Executive Summary
미스트랄이 2026년 6월 23일 문서 인텔리전스용 OCR 4를 내놓았다. 새 모델이 출력하는 것은 텍스트만이 아니다. 단어 하나하나에 신뢰도 점수가 붙고, 글자가 페이지 어디에 있었는지 좌표가 따라오며, 그 블록이 제목인지 표인지 수식인지까지 분류돼 나온다. 그중에서도 데이터 파이프라인을 가장 깊이 흔드는 것은 단어 단위 신뢰도 점수다.
기존 OCR은 문서나 페이지 단위로만 "이 정도면 믿을 만하다"를 알려줬다. OCR 4는 단어마다 점수를 매긴다. 그래서 추출 결과가 곧 품질 평가표가 된다. 다운스트림 파이프라인은 점수 임계값 하나로 고신뢰 텍스트는 자동 승인하고 저신뢰 텍스트만 사람에게 넘길 수 있다. 별도 품질 검증 단계가 사라지는 셈이다. 다만 자체 호스팅 가격은 공개되지 않았고, OCR 3 대비 API 단가는 두 배로 올랐다.
여기에 위치 좌표와 블록 분류가 더해지면 RAG 답변의 출처를 원본 문서의 표 한 칸까지 역추적할 수 있고, 단일 컨테이너 자체 호스팅은 민감 문서를 인프라 밖으로 내보내지 않는다. 추출·품질·출처·주권. 그동안 따로 풀던 네 과제가 한 제품 안에서 맞물리기 시작했다.
단어 단위
신뢰도 점수
페이지가 아닌 단어마다 confidence 출력
170개
지원 언어
10개 언어군, 저자원 언어 포함
85.20
OlmOCRBench 1위
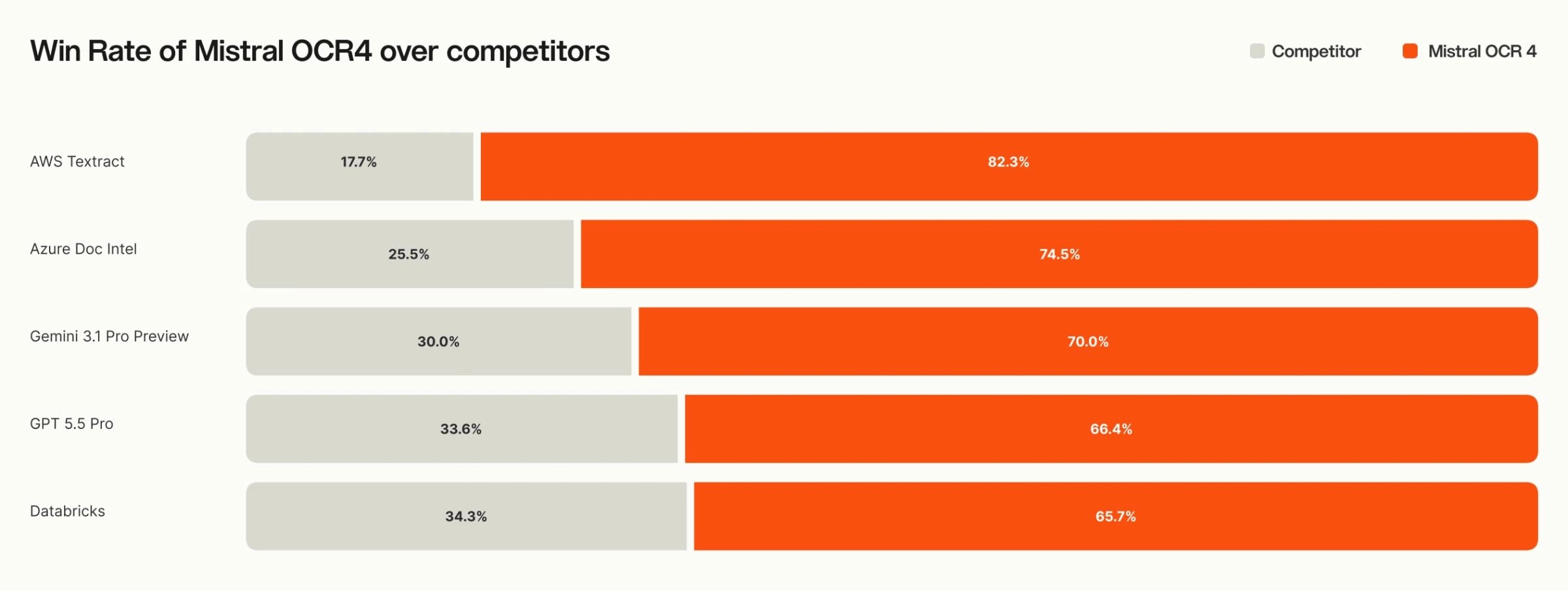
600+ 문서 평가에서 72% 승률
컨테이너 1개
자체 호스팅
클라우드 전송 없이 온프레미스 배포
비정형 데이터가 첫 관문이다
기업이 가진 데이터의 약 80%는 비정형이다. PDF 계약서, 스캔한 인보이스, 표가 빽빽한 보고서, 손글씨가 섞인 양식. 이 문서들을 LLM에 연결하려면 반드시 거쳐야 하는 단계가 있다. 사람이 읽던 종이를 기계가 다룰 수 있는 구조로 바꾸는 일, 곧 문서 추출이다. AI-Ready Data로 가는 길의 첫 관문이 여기에 있다.
