Executive Summary
2024년 9월 Fei-Fei Li가 World Labs를 창업하며 시드 $230M을 모았고, 2025년 11월 Marble을 정식 출시해 누적 펀딩 $1B을 넘겼다. 같은 시기 STF Labs(Studio Tim Fu)의 UrbanGPT 2.0 Beta가 자연어로 도시 레이아웃을 생성하기 시작했고, HKUST의 Sat2City가 ICCV 2025에 위성 한 장으로 3D 도시를 만드는 모델을 발표했다. AI 도시설계 시장은 2025년 $2.26B에서 2035년 $13.60B (CAGR 19.65%)로, Geospatial AI는 $38B에서 2030년 $64.6B (CAGR 9.25%)로 향한다. 그런데 정작 이 출력물 — 3D 도시 모델·메타데이터·시나리오 — 의 품질을 어떻게 측정할 것인가에 대한 업계 합의는 없다. Spatial AI에 점수를 매길 표준이 비어 있다.
페블러스는 PebbloSim(시뮬레이션 기반 합성 도시·교통·환경 데이터 생성기) 관점에서 5가지 평가 기준을 제안한다. (1) Geo 정합성 — 좌표·축척이 실제 지리와 정합한가, (2) Scale 일관성 — 건물·도로·식재 비율이 현실적인가, (3) GFA 검증 — 용적률·건폐율이 법규 충돌 없는가, (4) 시나리오 다양성 — 단일 시드에서 변형 폭이 얼마나 되는가, (5) Sim-to-Real Gap 측정 — 실제 도시 데이터와의 거리(Chamfer·MMD·EMD·Fréchet Distance)는 얼마인가. 이 5가지는 학술 prior와 업계 공백의 교차점에 위치한다. 시나리오 다양성·Sim-to-Real Gap은 학계가 정량화 방법론을 정리해 두었고(UrbanWorld의 Homogeneity Index, HiFi DT의 4-metric 묶음), Scale 일관성은 CityDreamer의 Depth/Camera Error에 도시 특화 sub-metric을 더하면 된다. Geo 정합성·GFA 검증은 학계 공백 영역으로, 정의 자체가 새로운 기여가 된다.
본 보고서가 정리한 10개 주요 플레이어 — STF Labs, World Labs, Cesium AI, Esri GeoAI, Mapbox MapGPT, NVIDIA Omniverse, Bentley iTwin, Autodesk Forma, TestFit, Hypar — 중 자체 출력 품질 검증 메서드론을 공개한 곳은 사실상 Esri 한 곳뿐이다(ISO 23894 기반 "Trusted AI" 가이드). 나머지 9개는 자동화·생성에는 강하지만 "어떻게 검증되는가"를 공개하지 않는다. ISO/IEC 5259-4가 2025년 2월 EU 표준(EN ISO/IEC 5259-4:2025)으로 채택되면서 데이터 품질 표준 논의는 LLM에서 Spatial AI로 확장될 조짐을 보이고 있다. 평가 프레임워크를 먼저 가진 팀이 표준 논의 테이블에 앉는다. 페블러스는 본 보고서를 그 첫 발로 둔다.
$13.6B
2035 AI 도시설계 시장
CAGR 19.65% (Metatech)
$64.6B
2030 Geospatial AI
CAGR 9.25% (Arizton)
10
주요 플레이어 수
STF·World·Esri 등
1/10
평가 공개 비율
Esri만 공식 가이드
5
페블러스 제안 기준
Geo·Scale·GFA·다양성·Gap
Spatial AI의 부상 — UrbanGPT를 사례로
"Spatial AI"는 2024~2025년 사이 사실상 신규 카테고리로 자리잡았다. 2024년 9월 스탠퍼드의 Fei-Fei Li가 World Labs를 창업하며 시드 $230M을 모았고, 2025년 11월에는 Marble을 정식 출시해 누적 펀딩 $1B을 돌파했다. World Labs는 "공간 지능(Spatial Intelligence)이 언어 지능에 필적·보완하는 AI의 다음 frontier"라는 명제를 내걸었다. Imperial College의 Andrew Davison이 2018~2019년 FutureMapping 시리즈에서 학술적으로 정의한 Spatial AI 개념 — SLAM이 진화한 형태로 공간을 인지·모델·추론·행동으로 통합하는 시스템 — 이 이제 산업 용어로 흡수된 것이다.
1.1같은 시기 흐름 — 5개 사례
2025년 한 해 동안 자연어 → 3D 공간 구조 생성이라는 같은 패턴의 도구·논문이 동시 다발적으로 등장했다. 다만 같은 카테고리 안에서도 도구의 결은 다르다. World Labs Marble은 navigable 환경 자체에 집중하고, STF Labs UrbanGPT 2.0은 도시·건축 도메인에 특화돼 GFA·FAR(용적률)을 다루며, Sat2City는 위성 입력만으로 도시를 복원한다. Cesium·Esri는 GIS 인프라 위에 AI 레이어를 얹는 방식이다.
