Executive Summary
많은 AI 프로젝트가 좋은 모델을 두고도 기대만큼의 결과를 내지 못합니다. 원인을 모델 아키텍처나 프롬프트에서 찾기 쉽지만, 실패의 상당 부분은 그 이전 단계, 즉 데이터에서 시작됩니다. 이 글은 "우리 데이터가 AI에 쓸 수 있는 상태인가"라는 질문에 직관이 아니라 구체적 기준으로 답하기 위한 안내서입니다.
데이터 분석 기업 Monte Carlo의 조사에서 생성형 AI 프로젝트의 약 30%가 데이터 품질 문제로 좌초한 것으로 보고됐습니다. 모델을 바꾸기보다 데이터를 정돈하는 편이 더 큰 성능 개선을 낳는 경우가 적지 않다는 뜻입니다. AI-Ready Data는 완벽한 데이터가 아니라, 사용 목적에 맞는 품질을 갖추고 출처와 변환 이력이 추적되며 접근과 책임이 관리되는 데이터를 말합니다.
아래에서는 AI-Ready Data의 정의, 모델 성능과 직결되는 품질의 일곱 차원, 메타데이터와 계보(lineage)의 역할, 거버넌스가 왜 LLM·에이전트 시대에 더 무거워졌는지, 그리고 RAG와 에이전트 환경에서 추가로 필요한 조건을 차례로 다룹니다. 마지막 장에는 오늘부터 적용할 수 있는 단계별 체크포인트를 담았습니다.
주요 수치
아래 네 숫자는 같은 이야기를 서로 다른 각도에서 보여 줍니다. 생성형 AI 프로젝트의 약 30%가 모델이 아니라 데이터 품질 때문에 멈추고, LLM이 사실과 다른 답을 내는 환각의 원인 가운데 절반이 넘는 55%가 데이터에서 비롯됩니다. 반대로 데이터를 검색 가능한 형태로 잘 준비해 붙이면 환각률이 50%에서 13.9%까지 내려갑니다. 이런 흐름을 뒷받침하듯, 데이터의 출처와 변환 이력을 추적하는 계보 시장은 해마다 23.1%씩 커지고 있습니다.
출처: Monte Carlo, IJCOA·SQ Magazine, arXiv 2411.12759, GlobeNewswire(2026-04)
30%
데이터발 실패
생성형 AI 프로젝트가 데이터 품질로 좌초
55%
할루시네이션 원인
LLM 환각 원인 중 데이터 관련 비중
50→13.9%
RAG 효과
검색 증강 도입 전후 환각률 변화
23.1%
계보 시장 CAGR
데이터 계보 시장 연평균 성장률
AI-Ready Data란 무엇인가
"좋은 데이터"라는 말은 오래전부터 있었습니다. 오타가 없고, 빈칸이 적고, 형식이 통일된 데이터. 이런 기준은 사람이 보고서를 읽거나 대시보드를 만들 때는 충분했습니다. 그러나 데이터를 사람이 아니라 모델이 학습하고 추론에 쓰기 시작하면서, "쓸 만하다"의 기준점이 옮겨졌습니다. AI-Ready Data는 바로 이 옮겨진 기준을 가리키는 말입니다.
Gartner는 AI-Ready Data를 "해당 AI 사용 목적에서 나타날 수 있는 모든 패턴, 오류, 예외 상황을 대표하는 데이터"로 정의합니다. 핵심은 "사용 목적"이라는 조건입니다. 같은 데이터라도 무엇에 쓰느냐에 따라 준비 여부가 달라집니다. 사실 검색용 문서를 모델 학습에 그대로 넣으면 부족하고, 학습용으로 정제한 데이터가 실시간 추천에는 너무 오래된 것일 수 있습니다.
