Executive Summary
2026년 6월 10일, 이스라엘 스타트업 Jedify가 Norwest 주도로 시리즈A $24M을 받았다. Snowflake Ventures가 전략 투자자로 합류했다. 흥미로운 건 이 회사가 파는 물건이다. 모델도, GPU도 아니다. 기업의 흩어진 데이터를 엮어 AI 에이전트가 읽을 수 있는 "컨텍스트 그래프"를 만든다. 이 글은 그 한 건의 펀딩을 통해, 컨텍스트 레이어가 어떻게 차세대 B2B AI 투자 카테고리로 떠올랐는지를 본다.
배경에는 Q1 2026 한 분기에만 벤처 자본 $300B가 풀린 비정상적 시장이 있다. 그중 81%가 AI로 쏠렸다. 자본은 컴퓨트와 추론에 먼저 몰렸고, 컨텍스트는 가장 늦게 채워지는 빈 예산 항목으로 남았다. 그런데 에이전트는 사람보다 수백 배 많은 데이터를 요청한다. 사람 규모로 설계된 검색(RAG)으로는 감당이 안 된다. Jedify의 $24M은 그 공백을 노린 베팅이다.
그리고 한 가지 불편한 진실이 따라온다. 컨텍스트 레이어가 아무리 정교해도, 그것이 참조하는 내부 데이터가 오래되거나 부정확하면 결과는 똑같이 틀린다. 컨텍스트 레이어의 성패는 결국 데이터 품질과 거버넌스로 수렴한다.
주요 수치
출처: TechCrunch·GlobeNewswire(2026-06-10), Crunchbase News·TechRound(Q1 2026), CData(2026)
$24M
Jedify 시리즈A
누적 $33M, Norwest 리드·Snowflake Ventures 참여
81%
Q1 2026 AI 비중
전체 벤처 $300B 중 $242B가 AI로 집중
10%→33%
하이브리드 리트리벌 도입 의도
2026년 1~3월 3배 증가, RAG 한계 신호
97M
MCP SDK 월 다운로드
11개월 만에 100K에서 970배 증가
에이전트가 거짓말을 하는 진짜 이유
2026년 들어 엔터프라이즈 현장에서 AI 에이전트 도입이 빠르게 늘었다. 그리고 거의 동시에, 같은 세 가지 불만이 반복해서 올라왔다. 에이전트가 그럴듯하게 틀린 답을 내놓는다(할루시네이션). 토큰 비용이 예상보다 가파르게 오른다. 접근해선 안 될 데이터를 끌어오거나, 정작 필요한 권한 정보를 놓친다.
흔한 진단은 "LLM이 원래 그렇다"는 것이다. 모델의 한계로 치부하면 마음은 편하다. 그런데 현장을 들여다본 보고들은 다른 결론을 가리킨다. 할루시네이션의 상당 부분은 모델이 아니라 모델이 먹은 데이터 탓이다. 복제본끼리 값이 어긋나거나, 같은 고객이 시스템마다 다른 ID로 쪼개져 있거나, 어제까지 유효했던 정보가 오늘은 낡아 있는 경우다. 정확한 맥락 없이 그럴듯한 문장을 만들라고 하면, 모델은 정확히 그럴듯한 거짓말을 만든다.
Jedify의 초기 고객 사례가 이 점을 잘 보여 준다. 보안 협업 기업 Kiteworks는 Jedify를 기반으로 영업 도구를 만들었다. 영업 담당자가 고객과 대화하는 그 순간에, 실시간 고객 인텔리전스를 옆에서 띄워 주는 도구다. 이런 도구는 정확하고 최신인 고객 맥락 없이는 성립하지 않는다. 맥락이 어긋나면 영업 사원에게 틀린 정보를 자신 있게 속삭이는 셈이 된다. 문제는 "AI가 똑똑하냐"가 아니라 "AI가 무엇을 보고 있느냐"로 옮겨 간다.
관점을 바꾸면 데이터 조직의 역할도 바뀐다. 데이터를 저장하고 분석가에게 넘기던 팀이, 이제는 에이전트가 신뢰할 수 있는 실시간 맥락을 공급하는 팀이 된다. "할루시네이션 줄이기"는 모델 튜닝 과제가 아니라 데이터 공급 과제가 된다.