| 플랫폼 | 출시 | 핵심 기능 | 평가 메서드론 공개도 |
|---|---|---|---|
| STF Labs UrbanGPT 2.0 Beta | 2026 초 | 자연어 → 3D 도시 레이아웃, 자동 GFA 최적화 | ⚪ 없음 (정성 표현뿐) |
| World Labs Marble | 2025-11 | Text/Image → navigable 3D (Chisel UI) | ⚪ 공식 메트릭 비공개 |
| HKUST AI4City Sat2City | ICCV 2025 | 위성 1장 → 3D 도시 (cascaded latent diffusion) | ✅ 학술 메트릭 공개 (Chamfer 100%, EMD 60% COV) |
| Cesium ion + AI (Bentley) | 2025-07 | 3D geospatial + Gaussian Splatting + AI 디텍터 | △ 디텍터별 부분 공개 |
| Esri ArcGIS AI Assistant | 2025-10 | GIS + LLM Assistant (Arcade, Business Analyst) | ✅ Trusted AI 공식 가이드, ISO 23894 정합 |
1.2시장 수치 — 세 출처가 같은 방향을 가리킨다
세 시장조사 기관의 수치는 측정 범위는 다르지만 같은 방향을 가리킨다. AI 도시설계는 2025년 $2.26B에서 2035년 $13.60B로 CAGR 19.65% 성장 전망이다(Metatech Insights). Geospatial AI는 2024년 $38B에서 2030년 $64.6B (CAGR 9.25%)로 향하고(Arizton), 같은 시기 Geospatial Intelligence 전체는 2030년 $62.88B 규모로 전망된다(MarketsandMarkets). 자연어 → 3D 공간 생성이라는 좁은 카테고리에서 시작된 흐름이 GIS·디지털트윈·도시계획 전체로 확장되고 있음을 의미한다.
1.3⚠️ UrbanGPT 동명이인 disclaimer
본 보고서가 다루는 UrbanGPT는 STF Labs UrbanGPT 2.0 Beta(자연어 → 3D 도시 레이아웃)이다. 같은 이름의 다른 프로젝트인 HKUDS UrbanGPT(KDD'2024, HKUST·SCUT·Baidu 공동, Spatio-temporal LLM)와 혼동하지 말 것. HKUDS UrbanGPT는 3D 공간 생성이 아닌 교통·인구·환경의 시공간 예측 모델이다(arXiv:2403.00813). 같은 이름이지만 서로 다른 목적·다른 출력·다른 평가 메트릭을 가진 별개 프로젝트다.
1.4STF Labs UrbanGPT 2.0 — 공개 정보 정리
STF Labs(Studio Tim Fu)는 런던 기반의 RIBA·ARB 등록 건축사 스튜디오로, Tim Fu가 founder다. UrbanGPT 2.0 Beta는 GPT-4o(언어 계층) + 실시간 diffusion(공간 생성) + Rhino/Grasshopper(정밀 기하)를 결합한 자연어 도시 생성 도구다. "70% 주거, 30% 상업, FAR 450%" 같은 자연어 prompt를 받으면 3D 도시 레이아웃과 자동 GFA 최적화 결과를 출력한다. 공개된 파트너는 NVIDIA와 Lenovo이며, STF Labs의 로드맵은 "현실 도시 데이터 통합 → form-generation에서 spatial decision-making으로"로 정의돼 있다.
다만 평가 메서드론은 비공개다. Beta 출시문은 "production workflow integration, 안정성·정밀성 도달"이라는 정성 표현뿐이며, 정량 벤치마크·평가 데이터셋·baseline 비교는 공개되지 않았다. "자동 GFA 계산"이라는 표현은 있으나 어떤 법규 DB·어떤 알고리즘인지 명시되지 않았다. 이러한 정보 비대칭이 본 보고서의 출발점이다.
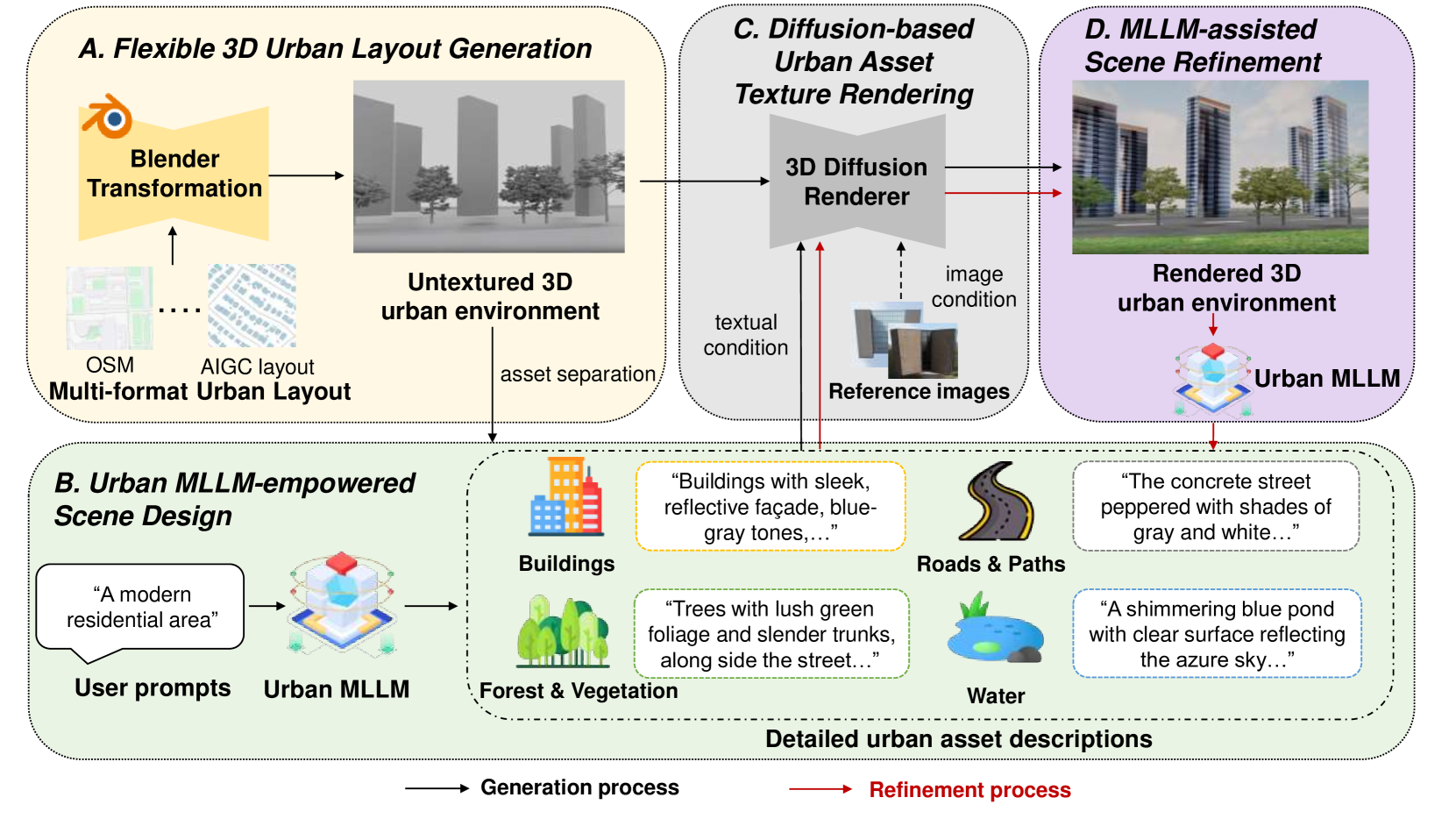
왜 평가가 어려운가