1.1사용 목적마다 달라지는 요구사항
AI가 데이터를 쓰는 방식은 크게 네 가지입니다. 대규모 사전학습(Training), 특정 작업에 맞춘 미세조정(Fine-tuning), 추론 시점에 외부 문서를 검색해 붙이는 RAG, 그리고 도구를 호출하며 스스로 일을 진행하는 에이전트. 각 방식이 데이터에 요구하는 것이 다릅니다. 학습은 방대한 양과 대표성을 원하고, RAG는 검색 가능한 구조와 출처의 신뢰도를 원하며, 에이전트는 접근 권한과 행동 기록의 추적성을 요구합니다.
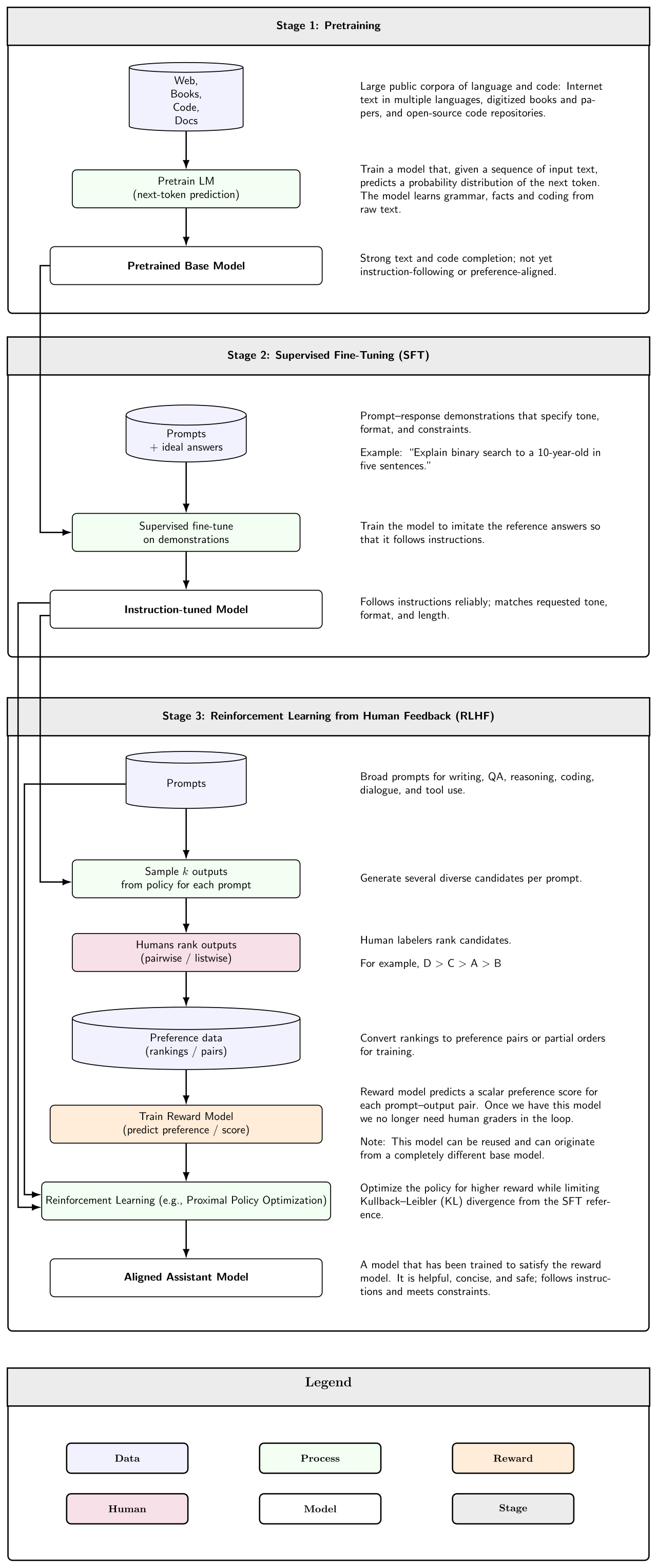
1.2전통적 '깨끗한 데이터'와의 차이
전통적 데이터 품질이 정확성과 형식의 일관성에 집중했다면, AI-Ready Data는 여기에 세 가지를 더합니다. 첫째는 대표성입니다. 실제로 마주칠 상황의 분포를 데이터가 닮아야 합니다. 둘째는 계보입니다. 데이터가 어디서 와서 어떻게 바뀌었는지 따라갈 수 있어야 합니다. 셋째는 거버넌스입니다. 누가 어떤 권한으로 접근하고 책임지는지가 정해져 있어야 합니다. 이 세 가지가 빠지면 데이터가 깨끗해 보여도 AI에 안심하고 쓰기 어렵습니다.