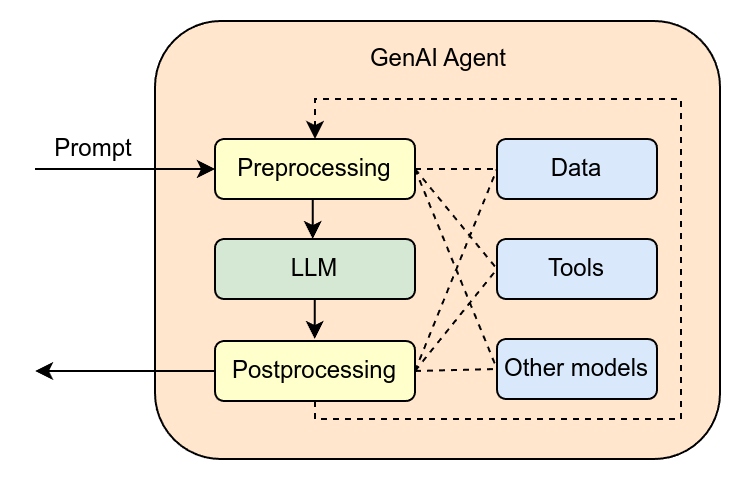
컨텍스트 레이어란 무엇인가
"컨텍스트 레이어"라는 말은 새롭지만, 가리키는 문제는 오래됐다. AI 에이전트가 일을 제대로 하려면 회사가 어떻게 돌아가는지를 알아야 한다. 누가 고객이고, 어떤 제품이 있고, 어떤 규칙과 권한이 걸려 있고, 어떤 용어를 쓰는지. 이 지식은 데이터 웨어하우스에도, 문서에도, Slack 대화에도, 회의 녹음에도 흩어져 있다. 컨텍스트 레이어는 이 흩어진 조각을 에이전트가 읽을 수 있는 하나의 모델로 엮는 계층이다.
기존 개념과 헷갈리기 쉽다. 의미층(Semantic Layer)은 주로 데이터 웨어하우스 위에 정적인 지표 정의를 얹는다. 메타데이터 카탈로그는 어떤 데이터가 어디 있는지를 설명하는 문서 역할에 가깝고, 자동 갱신과는 거리가 있다. 검색 기반의 RAG는 질문이 들어올 때마다 관련 문서를 찾아 붙인다. Jedify가 말하는 컨텍스트 그래프는 이들과 결이 다르다. 실시간으로 갱신되고, 구조화·비구조화 데이터를 함께 다루며, 처음부터 사람이 아니라 에이전트가 소비하도록 설계된다.
2.1Jedify의 컨텍스트 그래프
Jedify는 기업의 지식 소스를 API로 연결해, 엔티티·데이터·권한·도메인 지식·워크플로우·회사 용어 사이의 관계를 실시간으로 포착하는 다차원 의미 모델을 만든다고 설명한다. 구조화 데이터 쪽은 데이터 웨어하우스, CRM, 재무 시스템, BI 도구를 끌어오고, 비구조화 쪽은 문서, 플레이북, Slack, 회의 녹음, 코드를 끌어온다. 이를 묶는 독점 기술의 이름이 Semantic Fusion이다. 회사는 이것이 진정한 의미층이며, 정적인 메타데이터 카탈로그와는 구별된다고 강조한다.
에이전트 입장에서 이득은 두 가지다. 정확한 비즈니스 맥락에 접근하니 할루시네이션이 줄고, 필요한 부분만 정제해 받으니 토큰 낭비가 준다. 다음 표는 RAG와 컨텍스트 아키텍처가 어디서 갈라지는지를 정리한 것이다.
| 항목 | RAG (검색 증강) | 컨텍스트 아키텍처 |
|---|---|---|
| 설계 기준 | 사람 사용자 규모 쿼리 | 에이전트 규모 (수백 배 많은 요청) |
| 데이터 소스 | 주로 구조화 + 문서 | 구조화 + 비구조화 + 권한 그래프 |
| 업데이트 | 배치·주기적 | 실시간 |
| 의미 정보 | 제한적 | 깊은 관계 매핑 |
| 할루시네이션 위험 | 중간 | 낮음 (정확한 맥락 전제) |
| 토큰 효율 | 낮음 | 높음 (압축·필터링) |
표의 비교축은 VentureBeat(2026)와 CIO(2026)의 정리를 따랐다.
