SuperAgent
The Architecture Has Converged — So Why Does It Break in Industry?
Move a multi-agent architecture from finance into an industrial domain and the wall it hits first is not "agent design" — it is the nature of the data the agents receive. The topologies in arXiv Group A (financial papers A01–A06) and Group H (industrial papers H01–H28) are nearly identical: specialized roles + orchestrator + tool calls + reflection layer. Bosch's 2,000-line multi-agent demo, CJ Logistics' NextGen AI, Schneider's One Digital Grid, and MX-AI for 5G Open RAN all share the same backbone. The gap is somewhere else.
One line: architectures have already converged across domains; data readiness is the only thing that still diverges. Lay down the same topology and one side (finance) gets minute-by-minute ground truth from market prices and can backtest, while the other (industry) operates with ambiguous truth and continuously moving distributions. The four-axis table below shows exactly where that divergence lives.
2.1Quantifying the Four Asymmetries
| Dimension | Finance | Industrial Data Operations |
|---|---|---|
| Latency tolerance | Minutes to hours (positions can be re-balanced) | Milliseconds to seconds (grid stability, equipment safety) |
| Ground-truth clarity | Market price arrives as post-hoc truth | Truth is ambiguous; cost of an incident dwarfs cost of training |
| Data heterogeneity | Structured time series and news | Sensors, images, logs, and maintenance records mixed together |
| Distribution stability | Relatively stable outside regime shifts | Constantly moves with seasonality, operating mode, and equipment ageing |
| Regulation | SEC, FINRA, MiFID — broadly horizontal rules | FDA SaMD, EU AI Act high-risk, ISO 42001, NIST AI RMF — domain-specific |
| Post-hoc verification | Backtesting works | Post-incident remediation cost overwhelms learning cost |
arXiv H02 "Cleaning Maintenance Logs with LLM Agents for Improved Predictive Maintenance" (2511.05311) catalogs six noise types that appear almost exclusively in industrial data — non-standard abbreviations, mixed languages, sensor error markers, free-text comments, missing timestamps, and ID mismatches against maintenance catalogs. Finance, for the most part, does not see them.
2.2The Moment Backtesting Stops Working
In finance, "what would this agent system have done with last year's data?" is answerable, minute by minute. In industry, the same question goes silent. Equipment failures happen a handful of times per year, adverse-event reports arrive months later, grid incidents take dozens of hours to reconstruct after the fact. Backtesting has nowhere to run. The only practical alternative is an ex-ante data-quality gate.
That difference is exactly why DataClinic's dual-embedding diagnosis — neural statistics paired with domain rules — is meaningful in industry but not in finance. Finance has a single source of post-hoc ground truth, so statistics alone are enough; industry requires symbolic, rule-based integrity checks running alongside neural statistics.
→ Related Pebblous reading: Kronos — Turning Time Series into Generalizable Tokens
Agents Don't Need a Toolbox — They Need a Data Operating System
The warning arrived in July 2024. Shumailov et al. published "AI models collapse when trained on recursively generated data" in Nature 631(8022):755–759, and the conclusion was blunt: model collapse is triggered when synthetic data accounts for as little as 1/1000 of the training mix. Distribution tails disappear, variance shrinks, and the model converges toward the mean of its own outputs.
3.1Three Compounding Risks of the Self-Learning Loop
In multi-agent industrial operations, the same risk shows up in three forms.
① Physical-integrity violations. When a multi-agent on the manufacturing line mislabels a "sensor anomaly," that label flows into the next round of training data. arXiv D04 "Self-Challenging Language Model Agents" (2506.01716) analyzes how flawed challenger-agent outputs contaminate the executing agent. In an industrial setting, a wrong label becomes permanent and survives into the next quarter's model.
② Cumulative distribution drift. arXiv D05 "Using a Feedback Loop for LLM-based Infrastructure as Code Generation" (2411.19043) put it this way — "for each iteration of the loop, its effectiveness decreases exponentially until it plateaus and becomes ineffective." A system trained on its own outputs pulls the distribution toward itself, and the pulled distribution becomes the next round's training data. In industry, where seasonality, operating modes, and equipment ageing already keep the distribution moving, the gap explodes.