한 줄 정의: AI-Ready Data는 특정 AI 사용 목적에 맞게 정확성·완전성·일관성·적시성·대표성을 갖추고, 출처와 변환 이력이 추적되며, 접근과 책임이 관리되는 데이터입니다. "완벽한 데이터"가 아니라 "목적에 맞게 준비되고 추적되는 데이터"입니다.
데이터 품질의 일곱 차원이 모델 성능을 가른다
데이터 품질은 하나의 점수가 아니라 여러 축으로 나뉩니다. IBM과 학계의 데이터 품질 서베이는 보통 여덟 안팎의 차원을 제시하는데, AI 맥락에서 특히 중요한 일곱 가지를 모델 성능과 연결해 정리하면 다음과 같습니다. 차원마다 "무너지면 모델이 어떻게 실패하는가"를 함께 보면, 추상적인 품질 논의가 구체적인 진단 항목으로 바뀝니다.
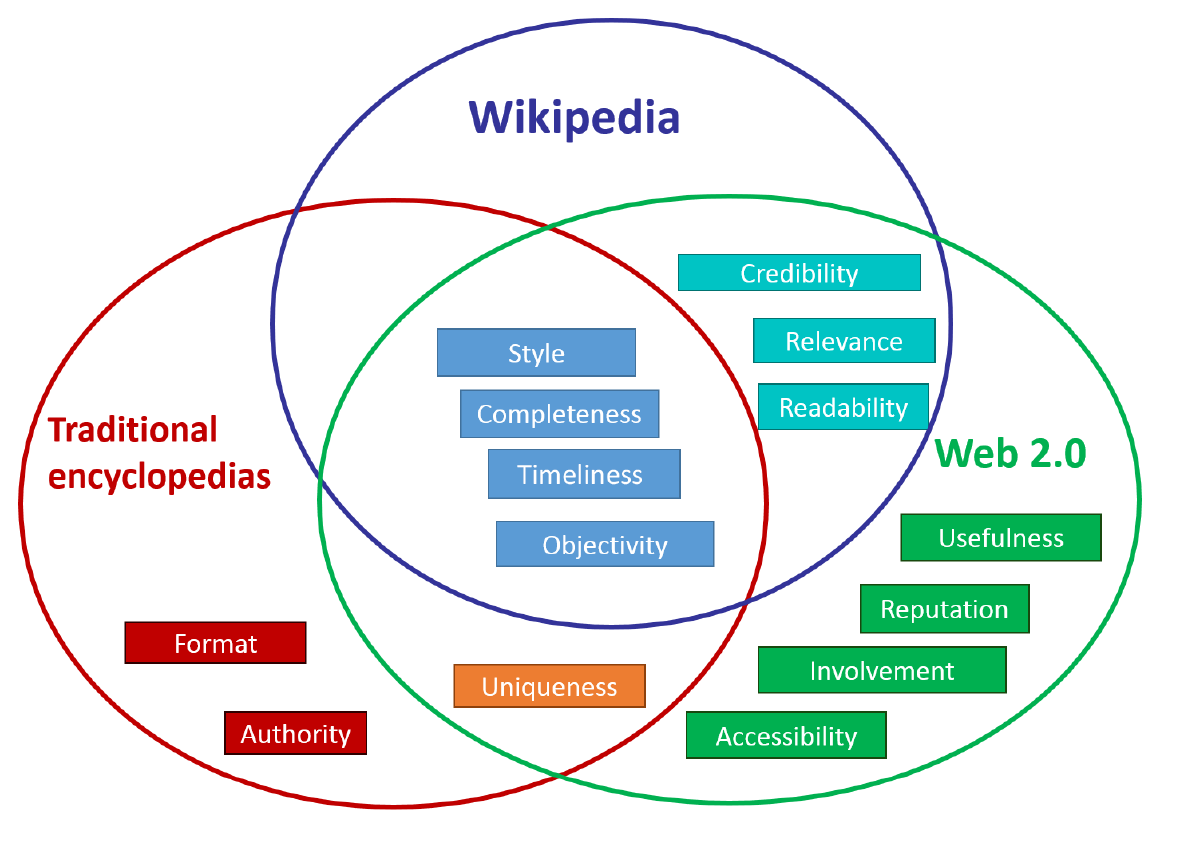
2.1기초 네 차원
가장 오래된 네 가지 축은 지금도 가장 자주 무너지는 지점입니다.
- • 정확성(Accuracy): 값이 사실과 일치하는가. 틀린 데이터로 학습하면 모델은 틀린 패턴을 사실로 받아들이고, 그 위에 쌓인 정확도 숫자는 진실과 무관한 숫자가 됩니다.
- • 완전성(Completeness): 필요한 값이 빠짐없이 있는가. 결측이 많으면 모델은 일부 패턴을 아예 학습하지 못하고, 남은 데이터 쪽으로 결과가 치우칩니다.
- • 일관성(Consistency): 같은 대상이 시스템마다 같게 표현되는가. "Robert Smith"와 "Bob Smith"가 다른 사람으로 취급되면, 모델은 같은 개체를 둘로 쪼개 혼동합니다.