문제는 이 첫 관문이 오랫동안 가장 허술했다는 점이다. 전통적인 OCR은 텍스트를 뱉어 놓을 뿐, 그 텍스트를 얼마나 믿어도 되는지는 알려주지 않았다. 흐릿하게 스캔된 숫자 "3"을 "8"로 잘못 읽어도, 출력만 보면 멀쩡한 "8"이다. 다운스트림에서는 어느 글자가 위험한지 알 길이 없다. 결국 사람이 전체를 다시 검수하거나, 검수를 포기하고 오류를 안고 가야 했다.
RAG에서 흔히 말하는 "garbage in, garbage out"은 검색 단계가 아니라 바로 이 추출 단계에서 시작된다. 원본 문서를 잘못 읽으면, 그 위에 아무리 좋은 임베딩과 검색을 얹어도 답변 품질은 추출 오류를 넘지 못한다. 첫 관문의 품질이 파이프라인 전체의 상한선이다.
텍스트에서 구조로
OCR 4가 기존 도구와 갈라지는 지점은 정확도 숫자가 아니다. 출력의 형태다. 같은 문서를 넣어도 돌려주는 것이 다르다. 전통적 OCR이 글자의 나열을 주는 반면, OCR 4는 글자에 더해 세 가지를 함께 붙인다. 텍스트 요소의 위치 좌표(bounding box), 블록 유형 분류(제목·표·수식·서명·단락), 그리고 페이지와 단어 단위의 신뢰도 점수다. 출력 형식도 Markdown·JSON에 더해 사용자가 정의한 스키마로 필드를 뽑아내는 방식까지 지원한다.
성능 자체도 뒤처지지 않는다. OlmOCRBench에서 85.20으로 전체 1위, OmniDocBench 93.07을 기록했고, 600개가 넘는 문서와 12개 이상 언어를 대상으로 한 독립 평가자 선호도 비교에서 72% 승률을 보였다. 지원 언어는 170개, 10개 언어군에 이른다. 저자원 언어에서도 경쟁 도구만큼 성능이 무너지지 않는다는 점이 다국어 문서를 다루는 조직에는 특히 중요하다.
핵심은 "읽기"에서 "구조로 이해하기"로의 이동이다. 글자만 뽑아내던 작업이, 문서가 어떻게 생겼고 각 조각이 무엇이며 얼마나 믿을 만한지를 함께 출력하는 작업으로 바뀌었다. 이 차이가 다음 두 섹션에서 데이터 품질과 RAG로 이어진다.
신뢰도 점수가 바꾸는 것
단어 단위 신뢰도 점수의 의미는 작아 보여도 결과가 크다. 추출과 품질 측정이 같은 단계에서 일어난다는 뜻이기 때문이다. 예전 파이프라인은 문서를 OCR로 텍스트화한 뒤, 그 텍스트가 쓸 만한지를 가리는 품질 검증 단계를 따로 두고, 그다음 사람이 검토한 뒤에야 DB에 넣었다. OCR 4는 이 흐름을 압축한다. 추출 결과에 이미 단어별 점수가 박혀 있으니, 임계값 하나로 곧장 분기할 수 있다.
효과는 인간 검토의 위치가 바뀌는 데 있다. "모든 문서"를 사람이 훑던 방식이, "점수가 낮은 단어가 있는 문서"만 사람에게 가는 방식으로 옮겨간다. 검토 인력을 정말 위험한 곳에 집중시킬 수 있고, 어떤 단어가 왜 검토 대상이 됐는지가 점수로 남으니 감사 추적도 자연스럽게 따라온다. 금융·의료·법무처럼 오독 한 글자가 규정 위반으로 이어지는 분야에서 이 구분은 비용이 아니라 안전장치다.
미스트랄이 공개한 초기 도입 사례도 같은 방향을 가리킨다. 한 금융 서비스 고객은 기존 대비 페이지당 처리 속도가 네 배 빨라졌다고 한다. 또 다른 고객은 에이전트형 문서 파서를 쓰던 때와 비교해 비용을 여덟 배 줄이고 지연을 열일곱 배 낮췄다. 별도 검증 단계를 걷어내고 구조화된 출력을 파이프라인으로 그대로 흘려보낼 때 생기는 차이다.