③ Rare-event fossilization. Wrong labels on rare events — accidents, equipment failures, adverse drug events — leave permanent traces. The Stanford-Harvard ARISE 2026 paper made the warning explicit in healthcare: AI-generated medical records flowing into other AI training data create a feedback loop. The same dynamic operates across every industrial domain.
3.2Observability Is Reasoning-Centric — The Data-Centric Layer Is Empty
Today's academic work on multi-agent observability concentrates on reasoning traces — AgentOps (arXiv 2411.05285), AgentTrace, Verifiability-First Agents (2512.17259), TRAIL, MAT-based observability. They all track "how the agent reasoned."
arXiv I11 "MX-AI: Agentic Observability and Control Platform for Open and AI-RAN" (2508.09197) reports a decisive finding from 5G Open RAN operations: "observability quality depended more on retrieval/tool engineering than model size, as the agent consistently reasoned over current state rather than stale data." What controlled observability quality was data freshness, not model size.
The industry is starting to notice the gap. Dynatrace's acquisition of Bindplane (2026-04) and DataBahn's AIDI launch (2026-03) both reinforce the telemetry side, but no one is touching data readiness itself. Data lineage (DataGreenhouse) + agent reasoning trace (LangGraph LangSmith) = the full-stack provenance industrial regulators ask for. A solution that joins both sides does not yet exist on the market.
3.3MCP Is the De-Facto Standard, A2A Is Catching Up — The Middleware Is Empty
MCP (Model Context Protocol) saw over 97 million SDK downloads in Q1 2026, with 9,400+ public MCP servers registered. Eighty-six percent of enterprises use MCP-enabled models. Anthropic, OpenAI, Google, and Microsoft adopted the standard simultaneously, and in December 2025 Google Cloud exposed Maps, BigQuery, Compute Engine, Kubernetes, and AlloyDB as fully-managed remote MCP servers.
A2A (Agent-to-Agent), under the Linux Foundation's Agentic AI Foundation, has 150+ organizations on board and is closing the distance. The 60–100% data leakage that arXiv G06 "Improving Google A2A Protocol" (2505.12490) reported as a baseline has been driven down to 0% with the v1.2 cryptographic-signature scheme. MCP covers the vertical (agent ↔ tools/data); A2A covers the horizontal (agent ↔ agent).
Neither protocol provides a standard for verifying that data readiness was assured before agent invocation. arXiv G02 reports 7.2% generic vulnerabilities and 5.5% MCP-specific tool-poisoning surface in MCP servers. The white space for exposing DataGreenhouse as an MCP server is unmistakable.
→ Related Pebblous reading: hermes-agent's Self-Learning Loop and Data Quality Risk
Manufacturing, Logistics, Healthcare, Energy — Same Topology, Different Failure Points
Four domains, four real deployments — manufacturing, logistics, healthcare, and energy. In every one, data quality is either the principal driver or the principal blocker. Nothing else comes close.
On the surface these four domains look entirely unrelated, but apply a multi-agent pattern and the topology snaps to the same shape: analyst agents split heterogeneous data, a decision agent integrates them, an execution agent issues domain commands (PLC instructions, transport orders, EHR entries, protective-relay sequences). The data-quality challenge wears a different face in each domain — sensor freshness in manufacturing, schema variability in logistics, PHI governance in healthcare, millisecond distribution drift in energy. Walking through the four cases makes the report's central claim concrete: same architecture, different data-readiness standards.
4.1Manufacturing — Bosch / Siemens / Samsung / Hyundai
Bosch unveiled "Manufacturing Co-Intelligence" at CES 2026 — a 2,000-line multi-agent system targeting zero-defect production. Siemens combined GenAI with Senseye in its Industrial Copilot, expanding predictive maintenance. Samsung announced a strategy to convert its global factories to AI-Driven Factories by 2030, and Hyundai showed its AI robotics vision at CES 2026.
arXiv H01 "A Large Language Model-based multi-agent manufacturing system for intelligent shopfloor" (2405.16887) presents a topology that is, in practice, identical to TradingAgents — analyst agents split sensors, images, and logs; a decision agent integrates them; an execution agent issues PLC commands. The bottleneck is data quality. Sensor freshness, image-label fidelity, and maintenance-record consistency must all be guaranteed at once.