Spatial AI 출력은 세 가지 차원으로 구성된다. (1) 3D 모델(건물·도로·식재의 기하), (2) 메타데이터(좌표계, GFA, FAR, 용도지역), (3) 시나리오(인구·교통·환경 시뮬레이션 입력). 이 세 차원이 서로 정합해야 비로소 "사용 가능한 도시 설계안"이 된다. 그런데 기존 LLM 벤치마크(MMLU·HELM·MMBench)는 텍스트 출력의 정확도·일관성만 측정한다. 3D 기하·좌표·법규 충돌·시뮬레이션 입력의 타당성은 측정 영역 밖이다.
2.1학계의 진단 — "사람 평가에 의존"
Tsinghua + SJTU 연구진이 2024년 발표한 T3Bench(arXiv:2310.02977)는 Text-to-3D 평가가 "largely relied on subjective user experiments"임을 공식 진단했다. T3Bench의 Quality 메트릭은 사람 평가와 Spearman 상관 0.784(ImageReward 기반), Alignment 메트릭은 0.780(GPT-4 기반)에 달했지만, 여전히 단일 자동 메트릭으로 끝나지 않는다. 동시기 발표된 3D Scene Generation Survey(arXiv:2505.05474, S-Lab NTU)도 "no single metric performs consistently across all datasets"라는 합의를 정리했다. CityDreamer(CVPR 2024) 같은 SOTA 모델의 user study조차 N=20, 1~5 척도 수준이다. 산업도 학계도 같은 공백 위에 서 있다.
T3Bench 저자들은 "지금까지의 Text-to-3D 평가는 대체로 주관적 사용자 실험에 의존해 왔다"고 진단했다. 자동 메트릭이 사람 평가와 상관 0.78에 도달하긴 했으나, 그것만으로 "이 도시가 법규에 맞는가, 실측과 얼마나 떨어져 있는가"를 답하지는 못한다.
2.2"시각적 그럴듯함 ≠ 사용 가능성"
UrbanWorld(arXiv:2407.11965) 저자들은 자기 모델의 핵심 약점으로 "homogeneous styles, limited diversity"를 직접 지목했다. 보기에 그럴듯한 도시도 시드를 바꿔도 비슷한 도시만 나온다면, 도시계획 의사결정에 쓸 수 없다. FID 97.38(CityDreamer) vs 213.56(SceneDreamer)로 1년 만에 절반으로 줄어든 분포 거리 메트릭조차, 그것만으로는 사용 가능성을 보장하지 못한다. 시각적 자연스러움과 실무 적용 가능성 사이에 큰 간격이 남아 있다.
2.3표준의 시차
ISO/IEC 23894:2023(AI 리스크 관리)와 ISO/IEC 5259 시리즈(데이터 품질, 5259-4가 2024-07 발행 → 2025-02 EU 표준 EN ISO/IEC 5259-4:2025 채택)는 LLM에 적용되기 시작했다. 그러나 3D 공간 출력에는 미적용이다. Esri의 Trusted AI 가이드도 GIS 분석 워크플로우 위주이며, 자연어→3D 생성에는 빈 칸이다. ISO 23247(디지털트윈)은 제조 중심이라 도시에 적용하려면 보완 표준(ITU T-REC-Y.3090 등)이 필요하다. OGC CityGML 3.0은 conceptual model 단계(2021)에서 2025년 3DCityDB v5로 구현이 가속됐으나, "Spatial AI 출력 검증" 용도로는 아직 정형화되지 않았다. 표준과 기술 사이에 약 2~3년의 시차가 있다.
페블러스가 제안하는 5가지 평가 기준
본 5가지 기준은 페블러스가 PebbloSim 관점에서 제안하는 평가 프레임워크다. 페블러스가 현재 운영 중인 표준이 아니라, Spatial AI 평가 공백을 메우기 위한 가설적 제안임을 명확히 둔다. 5가지는 학계가 부분적으로 정리한 메트릭과 업계가 비워둔 검증 차원의 교차점에서 도출됐다. 각 기준은 정의·측정 방법·학술 prior·페블러스가 제안하는 차별점을 함께 제시한다.
3.1Geo 정합성 (Geographic Coherence)
생성된 도시 모델의 좌표·축척·도로 토폴로지가 실제 지리(GIS·위성 영상)와 정합하는가를 묻는 기준이다. 자연어 prompt에서 "강남구 70만㎡"를 받았을 때, 출력 도시가 실제 강남구 GIS 폴리곤과 좌표·면적·도로 토폴로지에서 합리적으로 일치하는지를 측정한다.