- • 적시성(Timeliness): 데이터가 현재를 반영하는가. 고정된 과거 데이터로 학습한 모델은 최신 사건을 물으면 환각이 늘어나는 경향이 보고됩니다.
2.2AI 시대에 추가된 세 차원
모델 학습이라는 용도가 더해지면서 세 가지 축의 중요도가 크게 올라갔습니다.
- • 대표성(Representativeness): 데이터가 실제 분포를 닮았는가. 한쪽에 치우친 샘플은 치우친 모델을 만듭니다. LLM 환각 원인 분석에서 학습 데이터 편향이 가장 큰 비중을 차지한다는 보고가 이를 뒷받침합니다.
- • 유효성(Validity): 값이 기대한 범위·형식·타입에 맞는가. 날짜 칸에 문자열이, 확률 칸에 음수가 들어오면 학습 파이프라인 곳곳에서 조용히 오류가 번집니다.
- • 유일성(Uniqueness): 같은 레코드가 중복되지 않는가. 중복이 많으면 모델이 특정 패턴을 실제보다 자주 본 것으로 착각해 과하게 학습합니다.
이 일곱 차원은 따로 노는 점검 항목이 아니라 서로 맞물립니다. 일관성이 무너지면 유일성 측정이 어긋나고, 대표성이 부족하면 정확도 숫자가 특정 집단에서만 좋게 나옵니다. 그래서 한두 지표만 보지 말고, 데이터셋마다 일곱 축의 상태를 함께 적어 두는 편이 안전합니다.
실무 관점: 모델 아키텍처를 바꾸는 작업보다 데이터 품질을 한 단계 올리는 작업이 더 큰 성능 개선을 가져오는 경우가 많습니다. 어느 차원이 약한지 먼저 측정하면, 어디에 노력을 들일지가 분명해집니다.