4.2Logistics — CJ Logistics / Maersk / DHL / Coupang
CJ Logistics introduced "NextGen AI" at MODEX 2026 as the public signal of its US market entry — a supply-chain replanning platform that pairs multi-agent decisioning with humanoid robotics. arXiv H08 "Agentic LLMs in the Supply Chain" (2411.10184) provides the academic counterpart, with specialized agents handling demand forecasting, inventory placement, transport optimization, and exception handling under a supervisor.
In logistics, the data-quality challenge is schema variability. Each shipper uses a different invoice format, each country a different customs-code system, each carrier a different EDI message. The six noise types H02 found in maintenance logs reappear here, almost line for line.
4.3Healthcare — Abridge / Hippocratic AI / Mayo Clinic
Abridge automates clinical documentation through its AMIA (American Medical Informatics Association) partnership. Hippocratic AI added two new Nurse Co-Pilots. arXiv H14 "A Survey of LLM-based Agents in Medicine" (2502.11211) catalogs eight applications of clinical-decision multi-agents.
The FDA is moving AI medical-device lifecycle management onto Predetermined Change Control Plans (PCCP). The number arXiv J06 reported is jarring — only 2% of FDA-approved AI medical devices report updates with new data. PHI governance, adverse-event label fidelity, and patient-distribution representativeness must all be verified together.
4.4Energy — Schneider / GE / KEPCO
Schneider released its "One Digital Grid" platform in December 2025; KEPCO announced a grid paradigm shift in April 2026. arXiv H21 "Grid-Agent: An LLM-Powered Multi-Agent System for Power Grid Control" (2508.05702) lays out a four-agent topology that splits load forecasting, generation scheduling, anomaly detection, and protection coordination.
In energy, the data-quality challenge is millisecond-scale distribution drift. Korea's grid is an isolated system whose distribution does not appear in the data foreign solutions were trained on. Without enforcement of domain rules — protective-relay sequences, frequency-stability thresholds — a single misjudgement by the multi-agent system can cascade into a wide-area blackout.
→ Related Pebblous reading: A Vision Multi-Agent Workflow with YOLO + LangGraph
Not the Agent, Not the LLM — The Gap in Between
The multi-agent infrastructure market has split into two camps.
Camp A — Orchestrators. LangGraph (46.1M monthly downloads, in production at BlackRock and JPMorgan), DeerFlow 2.0 (sandbox + persistent memory), CrewAI (a 2–3 engineer-day demo), AutoGen (entering maintenance mode). They own the layer that defines, executes, and debugs agent workflows.
Camp B — LLM and tool providers. OpenAI Assistants/Agents SDK, Anthropic Managed Agents (gVisor + MCP secure vault), Google ADK / Gemini Enterprise Agent Platform (Cloud Next '26), and the Microsoft Copilot Stack. They provide the actual reasoning engine and guardrails.
Neither camp occupies the same seat: a layer that assures the quality of the data the agents handle, both before and after invocation. That is Pebblous's seat.
5.1The Data Origin of 88% Pilot Failure
Why is the gap decisive? Forrester's 2026 report decomposed the causes behind an 88% AI pilot failure rate. Read the table through a data-quality lens and the answer is immediate.