측정 방법 (제안)
- 생성 모델 좌표 IoU vs 실제 GIS 폴리곤
- 도로 네트워크 토폴로지 매칭 (그래프 동형성)
- 위성 영상 alignment (Sentinel-1/2 cross-reference)
학술 prior
거의 없음 — 신규 영역. 인접 영역으로 GeoAI/Remote Sensing의 RemoteBAGEL(FID에 GPT-4o로 "geographically plausible" 평가 추가), RSWISE(FID보다 geospatial alignment를 잘 반영)가 존재하나, Spatial AI 출력의 GIS 정합 검증으로는 정형화되지 않음.
페블러스 제안 차별점
GIS 데이터 + 위성 영상 cross-reference를 표준 체크리스트화. 정의되면 학술적으로도 새로운 기여가 된다.
3.2Scale 일관성 (Scale Consistency)
건물 높이·도로 폭·식재 비율·블록 크기 등의 상대적 비율이 도시 현실과 정합하는가를 측정한다. 한국의 일반 주거지역에서 갑자기 30층 단독주택이 나온다면 시각적으로 그럴듯해도 부적합하다. 도시별 비율 분포와의 통계적 거리를 정량화한다.
측정 방법 (제안)
- Depth Error (DE) — 추정 깊이 vs pseudo-GT
- Camera Error (CE) — inference vs COLMAP 카메라 궤적
- 도시 특화 sub-metric — 건물 높이 분포 / 도로 폭 비율 / 식재 점유율
학술 prior
풍부. CityDreamer(CVPR 2024)와 UrbanWorld(2024)의 표준 메트릭. CityDreamer는 DE 0.147 / CE 0.060, UrbanWorld는 CityDreamer 대비 DE 44.2% 개선. GPTEval3D(arXiv:2401.04092)의 "Geometry Plausibility" 항목과 3DGen-Bench(arXiv:2503.21745)의 "Geometry Plausibility/Details" 2개 차원이 직접 대응한다.
페블러스 제안 차별점
도시 도메인 sub-metric으로 확장. "건물 높이 분포가 실제 ○○ 구와 KS test 유의" 같은 정량 기준 제시.
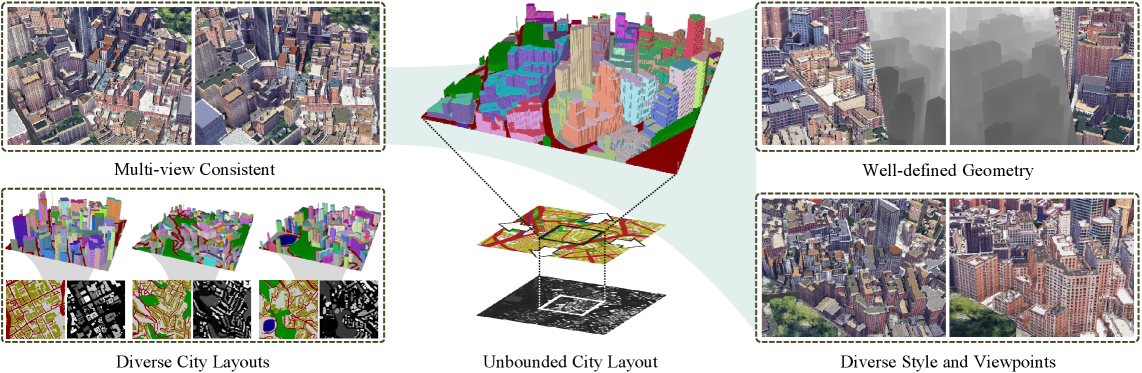
3.3GFA 검증 (Gross Floor Area Validation)
생성된 도시의 용적률(FAR)·건폐율·용도지역 분포가 법규와 충돌 없는가를 자동 검증한다. UrbanGPT 2.0이 "FAR 450%"를 prompt로 받았을 때, 실제 출력의 건물 footprint × 층수 합이 정말 FAR 450%인지, 그리고 해당 부지의 zoning code에서 FAR 450%가 허용되는지를 함께 묻는다. B2B·규제 환경에서 가장 즉시적인 가치를 갖는 기준이다.
측정 방법 (제안)
- Building footprint extraction (IoU·F1·Jaccard — Nature Sci Rep 2024)
- Building height estimation (MSE — Sentinel-1/2 기반, ScienceDirect 2023)
- 법규 룰 엔진과의 충돌 체크 (페블러스 신규 제안)
학술/업계 prior
footprint 추출·높이 회귀는 GeoAI에서 활발하나, 생성 결과의 법규 자동 검증은 학술 prior 없음. 업계에서는 Autodesk Forma(구 Spacemaker), TestFit, Hypar가 자동 생성에는 강하나 ML 평가 메트릭을 공개하지 않는다. STF Labs UrbanGPT 2.0도 "자동 GFA 계산" 표현뿐, 어떤 법규 DB·어떤 알고리즘인지 비공개다.
페블러스 제안 차별점
법규 DB 연동 자동 검증 체크리스트. B2B/규제 적용에서 즉시 차별화 포인트. 평가 메서드론 공개를 통한 신뢰성 확보.
3.4시나리오 다양성 (Scenario Coverage)
단일 prompt/seed에서 생성 가능한 도시 변형의 폭과 커버리지, mode collapse 여부를 측정한다. 같은 prompt에서 시드만 바꿨을 때 도시들이 얼마나 서로 다른가 — 다양성이 낮으면 의사결정 도구로서의 가치가 떨어진다. UrbanWorld 저자들이 자기 약점으로 "homogeneous styles, limited diversity"를 직접 지목한 바로 그 차원이다.