메타데이터와 계보 — 데이터의 이력서
품질이 데이터의 "상태"라면, 메타데이터와 계보는 데이터의 "이력"입니다. 메타데이터는 데이터에 관한 데이터입니다. 출처, 수집 방법, 소유자, 보존 기간, 수집의 법적 근거와 동의 상태 같은 정보가 여기 들어갑니다. 계보(lineage)는 한 걸음 더 나아가, 데이터가 어디서 출발해 어떤 변환을 거쳐 어떤 테이블과 모델에 흘러 들어갔는지의 경로를 기록합니다.
3.1계보가 없으면 생기는 일
계보가 끊긴 상태에서 모델이 이상한 답을 내면, 원인을 찾는 일은 미궁에 빠집니다. 어느 소스의 어떤 변환이 문제를 만들었는지 거슬러 올라갈 수 없기 때문입니다. 반대로 열(column) 수준까지 계보가 이어져 있으면, 잘못된 출력이 어느 입력에서 비롯됐는지 추적해 한 곳만 고치면 됩니다. 디버깅 시간이 줄고, 같은 실수가 반복되지 않습니다.
3.2규제가 계보를 의무로 만든다
계보는 이제 선택이 아니라 의무로 이동하고 있습니다. EU AI Act는 2026년 8월 2일부터 범용 AI(GPAI)를 포함한 대부분의 의무 조항을 시행하며, 학습에 쓰인 데이터의 출처와 처리 과정을 문서화하도록 요구합니다. "이 모델이 무엇을 학습했는지 설명할 수 있는가"라는 질문에 답하려면 계보 기록이 전제되어야 합니다. 이런 흐름 속에서 데이터 계보 시장은 2025년 약 17.8억 달러에서 2026년 약 21.9억 달러로, 연평균 23.1% 성장할 것으로 전망됩니다.

핵심: 메타데이터와 계보는 평소에는 잘 보이지 않다가, 문제가 터지거나 규제 당국이 물어볼 때 그 가치가 드러납니다. 데이터를 모을 때 함께 기록해 두지 않으면, 나중에 복원하는 비용이 훨씬 큽니다.
거버넌스 — 신뢰의 인프라
데이터 거버넌스는 AI가 다루는 데이터의 품질·보안·프라이버시·접근 권한을 체계적으로 관리하는 틀입니다. 규칙을 정하고, 누가 지키는지 확인하고, 어긋났을 때 바로잡는 일련의 약속이라고 봐도 좋습니다. LLM과 에이전트가 사내 깊숙한 곳의 데이터를 직접 읽고 쓰기 시작하면서, 거버넌스의 무게는 부쩍 무거워졌습니다.
4.1거버넌스가 다루는 영역
Gartner가 정리한 AI 데이터 거버넌스의 구성 요소를 실무 언어로 풀면 다음과 같습니다.
- • 검증과 확인: 개발 단계뿐 아니라 운영 중에도 데이터를 정기적으로 점검합니다.
- • 버전 관리: 데이터의 버전을 남겨, 분포가 바뀌는 드리프트에 대응하고 문제 발생 시 되돌립니다.
- • 지속적 회귀 테스트: 데이터나 모델이 조용히 나빠지지 않았는지 반복 검사합니다.
- • 관측성 지표: 데이터의 납기·신선도·정확도를 모니터링해 건강 상태를 눈에 보이게 합니다.
- • 편향·윤리 관리: 편향된 데이터를 사전에 걸러내고, 실제 고객 데이터를 학습에 쓸 때의 윤리 기준을 둡니다.
4.2에이전트가 거버넌스를 어렵게 만든다
에이전트는 사람의 일일이 거치는 승인 없이 데이터를 읽고 도구를 호출합니다. 처음엔 수십 개로 시작한 에이전트가 어느새 수백, 수천 개로 늘어나는 일도 드물지 않습니다. 이때 어떤 에이전트가 어떤 데이터에 접근할 수 있는지, 무엇을 했는지를 기록하지 않으면 통제가 사실상 불가능해집니다. RAG가 사내 문서를 검색하다 민감 정보를 노출하거나, 미세조정 과정에 개인정보(PII)가 섞여 들어가는 위험도 같은 뿌리에서 나옵니다. 거버넌스는 이 위험을 제도로 막는 장치입니다.