$300B 시장과 빈 예산 항목
Jedify의 $24M은 진공 속에서 나온 돈이 아니다. Q1 2026 한 분기에만 글로벌 벤처 투자가 $300B를 넘겼다. 약 6,000개 스타트업이 그 자금을 나눠 가졌고, 그중 $242B(80~81%)가 AI로 흘러갔다. 지역으로 보면 미국 집중도가 83%에 달했다. 한 분기의 투자액이 2025년 한 해 투자의 약 70%를 흡수한 셈이다.
숫자를 키운 주인공은 메가라운드다. OpenAI $122B, Anthropic $30B 같은 거대 라운드가 평균을 끌어올렸다. 반대편에서는 비AI 분야의 시드 딜이 약 30% 줄었다. 자본이 AI로 쏠리며 나머지가 마른 것이다. 이 쏠림은 양날의 검이다. AI 인프라에는 돈이 넘치지만, 그 돈이 모든 계층에 고르게 가지는 않는다.
3.1자본이 비껴간 자리, 컨텍스트
에이전트를 실제로 돌려 보면 필요한 스택이 또렷해진다. 컴퓨트와 추론이 맨 아래에 있고, 그 위로 오케스트레이션(여러 에이전트 조율), 컨텍스트(에이전트가 참조할 맥락), 옵저버빌리티(모니터링·감사), 보안이 쌓인다. 투자 흐름은 아래쪽에 먼저 몰렸다. 컴퓨트와 추론, 오케스트레이션에는 자본이 충분했지만, 컨텍스트와 옵저버빌리티는 상대적으로 비어 있었다.
바로 그 빈자리가 Jedify의 $24M이 가리키는 지점이다. 투자자가 컨텍스트 레이어를 독립된 카테고리로 인정하기 시작했다는 신호다. 같은 무렵 Portkey가 에이전트 제어로 $15M 시리즈A를 받았고, Compresr가 컨텍스트 압축으로 Y Combinator 무대에 올랐다. 한 회사의 일이 아니라, 한 계층이 통째로 자본의 관심에 들어온 사건으로 읽는 편이 정확하다.
RAG에서 컨텍스트 아키텍처로
몇 년간 엔터프라이즈 AI의 기본기는 RAG였다. 질문이 들어오면 관련 문서를 검색해 모델에 붙여 주는 방식이다. 사람 한 명이 가끔 질문하는 패턴에는 잘 맞았다. 그런데 에이전트는 다르게 일한다. 하나의 작업을 풀기 위해 수십, 수백 번 데이터를 들락거린다. 사람 규모로 설계된 리트리벌 레이어가 에이전트 규모의 부하 앞에서 한계를 드러낸다.
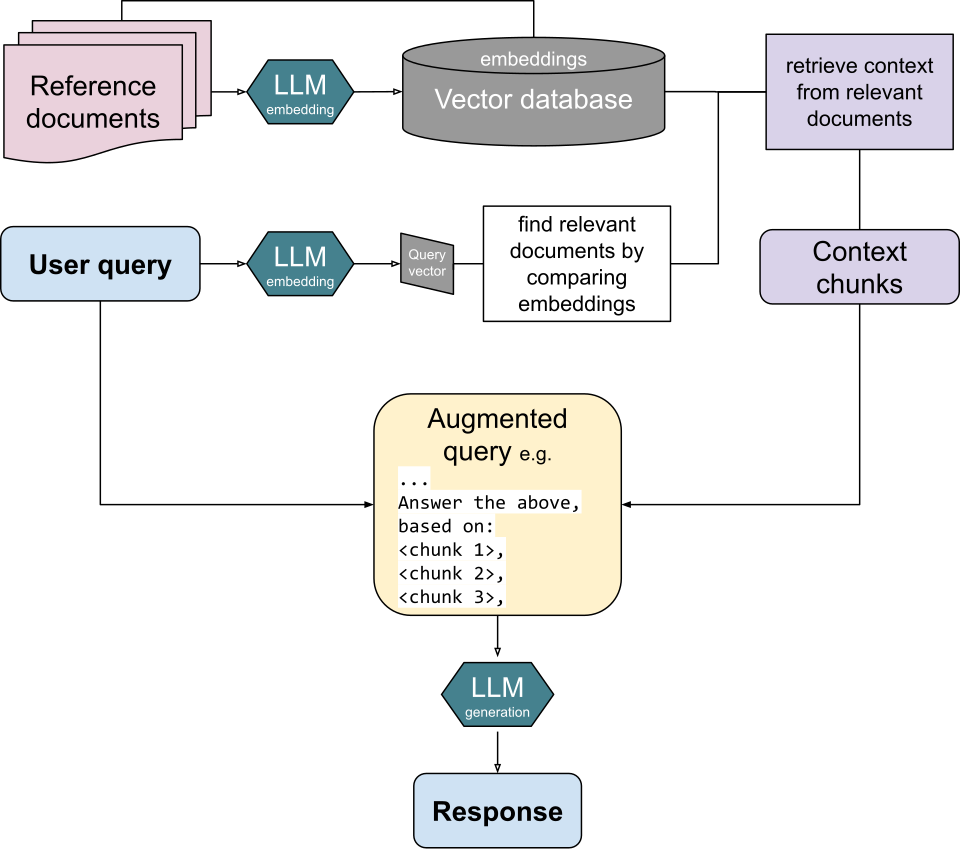
시장은 이 한계를 빠르게 체감하는 중이다. 한 조사에 따르면 2026년 1월에서 3월 사이, 하이브리드 리트리벌을 도입하겠다는 의도가 10.3%에서 33.3%로 석 달 만에 세 배 가까이 뛰었다. 순수 검색을 넘어, 실시간 갱신과 똑똑한 필터링을 결합한 구조로 넘어가려는 움직임이다. RAG가 죽었다는 뜻은 아니다. RAG가 더 큰 컨텍스트 아키텍처의 한 부품으로 흡수되는 과정에 가깝다.