측정 방법 (제안)
- Homogeneity Index (HI) — ResNet feature 코사인 유사도 평균 (낮을수록 다양)
- Precision / Recall / Density / Coverage 4종 (Kynkäänniemi 2019, Naeem 2020)
- Graph Embedding 기반 커버리지 (Argoverse 2.0 / CARLA)
- Coreset Selection — 광범위 커버리지를 보장하는 compact set 구성
학술 prior
가장 풍부. UrbanWorld가 HI를 도입해 CityDreamer 대비 10.4% 개선(0.665 vs 0.830). UrbanWorld 저자들이 직접 "homogeneous styles, limited diversity"를 핵심 약점으로 진단 — 페블러스 진단과 정확히 일치한다.
페블러스 제안 차별점
HI를 표준 패키지로 즉시 채택 권장. PebbloSim에서 시드별 시나리오 fan-out을 측정해 다양성 리포트 자동 생성.
3.5Sim-to-Real Gap 측정
생성된 도시 데이터와 실제 도시 데이터(LiDAR·항공 영상·GIS) 사이의 분포·기하 거리를 측정한다. 시뮬레이션 데이터로 학습한 모델이 실세계에서 작동할 수 있는가 — 자율주행·로봇·디지털트윈의 핵심 질문이다. UCF의 HiFi DT framework가 사실상 표준 패키지를 정리해 두었다.
측정 방법 (제안) — HiFi DT 4-metric 채택
- Chamfer Distance (raw 점군 거리)
- MMD — latent feature 분포 거리 (kernel)
- EMD — Earth Mover's Distance
- Fréchet Distance (latent) — feature mean+cov 비교
학술 prior
방법론 완성도 가장 높음. HiFi DT(arXiv:2509.02904)는 Synthetic(UT-LUMPI) vs Real(LUMPI) 평가에서 CD 0.32 / MMD 1.05e-5 / EMD 0.988 / FD 0.210을 보고. 더 인상적인 사실은, 합성 학습 모델이 44.74% AP로 실데이터 학습(42.70%)보다 +4.8% 우수했다는 점 — 잘 만든 시뮬레이션은 실데이터보다도 우수할 수 있다. Sat2City(ICCV 2025) 역시 Chamfer 100% COV / EMD 60% COV로 도시 도메인에서 동일 메트릭 가족을 사용한다.
페블러스 제안 차별점
HiFi DT 4-metric을 표준 패키지로 채택해 학술 호환성 확보. 도시 특화 raw 데이터(GIS·위성·LiDAR)를 추가해 도메인 확장.
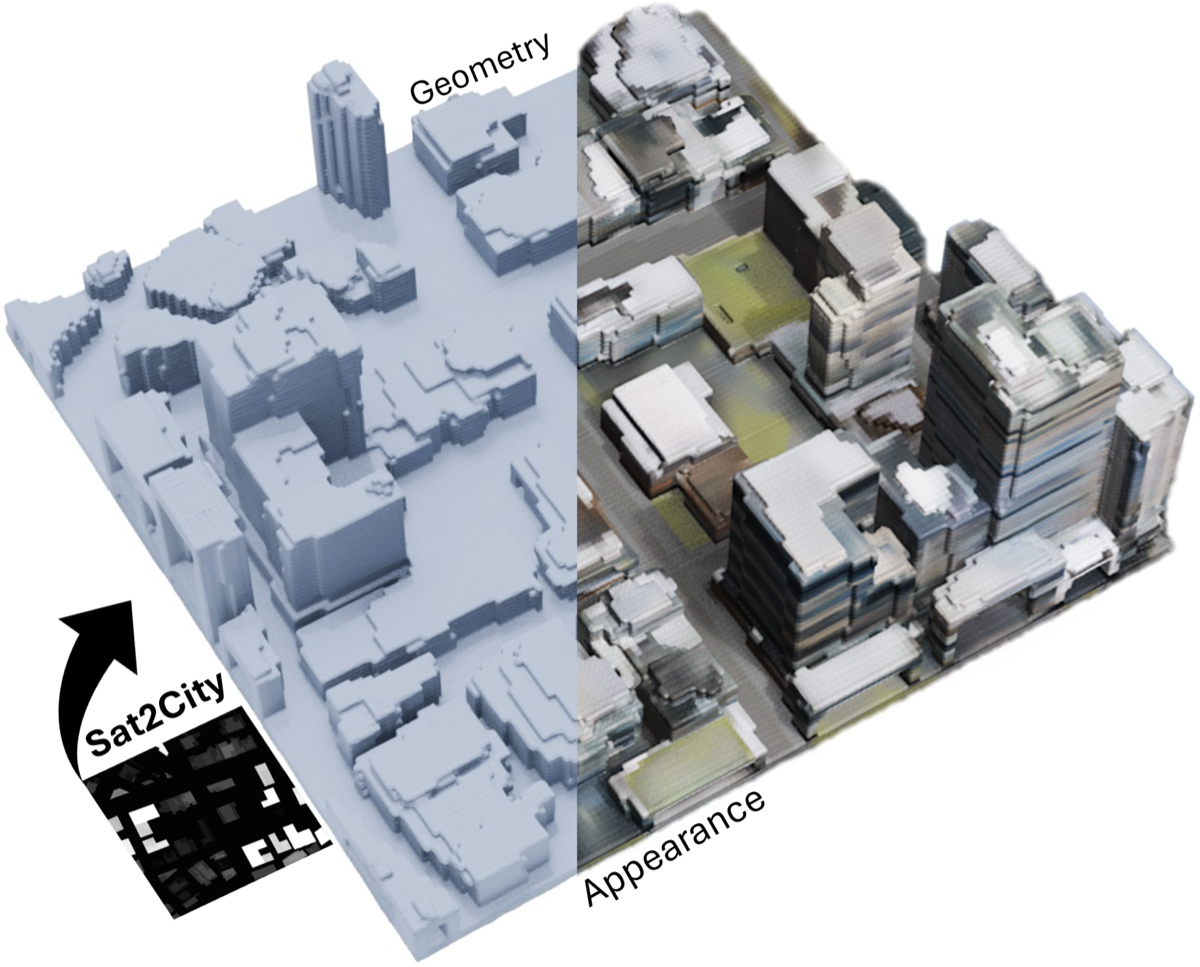
3.65기준 종합 표
5가지 기준을 학술 prior, 업계 prior, 페블러스 신규 기여 관점에서 정리하면 다음과 같다. ✅ 표시는 풍부한 prior가 존재해 즉시 채택 가능한 영역, ⚪ 표시는 학술·업계 모두 비어 있어 정의 자체가 신규 기여가 되는 영역이다.