관점 전환: 거버넌스를 "속도를 늦추는 규제"로 보면 미루게 됩니다. 그러나 에이전트 시대에는 거버넌스가 곧 안심하고 자동화를 확장할 수 있게 해 주는 인프라입니다. 신뢰가 있어야 권한을 넘길 수 있고, 권한을 넘겨야 자동화가 의미를 가집니다.
RAG·에이전트 시대의 추가 조건
AI를 쓰는 무게중심이 학습에서 활용으로 옮겨가고 있습니다. 모델을 새로 학습시키기보다, 이미 있는 모델에 사내 데이터를 검색해 붙이거나(RAG) 에이전트가 도구를 호출해 일을 처리하게 하는 방식이 빠르게 늘었습니다. 활용 단계로 무게중심이 이동하면 데이터에 요구되는 조건도 달라집니다.
5.1RAG가 데이터에 요구하는 것
RAG는 질문이 들어오면 관련 문서를 검색해 모델에 함께 넣어 줍니다. 검색의 품질이 곧 답의 품질이 되므로, 데이터를 "검색 가능한 형태"로 다듬는 일이 중요해집니다. 문서를 의미 단위로 적절히 쪼개는 청킹, 도메인에 맞게 조정된 임베딩, 벡터 검색과 키워드 검색을 함께 쓰는 하이브리드 검색, 그리고 검색 결과를 다시 정렬·필터링하는 레이어가 핵심 부품입니다. 실무에서 검색이 실패하는 지점은 모델이 아니라 거의 항상 검색 단계입니다. 검색 증강을 제대로 붙였을 때 환각률이 약 50%에서 13.9% 수준으로 낮아졌다는 보고는, 데이터를 검색 가능하게 만드는 일의 효과를 잘 보여 줍니다.
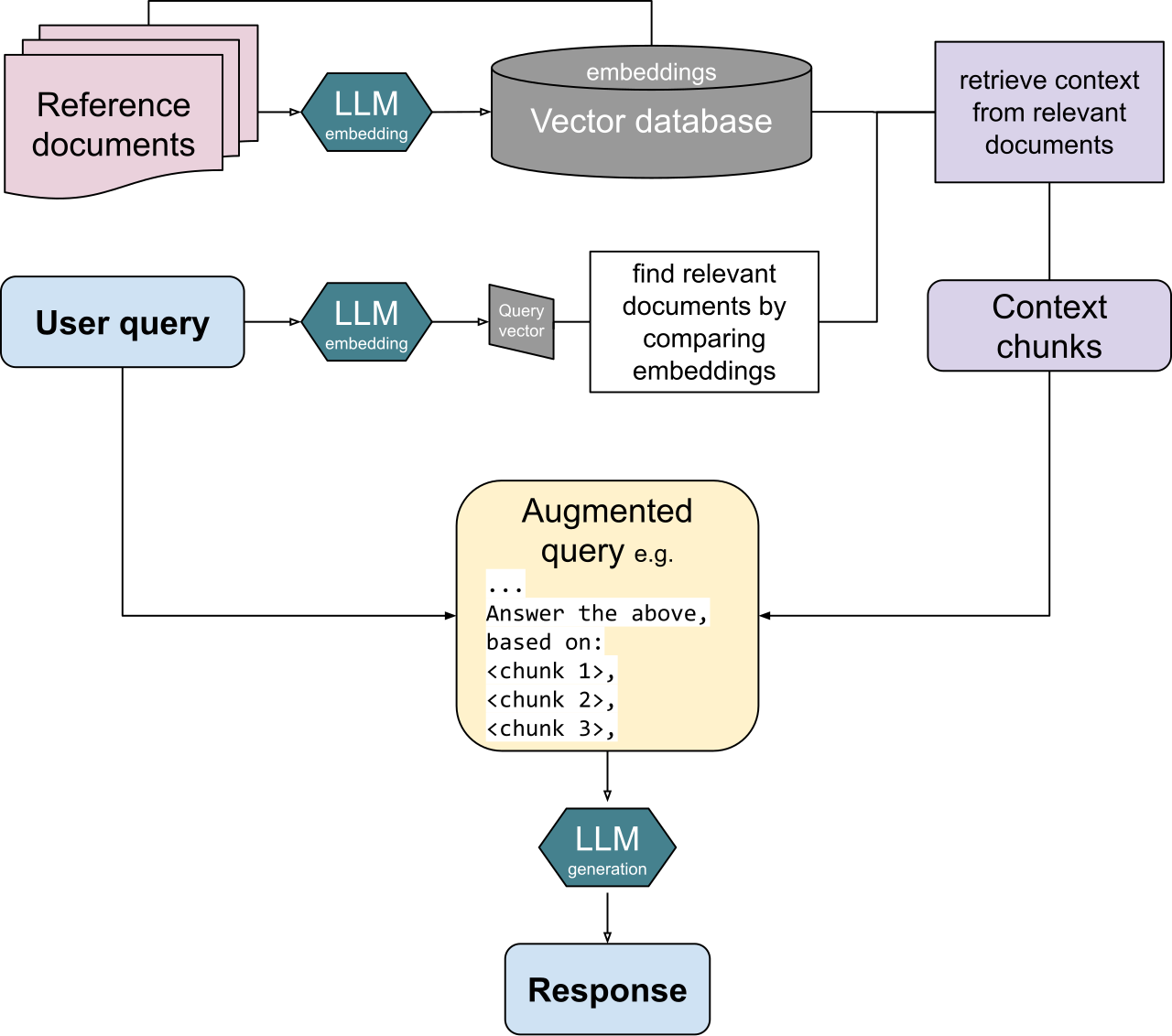