이 전환을 떠받치는 도구들도 함께 자란다. Compresr는 LLM 파이프라인용 컨텍스트 압축 API를 내세우는데, 정확도를 유지하면서 최대 100배까지 압축한다고 주장한다. Redis와 AWS, 그리고 Anthropic의 MCP는 에이전트와 데이터 사이에 컨텍스트·메모리 플랫폼을 깔았다. 컨텍스트를 잘 만드는 일과 그 컨텍스트를 효율적으로 실어 나르는 일이, 별개의 시장으로 동시에 커지고 있다.
Jedify는 왜 $24M을 모았나
이번 라운드는 Norwest Venture Partners가 이끌었다. 기존 투자자인 S Capital VC와 Cerca Partners가 다시 참여했고, Oceans Ventures가 신규로 들어왔다. 눈에 띄는 이름은 Snowflake Ventures다. 데이터 플랫폼 기업이 전략 투자자로 합류했다는 건, Jedify의 컨텍스트 레이어를 자사 데이터 스택과 보완 관계로 본다는 뜻으로 읽힌다. CEO이자 공동창업자는 Assaf Henkin이다. 시드를 포함한 누적 조달은 $33M에 이른다.
자금은 세 곳에 쓰인다. 제품 개발(컨텍스트 그래프 고도화), 영업·마케팅 등 고-투-마켓 확대, 그리고 인력 확충이다. 평범한 시리즈A 용처지만, 타이밍이 평범하지 않다. 에이전트 도입이 가속하고, 토큰 비용 압박이 커지고, 거버넌스가 덜 잡힌 기업의 고통이 쌓이는 국면이다. 컨텍스트 레이어를 파는 회사에게는 시장이 스스로 열리고 있는 셈이다.
고객 면면도 전략을 드러낸다. 현재 초기 도입자는 10~20곳 수준이고, 그중 Kiteworks와 The Weather Company 같은 이름이 알려져 있다. 산업으로는 게임, 산업재(industrials), 소비재(CPG)처럼 데이터가 많고 복잡한 분야에 먼저 발을 들였다. 데이터가 풍부할수록 컨텍스트 그래프의 가치가 크다는 가설에 충실한 선택이다.
컨텍스트 레이어의 숨은 조건
여기서 한 발 물러나 질문을 던져 보자. 컨텍스트 레이어를 깔면 정말 할루시네이션이 사라질까. 답은 "데이터가 깨끗할 때만"이다. 컨텍스트 그래프는 회사의 데이터를 비추는 거울이지, 데이터를 고쳐 주는 마법이 아니다. 거울에 비친 원본이 흐리면, 아무리 좋은 거울을 써도 흐린 상이 나온다.