| 기준 | 학술 prior | 업계 prior | 페블러스 신규 기여 |
|---|---|---|---|
| 3.1 Geo 정합성 | ⚪ 거의 없음 | ⚪ 없음 | ⭐ 표준 정의 자체가 새로운 기여 |
| 3.2 Scale 일관성 | ✅ CityDreamer DE/CE, GPTEval3D, 3DGen-Bench | △ 부분 | 도시 특화 sub-metric |
| 3.3 GFA 검증 | ⚪ footprint/height만, 법규 검증 없음 | △ Forma/TestFit, 평가 비공개 | ⭐ 법규 DB 연동 자동 검증 |
| 3.4 시나리오 다양성 | ✅ HI, P/R/D/C, Graph Embedding, Coreset | ⚪ 없음 | HI 즉시 채택 + PebbloSim fan-out |
| 3.5 Sim-to-Real Gap | ✅ HiFi DT 4-metric, Sat2City | ⚪ 없음 | HiFi DT 패키지 채택 + 도시 raw 확장 |
UrbanGPT 2.0에 5기준 적용 — 평가 결과
⚠️ Disclaimer: 본 섹션의 모든 점수·관찰은 공개된 STF Labs 자료(LinkedIn 발표, Parametric Architecture 매거진, 시연 영상)와 페블러스 기존 분석에 근거한 외부 관찰 기반 추정이다. STF Labs 공식 내부 평가가 아니며, 평가 메서드론이 비공개이므로 정량 점수는 가설적이다. 본 표의 목적은 5기준의 적용 사례 시연이지 UrbanGPT 2.0의 우열 판정이 아니다.
4.15기준 적용 표 (외부 관찰 기반 추정)
각 기준별로 공개된 정보만 가지고 평가를 시도했다. 평가 메서드론이 비공개인 항목은 ⚪ 미측정으로 두었다.
| 기준 | 가설적 평가 | 관찰 근거 (외부) |
|---|---|---|
| 3.1 Geo 정합성 | ◯ 보통~양호 (추정) | Rhino/Grasshopper 기반 정밀 기하. 실제 GIS와의 cross-reference 메트릭은 비공개 |
| 3.2 Scale 일관성 | ◯ 양호 (추정) | GPT-4o + diffusion 결합으로 시각적 비율 일관성 안정. DE/CE 정량 메트릭 미공개 |
| 3.3 GFA 검증 | △ 약점 (가설) | "자동 GFA 계산" 표현은 있으나 법규 DB 연동 미공개. zoning 정합 검증 정보 부재 |
| 3.4 시나리오 다양성 | △ 측정 불가 (가설) | seed별 fan-out 정보 비공개. UrbanWorld가 진단한 "homogeneous styles" 동일 위험 추정 |
| 3.5 Sim-to-Real Gap | ⚪ 미측정 (추정) | "real-world data 통합"은 STF Labs 로드맵 다음 단계. Chamfer/EMD 도구 미공개 |
4.2추정 강점 (2가지)
평가 메서드론은 비공개이지만, 공개된 기술 스택과 시연 영상에서 두 가지 강점이 일관되게 관찰된다.
1. 기하 정밀도
Rhino/Grasshopper 백엔드 결합으로 건축·도시 도메인의 정밀 기하를 다룬다. 단순 diffusion 생성과 달리 architect-grade 출력에 도달.
2. 자연어 인터페이스 성숙도
GPT-4o 통합으로 "70% 주거, 30% 상업, FAR 450%" 같은 복합 prompt 처리. 도시계획 실무자 친화 UX.
4.3추정 약점 (3가지)
반면 평가 메서드론 비공개로 인한 약점이 세 가지 차원에서 관찰된다. 모두 본 보고서가 제안하는 5기준이 정확히 채울 수 있는 공백이다.
1. 법규 검증 불투명
"자동 GFA 계산"의 내부 알고리즘·법규 DB 미공개. 한국·일본·EU 등 도시별 zoning code 정합성 검증 불가.
2. 다양성 측정 도구 부재
같은 prompt에서 얼마나 다양한 도시가 생성되는지 정량 보고 없음. HI 같은 표준 메트릭 미적용.
3. Sim-to-Real Gap 측정 부재
생성 도시와 실제 도시 데이터의 거리 측정 도구·결과 미공개. "현실 도시 데이터 통합"이 로드맵이지 현재 기능이 아님.
결론: STF Labs UrbanGPT 2.0은 자연어→3D 생성 카테고리에서 도시·건축 도메인에 가장 특화된 도구다. 다음 단계 — 평가 메서드론 공개·법규 정합 검증·Sim-to-Real Gap 측정 — 가 산업 적용의 관건이다. 본 보고서가 제안하는 5기준은 그 다음 단계를 위한 한 가지 청사진이다.