Evaluation gap at 64% means "no validation set, or no representative distribution." Governance friction at 57% means "no lineage, no audit trail, no traceable accountability." Model reliability at 51% means "training distribution is misaligned with operational distribution." All three failure modes trace back not to model architecture or algorithm, but to data origin.
| Failure mode | Share | Data-quality root cause |
|---|---|---|
| Evaluation gap | 64% | No validation set / poor distribution representativeness |
| Governance friction | 57% | No data lineage / no audit trail |
| Model reliability | 51% | Training distribution ≠ operational distribution |
McKinsey reports that of the 62% of companies that piloted multi-agent systems, fewer than 10% reached scale. Gartner estimates that bad data quality costs an organization $12.9M per year. In the BARC AI Innovation survey, 40%+ of companies do not trust AI/ML output and 45%+ name data quality as the single biggest obstacle to AI success. "Data-quality debt has become the new technical debt."
5.2The Triangulated DeerFlow + DataGreenhouse + Domain Architecture
The result from arXiv I04 (2601.12560) is striking: a Supervisor / Reviewer topology can reduce hallucination "up to 100%" — but only when the supervisor sees trustworthy data. No matter how elegant the topology, contaminated input collapses the verification effect to zero. That single result is the clearest argument for placing a separate "data-readiness verification layer" above the agent design.
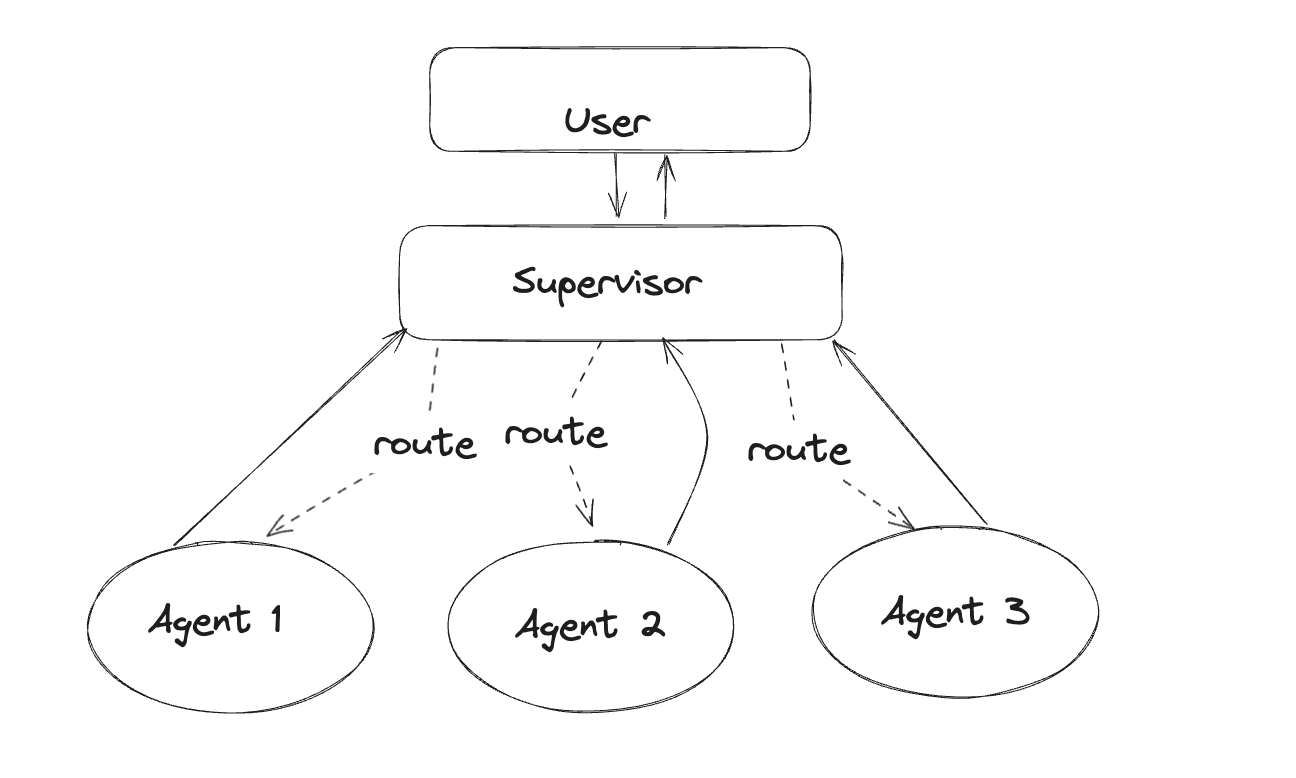
The architecture this report proposes triangulates three axes.