5.2에이전트가 데이터에 요구하는 것
에이전트는 스스로 판단해 데이터를 읽고 행동합니다. 그래서 두 가지가 더 필요합니다. 첫째, 접근 범위입니다. 에이전트가 의사결정에 쓰는 데이터는 허용된 범위 안에서만 닿아야 합니다. 둘째, 행동 기록입니다. 에이전트가 무엇을 읽고 무엇을 했는지가 계보의 일부로 남아야 나중에 감사할 수 있습니다. 에이전트끼리 데이터를 주고받을 때는 그 데이터에 붙은 권한과 출처 정보도 함께 전달되어야, 권한이 중간에 새지 않습니다.
요약: 학습용 데이터가 "많고 대표성 있는" 데이터였다면, RAG·에이전트용 데이터는 "검색 가능하고, 권한이 정해져 있고, 행동이 추적되는" 데이터입니다. 같은 데이터라도 활용 방식이 바뀌면 다시 준비해야 합니다.
실무 체크포인트 — 오늘부터 시작하기
개념을 알았다면 다음은 적용입니다. 한꺼번에 모든 것을 갖추려 하면 시작조차 못 합니다. 현황 파악, 파이프라인, 거버넌스, 그리고 RAG·에이전트 특화 순으로 단계를 나누면, 작은 데이터셋 하나에서도 바로 시작할 수 있습니다. 아래 항목은 권고치를 포함하되, 조직 상황에 맞게 조정하는 것을 전제로 합니다.
6.11단계 — 현황 파악
- • 핵심 데이터 소스 인벤토리를 작성합니다. 출처, 갱신 주기, 소유자를 한 표에 모읍니다.
- • 정확성·완전성·일관성·적시성 네 축에 각각 점수를 매겨, 어디가 약한지 드러냅니다.