할루시네이션의 실제 원인을 풀어 보면 거의 데이터 문제로 귀결된다. 복제본 사이의 값 불일치, 같은 고객이 시스템마다 다른 ID로 나뉘는 엔티티 불일치, 그리고 거버넌스 부재. 거버넌스가 없으면 AI는 "접근할 수 있는 데이터"와 "접근해도 되는 데이터"를 구분하지 못한다. 권한이 없는 정보까지 끌어와 그럴듯한 답을 만든다. 이는 정확도 문제이자 보안 문제다.
6.1데이터 품질의 여섯 축
업계가 오래 합의해 온 데이터 품질의 기준은 여섯 가지로 정리된다. 정확성, 완전성, 일관성, 유효성, 유일성, 적시성. 이 여섯이 무너진 데이터를 컨텍스트 레이어가 아무리 잘 엮어도, 에이전트는 그 위에서 똑같이 미끄러진다.
- •정확성·적시성 — 값이 맞고, 지금 시점에도 유효한가. 오래된 가격·재고가 에이전트의 거짓말을 만든다.
- •일관성·유일성 — 같은 고객이 한 사람으로 묶이는가. 엔티티가 쪼개지면 컨텍스트 그래프의 관계 매핑도 쪼개진다.
- •완전성·유효성 — 빠진 필드 없이, 정해진 형식을 지키는가. 비어 있는 맥락은 에이전트가 상상으로 메운다.
그래서 흥미로운 역설이 생긴다. Jedify가 한 기업의 엔티티 관계를 깔끔하게 매핑할 수 있다는 건, 그 기업의 데이터 거버넌스가 이미 성숙했다는 신호다. 반대로 컨텍스트 그래프가 잘 안 그려지는 기업이라면, 컨텍스트 레이어 도입 자체가 데이터 정책을 대대적으로 손보게 만드는 드라이버가 된다. 어느 쪽이든, "컨텍스트 레이어 도입"은 사실상 "데이터 조직 성숙도 업그레이드"와 같은 말이 된다.
MCP와 생태계
Jedify는 혼자가 아니다. 에이전트 인프라라는 큰 그림 안에서 여러 회사가 각자의 조각을 만든다. 컨텍스트 레이어는 Jedify가, 컨텍스트 압축은 Compresr가, 에이전트 제어는 Portkey가 맡는 식이다. Portkey는 권한·신원·예산 관리를 묶은 에이전트 제어 플랫폼으로 $15M 시리즈A를 받았고, 2026년 6월 Palo Alto Networks에 인수됐다. 보안 대기업이 에이전트 제어를 사들였다는 점이 이 계층의 무게를 말해 준다.
이 조각들을 잇는 표준이 MCP(Model Context Protocol)다. Anthropic이 시작한 이 프로토콜은 에이전트와 데이터를 연결하는 공통 규약으로, 한때 월 100K였던 SDK 다운로드가 11개월 만에 97M으로 970배 뛰었다. 공개 서버는 1만 개를 넘었고, ChatGPT·Cursor·Gemini·Microsoft Copilot·VS Code 등 주요 도구가 모두 지원한다. 2025년 12월 Anthropic은 MCP를 Linux Foundation 산하 재단에 기증해 벤더 중립 오픈 스탠다드로 격상했다.