Axis 1 — DeerFlow (or LangGraph). The orchestration layer. Domain agent workflow definition, HITL integration, state persistence. Choose the option in Camp A best suited to industrial operations.
Axis 2 — DataGreenhouse + DataClinic. The data-quality OS layer. A pre-agent gate that verifies input readiness before invocation, and a post-agent gate that filters synthetic versus measured data before re-entry into the self-learning loop. Expose both gates as MCP-standard tools and they become plug-ins for LangGraph, DeerFlow, and Anthropic Managed Agents alike.
Axis 3 — Domain adapters. Domain-specific data-readiness standards for medical imaging, manufacturing vision, logistics IoT, and grid telemetry. The differentiated asset that follows from the strong claim that AI-Ready Data must be domain-specific (arXiv H02).
5.3Pebblous's Short / Mid / Long-Term Roadmap
The triangulated architecture is not built in a single push. Thought leadership → MCP adapters → integrated platform — a three-step gradient that lines up with the "complement, not compete" strategy. Step one is to make the gap visible to the market (2026); step two is to plug the gap as MCP-standard tools so any agent platform can call them (2027); step three is to bind those tools with domain agent recipes into an integrated platform (2028). The table below pairs each step with the market signal that already supports it.
| Horizon | Strategy | Market signal |
|---|---|---|
| 2026 — Short | Thought leadership — "Multi-agent industrial data operations needs a quality OS" | This report; participation in Korea's sovereign-AI consortium proposals |
| 2027 — Mid | Multi-agent adapters on top of DataGreenhouse — DataClinic diagnoses exposed as LangGraph / DeerFlow MCP tools | Pilot deployments at CJ Logistics' NextGen AI and Samsung's AI Factory |
| 2028 — Long | "Agentic Data Operations Platform" — domain agent recipes + DataClinic assurance + DataGreenhouse governance, integrated | Standardized auto-generation of EU AI Act / FDA SaMD / ISO 42001 deliverables |
The core idea is to import the same "complement, not compete" strategy that places PebbloSim on top of NVIDIA Omniverse — straight into the multi-agent space. Korea's sovereign-AI consortium (led by Samsung SDS, with NAVER Cloud, Samsung C&T, Kakao, Samsung Electronics, and KT joining) is the immediate market for that strategy.
→ Related Pebblous reading: AI Scientist V2 — Data-Quality Implications of Autonomous Research Agents
DataGreenhouse Must Evolve Into a Data Sandbox — Now
DataGreenhouse is not a plain data catalog. In the multi-agent era it has to evolve into a "safe agentic data sandbox" — an environment where multiple autonomous agents can touch data without breaking it. Transfer the five-tier, twelve-agent topology TradingAgents demonstrated into an industrial domain, and the moment a layer guaranteeing domain integrity, label fidelity, and distribution stability is missing, the system slips into a hermes-agent-style self-poisoning loop. DataClinic's dual-embedding (neural + symbolic) takes exactly that seat.
6.1Operational Implications — Four Industrial Markets
Pebblous's prospective customer territory and multi-agent industrial adoption overlap almost exactly.
As Korea's sovereign-AI consortium (Samsung SDS leading, with NAVER Cloud, Samsung C&T, Kakao, Samsung Electronics, and KT joining) gets going, demand for a layer that guarantees Korean industrial domain integrity on top of foreign multi-agent infrastructure (LangGraph, DeerFlow, Anthropic Managed Agents) emerges in lockstep. The four areas below are markets where Pebblous DataClinic + DataGreenhouse plug in immediately, and each carries Korean-specific characteristics — isolated grid, customs-code conventions, the FDA-MFDS dual-track regime — that foreign solutions never trained on, and that must be enforced as domain rules.