데이터 품질의 관점에서 보면 변화는 더 분명하다. 그동안 품질 점수는 추출이 끝난 뒤 별도 도구로 사후에 매기는 지표였다. OCR 4에서는 그 점수가 추출 출력에 처음부터 들어 있다. 품질이 파이프라인 바깥의 검사 항목이 아니라, 데이터가 태어나는 순간 함께 박히는 속성이 된 것이다.
출처와 주권, 한 단계에서 풀린다
위치 좌표와 블록 분류는 RAG에서 곧장 쓸모를 낸다. bounding box가 있으면 추출된 텍스트가 원본의 몇 페이지, 어느 위치에서 왔는지 역추적할 수 있다. 블록 유형까지 알면 본문 문장과 표 안의 수치를 구분해 검색에 반영할 수 있다. "이 답변은 계약서 3페이지 표의 두 번째 행에서 나왔습니다" 수준의 출처 추적이 가능해지는 이유다. 미스트랄은 OCR 4를 자사 Search Toolkit의 문서 수집 레이어로 연결해, 추출에서 검색까지 한 줄로 잇는 그림을 그리고 있다.

또 하나의 축은 자체 호스팅이다. OCR 4는 단일 컨테이너로 온프레미스 배포가 가능하다. AWS Textract나 Google Document AI가 클라우드 전용이라 문서를 반드시 외부로 전송해야 하는 것과 갈라지는 지점이다. 미스트랄은 프랑스 법인이라 관할권도 EU 안에 있다. 민감 문서가 조직 인프라를 떠나지 않는다는 것은 GDPR이나 한국 개인정보보호법 아래에서 움직이는 금융·의료·공공·법무 조직에는 결정적 조건이다.
출처 추적과 데이터 주권은 보통 따로 푸는 문제였다. 출처는 RAG 설계로, 주권은 인프라 정책으로. OCR 4는 두 문제를 추출 단계 하나로 끌어와 동시에 다룬다. 답변의 근거를 표 한 칸까지 짚으면서도, 그 문서가 클라우드로 나가지 않게 한다.
무엇을 선택할 것인가
OCR 4가 모든 상황의 정답은 아니다. 선택은 조직이 이미 어디에 발을 들여놓았는지, 무엇을 가장 중요하게 보는지에 달린다. AWS 생태계에 깊이 묶여 있다면 Textract가, BigQuery 중심으로 데이터를 운영한다면 Google Document AI가 자연스럽다. 특히 화질이 나쁜 스캔 처리에서는 Document AI가 여전히 강점을 보인다.
OCR 4가 또렷하게 앞서는 자리는 따로 있다. 멀티언어 문서를 다루면서, 자체 호스팅이 필요하고, 단어 단위 품질 신호를 파이프라인에 직접 쓰려는 조직이다. 가격은 표준 API가 1,000페이지당 $4, 배치가 $2, 스키마 기반 Document AI가 $5다. OCR 3의 $2에서 두 배로 올랐다는 점, 자체 호스팅 단가는 영업 문의로 비공개라는 점은 도입 전에 따져야 할 변수다.
결국 판단의 기준은 하나로 모인다. 데이터 품질을 파이프라인의 부가 기능으로 보는가, 아니면 설계의 중심에 두는가. 추출 단계에서부터 품질 신호를 출력에 박아 두려는 조직이라면, OCR 4가 제시한 방향은 단순한 OCR 교체 이상의 의미를 가진다.
Editor's Note
페블러스가 이 발표를 데이터 품질의 관점에서 읽는 이유는 분명하다. 비정형 문서를 AI에 연결하는 일은 늘 추출의 품질에서 막혀 왔고, 그 품질을 어떻게 측정하고 어디서 사람의 손을 빌릴지가 실제 현장의 난제였다. 단어 단위 신뢰도가 추출 출력에 들어온다는 것은, 품질 측정이 파이프라인의 별도 단계가 아니라 데이터의 속성으로 옮겨간다는 신호다. 추출이 곧 품질 평가가 되는 흐름은, 페블러스가 데이터 품질 진단을 다루며 마주하는 문제와 정확히 같은 자리에 있다.
참고문헌
공식 문서
- 1.Mistral AI. (2026년 6월 23일). "Mistral OCR 4: SOTA OCR for Document Intelligence." Mistral AI.
업계·보도
- 2.MarkTechPost. (2026년 6월 23일). "Mistral Releases OCR 4 for Structure-Aware Document Intelligence." MarkTechPost.
- 3.VentureBeat. (2026년 6월 23일). "Mistral launches OCR 4, turning document extraction into a full enterprise AI play." VentureBeat.
- 4.TechTimes. (2026년 6월 24일). "Mistral OCR 4 Ships Structure-Aware Document AI That Runs on Your Own Infrastructure." TechTimes.