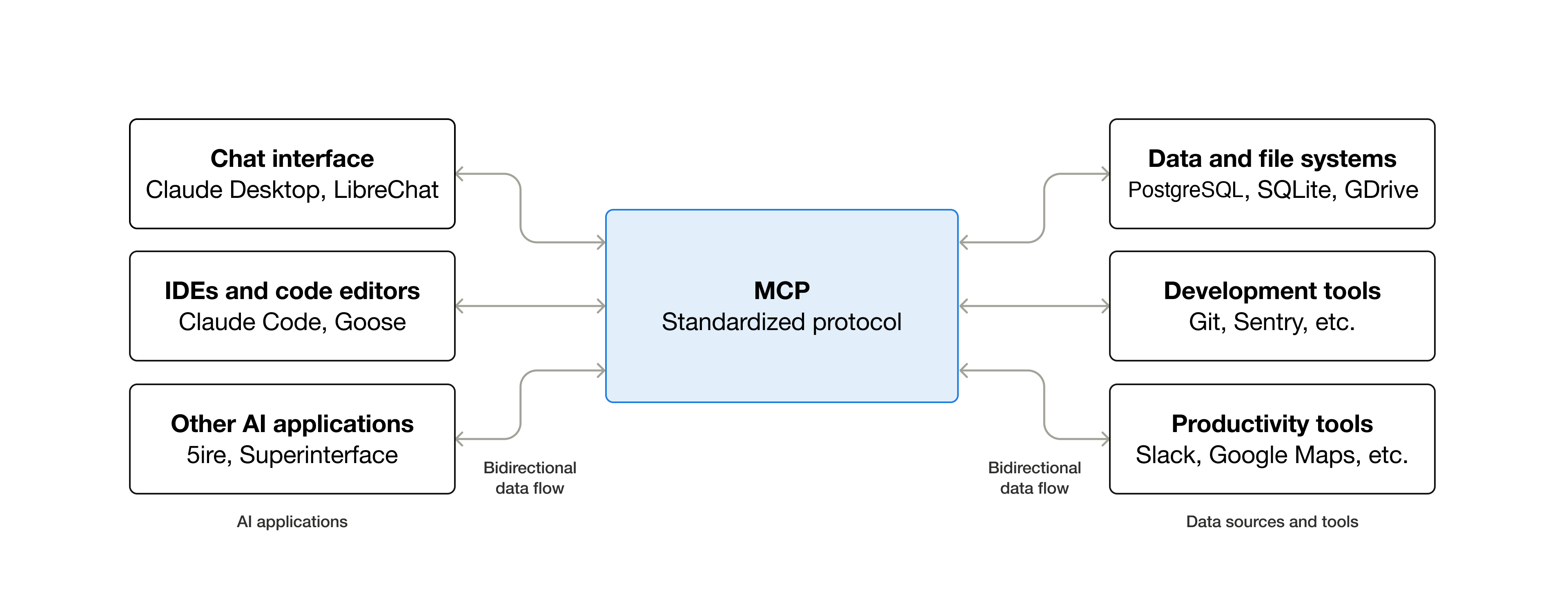
엔터프라이즈 채택도 빠르다. 한 조사에서 소프트웨어 조직의 41%가 MCP를 제한적이거나 광범위한 프로덕션 단계에서 쓰고 있었고, Forrester는 2026년 안에 엔터프라이즈 앱 벤더의 30%가 자체 MCP 서버를 낼 것으로 봤다. 다만 갈 길도 남았다. 감사 추적, SSO 통합 인증, 게이트웨이 제어 같은 엔터프라이즈 준비도가 2026년의 우선 과제로 꼽힌다. MCP가 에이전트-데이터 연결의 "HTTP"가 될지는 이 준비도를 얼마나 빨리 채우느냐에 달렸다.
기업의 다음 스텝
2026~2027년에 에이전트를 본격 도입하려는 기업이라면, 인프라 예산을 다섯 줄로 나눠 볼 만하다. 컴퓨트, 오케스트레이션, 컨텍스트, 옵저버빌리티, 보안이다. 지금 대부분의 예산은 위쪽 두세 줄에 몰려 있다. 컴퓨트와 추론은 이미 과포화에 가깝고, 가장 비어 있는 칸이 컨텍스트다. CDO들 사이에서 컨텍스트 인프라가 "2026년 AI 예산에서 빠진 항목"으로 불리는 이유다.
실무적으로는 순서가 중요하다. 컨텍스트 레이어 도구를 도입하기 전에, 그것이 비출 데이터부터 점검해야 한다. 엔티티가 통합돼 있는가. 권한 정책이 데이터에 붙어 있는가. 최신성이 보장되는가. 이 점검 없이 도구만 얹으면, 비싼 거울로 흐린 상을 더 또렷하게 확대하는 결과가 된다.
결국 데이터 조직의 역할이 다시 정의된다. 과거의 임무가 "데이터를 저장하고 분석가에게 전달"이었다면, 앞으로의 임무는 "에이전트가 믿고 쓸 수 있는 실시간 맥락을 공급"하는 것이다. 컨텍스트 레이어 시장이 커질수록, 그 시장을 떠받치는 토대가 데이터 품질과 거버넌스라는 사실이 더 또렷해진다.