- • Hyundai Motor / Samsung Electronics / POSCO (Manufacturing) — quality inspection and predictive maintenance. As the same topology shown in the Bosch CES 2026, Siemens Senseye, and multi-vendor Hannover Messe 2026 demos lands in Korean factories, DataClinic owns the ex-ante readiness check.
- • CJ Logistics / Hanjin / Coupang (Logistics) — supply-chain replanning multi-agents combined with humanoid robotics. Travel with MODEX 2026 NextGen AI as it enters the US market and embed a data-readiness standard alongside it.
- • Korean Abridge / Hippocratic AI equivalents (Healthcare) — automated classification of clinical data and adverse-event reports. DataClinic guarantees the decision traceability FDA SaMD and EU AI Act compliance demand.
- • KEPCO / SK Innovation (Energy) — generation and transmission anomaly detection plus grid balancing. When foreign solutions like Schneider's One Digital Grid arrive, enforce Korean grid specificity (the isolated-system property) as a domain rule.
6.2Regulatory Deliverables Are Auto-Generated on Top of Data Lineage
arXiv J04 points out a "persistent gap between high-level legal requirements and concrete verification activities." EU AI Act violations carry penalties of €35M or 7% of global revenue. Yet, according to J02 "2025 AI Agent Index," fewer than 20% of developers publish safety policies and fewer than 10% report external evaluations.
When data lineage (DataGreenhouse) and a transformation audit trail are auto-generated, the factsheets, model cards, and change logs that ISO 42001, EU AI Act, FDA SaMD, and NIST AI RMF require can be produced as side effects. That is not nice-to-have — it is CFO-level risk management. Regulation is not a constraint on Pebblous; it is a market driver for Pebblous.
6.3A Pre-Adoption Checklist for Pebblous
Any organization considering a multi-agent rollout should inspect four data-readiness axes before choosing models or frameworks. The four axes appear, repeatedly, in every academic and industrial failure case this report tracked — distribution stability (Shumailov 2024), label fidelity (D04 Self-Challenging Agents), domain-rule violation (F03 Neuro-Symbolic), and lineage traceability (EU AI Act / FDA SaMD). The five pillars Monte Carlo and Anomalo describe are a starting point — not enough, on their own, for industrial domains.
- • Distribution stability — distance between training and operational distributions. Monte Carlo / Anomalo's five pillars (freshness, volume, schema, distribution, lineage) are the starting line; industrial domains demand more.
- • Label fidelity — is post-hoc verification possible? Label governance such as AnnotationOps is required.
- • Domain-rule violation — is Neuro-Symbolic verification (arXiv F03) applied?
- • Lineage traceability — can ISO 42001 / EU AI Act deliverables be auto-generated?
If your organization needs a data-quality gate for multi-agent industrial operations, the Pebblous Pre-Agent Data Readiness Audit diagnoses all four axes in one pass. Korea's sovereign-AI consortium, manufacturing automation, logistics NextGen, clinical documentation, grid integration — start anywhere.
References
Academic — Financial Multi-Agents
- Y. Xiao, E. Sun, D. Luo, W. Wang, "TradingAgents: Multi-Agents LLM Financial Trading Framework," arXiv:2412.20138 v7, 2025.
- W. Zhang et al., "FinAgent: A Multimodal Foundation Agent for Financial Trading," arXiv:2402.18485, 2024.
- Y. Yu et al., "FinCon," arXiv:2407.06567, NeurIPS 2024.
- Y. Xiao et al., "Trading-R1," arXiv:2509.11420, 2025.
Academic — Multi-Agent Debate
- Y. Du, S. Li, A. Torralba, J. Tenenbaum, I. Mordatch, "Improving Factuality and Reasoning in Language Models through Multiagent Debate," arXiv:2305.14325, ICML 2024.
- "Can LLM Agents Really Debate?" arXiv:2511.07784, 2025.
- Y. Cui, H. Fu, H. Zhang, "FREE-MAD: Consensus-Free Multi-Agent Debate," arXiv:2509.11035, 2025.