PebbloSim과의 결합 가능성
⚠️ 톤 주의: 본 섹션은 페블러스 일방의 가능성 제안이며, STF Labs와의 공식 협력 발표가 아니다. STF Labs 공개 파트너는 NVIDIA·Lenovo이며, 페블러스와의 공식 협력 정보는 미공개. 표현은 "탐색 중", "가능성", "청사진"으로 일관한다.
UrbanGPT 2.0이 자연어로 도시 레이아웃을 생성한다면, PebbloSim은 그 레이아웃 위에서 인구·교통·환경 시나리오를 시뮬레이션해 "실행 가능한 도시 설계안"으로 진화시킬 수 있다. 즉 UrbanGPT 출력 → PebbloSim 시뮬레이션 → 5기준 평가 → 피드백 파이프라인은 자연스러운 결합점이다. 본 섹션은 이 파이프라인의 구체적 형태를 청사진 수준으로 제시한다.
5.1워크플로우 표 — 5단계 파이프라인
입력에서 피드백 환류까지의 흐름을 단계별로 정리하면, 각 단계는 페블러스 제품군 중 하나 이상과 직접 매핑된다.
| 단계 | 처리 | 담당 |
|---|---|---|
| 1. 입력 | "서울 강남구 70만㎡, 주거 70% 상업 30%, FAR 450%, BRT 통과" | 자연어 prompt |
| 2. 생성 | 3D 도시 레이아웃 + 좌표·GFA·용도지역 메타데이터 | UrbanGPT 2.0 |
| 3. 시뮬레이션 | 인구 흐름 / 교통 / 일조·열·소음 + 시드별 fan-out | PebbloSim |
| 4. 평가 | 5기준 자동 평가 → 품질점수 + 약점 sub-metric별 가이드 | DataClinic + PebbloScope + Data Greenhouse |
| 5. 피드백 | 리포트 → UrbanGPT 재생성 입력으로 환류 | 평가 레이어 → 생성 레이어 |
5.2페블러스 제품군 ↔ 5기준 매핑
DataClinic(학습 데이터 진단), PebbloScope(분포 시각), PebbloSim(합성 데이터 생성), Data Greenhouse(실측 큐레이션) 네 가지 제품군이 5기준의 측정 인프라를 직접 구성한다.
| 기준 | DataClinic | PebbloScope | PebbloSim | Data Greenhouse |
|---|---|---|---|---|
| 3.1 Geo 정합성 | ✅ 좌표 검증 | ✅ GIS 시각화 | — | — |
| 3.2 Scale 일관성 | — | ✅ 비율 분포 | △ | — |
| 3.3 GFA 검증 | ✅ 법규 룰 엔진 | ✅ zoning 시각 | — | — |
| 3.4 시나리오 다양성 | — | △ | ✅ fan-out + HI | — |
| 3.5 Sim-to-Real Gap | — | — | ✅ 합성 생성 | ✅ 실측 큐레이션 |
5.3NVIDIA Omniverse Smart City Blueprint와의 포지셔닝
NVIDIA의 Smart City AI Blueprint(팔레르모 시 사례, 초당 50B 픽셀 처리)는 인프라 레이어다 — Cosmos·NeMo·Metropolis가 1,000+ 비디오 스트림을 실시간 분석한다. Bentley iTwin은 인프라 자산의 디지털트윈 플랫폼이며, Cesium은 3D geospatial 인프라다. 이들은 모두 강력한 인프라이지만 자연어→3D 생성물의 품질 평가 메서드론은 비워두고 있다. 페블러스의 자리는 이 인프라들 위에서 작동하는 평가 메타 레이어다. NVIDIA Omniverse가 시뮬레이션을 돌리면 페블러스는 그 결과의 품질을 5기준으로 평가하고 피드백한다. 같은 카테고리에 들어가 경쟁하지 않고, 인프라 위에서 보완 관계로 동작 가능하다.
본 청사진은 STF Labs와 가능성을 탐색 중인 영역의 한 형태다. AI 도시설계·디지털트윈·시뮬레이션 분야에서 평가 메서드론을 고민하는 팀이 있다면, 본 5기준이 출발점이 될 수 있다.
Spatial AI 평가의 미래 — 표준 동향
ISO/IEC와 IEC, OGC, NIST가 2023~2025년 사이 AI 신뢰성·데이터 품질·디지털트윈 보안 표준을 연이어 정비하고 있다. 그러나 Spatial AI(자연어→3D 생성)에 직접 적용 가능한 도시 분야 정식 표준은 부재하다. 이 공백은 페블러스가 표준 논의 테이블에 진입할 수 있는 시간 창이다.
6.1핵심 표준 4가지
현재 Spatial AI 평가에 직간접으로 연결되는 핵심 표준은 네 가지다. 시점·범위·Spatial AI 적용도를 함께 정리한다.
| 표준 | 시점 | 범위 | Spatial AI 적용도 |
|---|---|---|---|
| ISO/IEC 23894 | 2023 발행 | AI 리스크 관리 프레임워크 | Esri만 Trusted AI에서 정합. 3D 출력 평가에는 미적용 |
| ISO/IEC 5259-4 | 2024-07 발행 → 2025-02 EU 표준 채택 | AI 데이터 품질 프로세스 프레임워크 | ⭐ LLM에 적용 시작. Spatial AI로 확장 시 직접 기준 |
| OGC CityGML 3.0 | 2021 conceptual model → 2025 3DCityDB v5 | 3D 도시 모델 표준 (BIM 통합, 실내 LOD) | 잠재 베이스. "출력이 CityGML LOD 기준에 정합한가" 검증 가능 |
| NIST IR 8356 | 2025 발행 | 디지털트윈 보안 프레임워크 | 인접 표준. 평가 = 신뢰 = 보안의 연쇄에서 마지막 고리 |
6.2도시 분야 정식 표준의 공백
ISO 23247 시리즈는 manufacturing 중심이라 도시·smart city에는 보완 표준(ITU T-REC-Y.3090)이 필요하다. Digital Twin Consortium / OGC UDTIP(2025-02 종료된 Urban Digital Twin Implementation Pilot)도 합의 형성 단계다. 즉 도시 분야 정식 표준은 부재하고, 이는 평가 프레임워크를 먼저 가진 팀이 표준 논의에 의제를 제공할 수 있는 시간 창임을 의미한다.