에디터스 노트 — 페블러스의 관점
이 글이 추적한 자본 흐름은 결국 한 문장으로 모인다. 에이전트의 똑똑함은 그것이 보는 데이터만큼이다. 페블러스가 "AI-Ready Data"라는 이름으로 다뤄 온 문제, 곧 데이터의 정확성·일관성·적시성·거버넌스가, 이제 투자자들이 컨텍스트 레이어라는 새 간판으로 다시 발견하고 있는 그 토대다. 도구는 바뀌어도 토대는 같다. 컨텍스트 레이어에 예산을 편성하기 전에, 그 레이어가 비출 데이터가 준비됐는지를 먼저 묻는 것. 그것이 우리가 이 트렌드에서 읽는 가장 실용적인 함의다.
읽어 주셔서 감사합니다. 컨텍스트 레이어와 AI-Ready 데이터에 대한 의견이나 사례가 있다면 언제든 나눠 주세요.
참고문헌
1차 보도·공식 발표
- 1.TechCrunch. (2026). "Jedify raises $24M to help companies arm AI agents with context on their business." TechCrunch, 2026-06-10. — Jedify 펀딩·컨텍스트 그래프·CEO·투자자·고객 사례.
- 2.Jedify (GlobeNewswire). (2026). "Jedify Raises $24 Million in Series A Funding to Build Context Graphs for Enterprise AI Agents." GlobeNewswire, 2026-06-10. — Semantic Fusion·자금 사용처·누적 자금.
- 3.The SaaS News. (2026). "Portkey Raises $15 Million Series A." The SaaS News. — Portkey 시리즈A, Elevation Capital 리드.
- 4.Y Combinator. (2026). "Launch YC: Compresr — Context Compression for LLM Pipelines and Agents." Y Combinator. — Compresr 100배 컨텍스트 압축.
시장·업계 분석
- 5.TechRound. (2026). "Investors Poured $300 Billion Into Startups In Q1 2026 And AI Claimed 80% Of It." TechRound. — Q1 2026 벤처 $300B, AI 81%.
- 6.Crunchbase News. (2026). "Q1 2026 Shatters Venture Funding Records, Powered By AI." Crunchbase News. — $300B, OpenAI·Anthropic 메가라운드, 지역 분포.
- 7.VentureBeat. (2026). "Context architecture is replacing RAG as agentic AI pushes enterprise retrieval to its limits." VentureBeat. — 하이브리드 리트리벌 33%, 에이전트 규모 데이터 요청.
- 8.CIO. (2026). "The agentic infrastructure overhaul: 3 non-negotiable pillars for 2026." CIO. — 에이전트 인프라 계층(컨텍스트·메모리·오케스트레이션).
- 9.CData. (2026). "2026: The Year for Enterprise-Ready MCP Adoption." CData. — MCP 97M 월 다운로드, 1만+ 공개 서버.
- 10.Truthifi. (2026). "State of MCP 2026: How AI Agents Connect to Your Data." Truthifi. — MCP 970배 증가, Linux Foundation 거버넌스.
- 11.Atlan. (2026). "Agent Context Layer Tools: The Complete Directory." Atlan. — 컨텍스트 레이어 도구 비교.
- 12.Sky9 Capital. (2026). "AI Agent Startups: What's Getting Built and Funded." Sky9 Capital. — 에이전트 스타트업 펀딩 트렌드.
데이터 거버넌스·품질
- 13.Promethium AI. (2026). "Building AI Agents That Don't Hallucinate on Enterprise Data." Promethium AI. — 할루시네이션 원인=데이터 품질.
- 14.SOLIX. (2026). "AI Hallucination Prevention: Why Enterprise Data Governance Is the Only Reliable Fix." SOLIX. — 데이터 거버넌스와 할루시네이션 예방.
- 15.CDO Magazine. (2026). "The Missing Line Item in Your 2026 AI Budget: Context Infrastructure." CDO Magazine. — 2026 AI 예산에서 컨텍스트 인프라 부상.
- 16.Informatica. (2026). "Enterprise AI Agent Engineering & Data Infrastructure." Informatica. — 에이전트 데이터 인프라·거버넌스.