Academic — Self-Learning / Model Collapse
- I. Shumailov et al., "AI models collapse when trained on recursively generated data," Nature 631(8022):755-759, 2024.
- "Self-Challenging Language Model Agents," arXiv:2506.01716, 2025.
- "Using a Feedback Loop for LLM-based Infrastructure as Code Generation," arXiv:2411.19043, 2024.
Academic — Observability / Provenance
- B. Dong, J. Lu, J. Zhu, "AgentOps: Enabling Observability of LLM Agents," arXiv:2411.05285, 2024.
- "Verifiability-First Agents," arXiv:2512.17259, 2025.
- "MX-AI: Agentic Observability and Control Platform for Open and AI-RAN," arXiv:2508.09197, 2025.
Academic — Neuro-Symbolic / MCP / A2A
- B. C. Colelough et al., "Neuro-Symbolic AI in 2024: A Systematic Review," arXiv:2501.05435, 2025.
- "Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions," arXiv:2503.23278, 2025.
- "MCP at First Glance: Security and Maintainability," arXiv:2506.13538, 2025.
- "Improving Google A2A Protocol," arXiv:2505.12490, 2025.
Academic — Industrial Domain / Governance
- H. Zhao et al., "A Large Language Model-based multi-agent manufacturing system for intelligent shopfloor," arXiv:2405.16887, 2024.
- "Cleaning Maintenance Logs with LLM Agents for Improved Predictive Maintenance," arXiv:2511.05311, 2025.
- J. Jannelli et al., "Agentic LLMs in the Supply Chain," arXiv:2411.10184, 2024.
- "A Survey of LLM-based Agents in Medicine," arXiv:2502.11211, 2025.
- "Grid-Agent: An LLM-Powered Multi-Agent System for Power Grid Control," arXiv:2508.05702, 2025.
- "TRiSM for Agentic AI," arXiv:2506.04133, 2025.
- "How Do LLMs Fail In Agentic Scenarios?" arXiv:2512.07497, 2025.
- EU AI Act, Regulation (EU) 2024/1689.
- ISO/IEC 42001:2023.
Industry Sources
- TradingAgents GitHub Repository (Tauric Research), confirmed 2026-05-01 — 62,306 stars.
- DeerFlow 2.0 GitHub (ByteDance).
- Anthropic Managed Agents engineering documentation.
- LangGraph official site (LangChain).
- Google ADK / Gemini Enterprise Agent Platform announcement (Cloud Next '26).
- Bosch Manufacturing Co-Intelligence (CES 2026).
- Siemens Senseye + Industrial Copilot, 2025-12 announcement.
- Schneider Electric "One Digital Grid," 2025-12-12 release.
- Microsoft Hannover Messe 2026 industrial intelligence announcement.
- Samsung Electronics AI-Driven Factories 2030 strategy.
- Hyundai Motor Company AI Robotics, CES 2026.
- CJ Logistics NextGen AI announcement (MODEX 2026).
- KEPCO grid paradigm shift (2026-04).
- Abridge AMIA partnership.
- Hippocratic AI Nurse Co-Pilot 2026 announcement.
- A2A Protocol first anniversary — 150+ organizations press release.
- MCP Adoption Statistics 2026 (Digital Applied).
- ACM Fintech 2026 TradingAgents reproducibility study.
- McKinsey, "Building the foundations for agentic AI at scale."
- Forrester 2026 AI pilot failure analysis (evaluation 64% / governance 57% / reliability 51%).
- Gartner Data Quality estimate — $12.9M annual loss.
- BARC AI Innovation survey (40%+ distrust, 45%+ data quality as obstacle).
- Monte Carlo Data — five pillars of data observability.
- DataBahn AIDI 2026-03 launch.
- Dynatrace + Bindplane acquisition, 2026-04.
- Informatica Enterprise AI Agent Engineering whitepaper.
- Korea sovereign-AI consortium, Samsung SDS-led announcement.
📚 Physical AI Series
This article is part of the Physical AI series curated by Pebblous — how robots come to see, understand, and act, read together across data, simulation, models, and industry landscape.