ISO 5259-4 EN 채택(2025-02)은 신호다. 데이터 품질 표준이 EU에서 정식 표준화되는 흐름이 시작됐다. 이 흐름이 Spatial AI로 확장될 때, 평가 프레임워크를 제시한 팀의 의제가 표준 초안에 반영된다. 페블러스가 본 5기준을 공개적으로 제안하는 이유다.
결론 — 평가가 곧 시장 진입 장벽
본 보고서가 정리한 10개 주요 플레이어 — STF Labs, World Labs, Cesium, Esri, Mapbox, NVIDIA, Bentley, Autodesk Forma, TestFit, Hypar — 중 자체 출력 품질 검증 메서드론을 공개한 곳은 사실상 Esri 한 곳뿐이다. 나머지 9개는 자동 생성에는 강하지만 "어떻게 검증되는가"를 공개하지 않는다. 이 공백이 의미하는 바는 단순하다 — 평가 프레임워크를 가진 팀이 시장 진입 장벽을 세운다.
7.1평가 프레임워크 = 재인용 가능 IP
본 5기준은 단순한 측정 도구가 아니다. (a) 학계가 후속 연구에서 인용 가능한 정의, (b) 잠재 파트너가 자사 도구에 적용 가능한 체크리스트, (c) 정책 담당자가 조달 기준화 가능한 항목, (d) 페블러스 잠재 고객이 자사 데이터 품질을 자가 진단 가능한 도구 — 네 가지 층위로 재사용 가능한 IP 자산이다. 평가 프레임워크는 한 번 정의되면 인용·재사용·확장의 네트워크 효과를 일으킨다.
7.2페블러스의 자리 — "Spatial AI Data Quality" thought leader
페블러스는 AI-Ready Data 인프라 제공자다. Spatial AI 시대에 "AI-Ready"가 무엇인지 — 어떤 데이터·평가 기준·표준이 필요한지 — 정의하는 자리에 먼저 깃발을 꽂는다. DataClinic은 학습 데이터 품질 진단, PebbloScope는 분포·시각 진단, PebbloSim은 합성 데이터 생성, Data Greenhouse는 실측 데이터 큐레이션. 이 네 가지 제품군이 본 5기준의 측정 인프라를 직접 구성한다. 평가 프레임워크는 페블러스 제품군의 통합 외피이자, 외부와의 인터페이스다.
7.3다음 발걸음
ISO 5259-4 EN 채택(2025-02)과 OGC CityGML 3.0 implementation 가속(2025년 3DCityDB v5)은 모두 표준이 움직이고 있다는 신호다. 본 5기준은 그 표준 논의에 페블러스가 가져갈 의제다. 본 보고서가 첫 발이며, 시그니처 시리즈 2호(Palantir)에서는 같은 "평가 관점"을 데이터 운영 플랫폼으로 확장한다.
평가가 곧 시장 진입 장벽이다. 생성을 잘하는 팀은 많다. 평가를 잘하는 팀은 거의 없다. 페블러스는 후자의 자리를 노린다.
참고문헌
본 보고서가 인용한 학술 논문, 업계 발표, 표준·시장 자료를 트랙별로 정리한다.
학술 (Track A)
- Wen, B., Xie, H., Chen, Z., Hong, F., Liu, Z. (2025). "3D Scene Generation: A Survey." arXiv:2505.05474. 링크
- He, Y., Bai, Y., Lin, M., Zhao, W. (2024). "T3Bench: Benchmarking Current Progress in Text-to-3D Generation." arXiv:2310.02977. 링크
- 3DGen-Bench Team (2025). "3DGen-Bench: Comprehensive Benchmark Suite for 3D Generative Models." arXiv:2503.21745. 링크
- Xie, H., Chen, Z., Hong, F., Liu, Z. (2024). "CityDreamer: Compositional Generative Model of Unbounded 3D Cities." CVPR 2024 / arXiv:2309.00610. 링크
- Shang, Y., Lin, Y., Zheng, Y. (2024). "UrbanWorld: An Urban World Model for 3D City Generation." arXiv:2407.11965. 링크
- Shahbaz, M., Agarwal, S. (2025). "High-Fidelity Digital Twins for Bridging the Sim2Real Gap in LiDAR-Based ITS Perception." arXiv:2509.02904. 링크
- Hua, T. et al. (2025). "Sat2City: 3D City Generation from A Single Satellite Image." ICCV 2025 / arXiv:2507.04403. 링크
업계 (Track B)
- STF Labs (Studio Tim Fu). "Introducing UrbanGPT 2.0 Beta." LinkedIn 발표. 링크
- World Labs. "Marble: Multimodal World Model." World Labs Blog. 링크
- Esri. "Trusted AI — Implementation Best Practices" (ISO 23894 정합). 링크
- NVIDIA. "Smart City AI Blueprint" (Palermo 사례). NVIDIA Blog. 링크
- Fei-Fei Li. "From Words to Worlds: Spatial Intelligence." World Labs Substack. 링크