- • 결측·중복 비율을 측정합니다. 데이터 성격마다 다르지만, 핵심 칸은 결측·중복 5% 미만을 첫 목표로 삼을 만합니다.
6.22단계 — 파이프라인 구축
- • 메타데이터 스키마를 정합니다. 출처, 수집의 법적 근거, 동의 여부, 변환 이력을 필수 항목으로 둡니다.
- • 열 수준 계보 추적을 켭니다. Snowflake·Databricks·BigQuery 등은 내장 기능으로 상당 부분을 자동 기록합니다.
- • 품질 검증을 파이프라인 안에 자동으로 끼워 넣습니다. 배포 후에 문제를 발견하는 비용은 배포 전에 막는 비용보다 훨씬 큽니다.
6.33단계 — 거버넌스 적용
- • 데이터 접근 권한을 등급으로 분류하고, AI 에이전트가 닿을 수 있는 범위를 명시합니다.
- • 개인정보·민감정보 마스킹 정책을 RAG가 검색하는 소스에도 똑같이 적용합니다.
- • 데이터 드리프트 모니터링을 켜고, 학습 시점 분포와 현재 분포를 주기적으로 비교합니다.
6.44단계 — RAG·에이전트 특화 (해당 시)
- • 고정 크기 청킹에서 문맥을 인식하는 청킹으로 전환을 검토합니다.
- • 벡터 검색과 키워드(BM25) 검색을 함께 쓰는 하이브리드 검색을 구성합니다.
- • 검색 결과를 다시 정렬·필터링하는 레이어를 두고, 에이전트의 행동 로그를 계보에 통합합니다.
시작점: 네 단계를 한 번에 끝낼 필요는 없습니다. 가장 중요한 데이터셋 하나를 골라 1단계 현황 파악부터 해 보면, "우리 데이터가 AI에 쓸 수 있는 상태인가"라는 막연한 질문이 측정 가능한 항목으로 바뀝니다. 측정되지 않은 데이터는 준비된 것이 아니라 그저 가능성에 머뭅니다.
Editor's Note: 페블러스는 데이터 품질을 정확성·일관성·완전성의 세 축으로 정의하고, DataClinic을 통해 데이터셋을 진단해 어느 신호가 무너졌는지 측정 가능한 형태로 보여 줍니다. 이 글에서 다룬 일곱 차원과 계보·거버넌스의 관점은 그 진단의 배경이 되는 생각입니다. "데이터가 충분한가"에서 "데이터가 진단되었는가"로 질문을 옮기는 일에 관심이 있다면, 가진 데이터의 품질 차원부터 한 번 측정해 보시길 권합니다.
참고문헌
학술 논문
- 1.Zhou, Y., Tu, F., Sha, K., Ding, J., & Chen, H. (2024). "A Survey on Data Quality Dimensions and Tools for Machine Learning." IEEE International Conference on Artificial Intelligence Testing (AITest 2024).
- 2.Sng, G., Zhang, Y., & Mueller, K. (2024). "A Novel Approach to Eliminating Hallucinations in Large Language Model-Assisted Causal Discovery." arXiv:2411.12759.
업계·보도
- 3.SQ Magazine. (2026). "LLM Hallucination Rate Up to 82%: 40+ Stats (2026)."
- 4.Gartner. (2024). "Gartner Predicts 30% of Generative AI Projects Will Be Abandoned After Proof of Concept By End of 2025." Gartner Newsroom.
- 5.Research and Markets / GlobeNewswire. (2026). "Data Lineage for Large Language Model (LLM) Training Market Report 2026."
공식 문서
- 6.Gartner. (2025). "AI-Ready Data Essentials to Capture AI Value." Gartner Articles.
- 7.IBM. (2026). "Why AI Data Quality Is Key To AI Success." IBM Think.
- 8.European Parliament and Council of the EU. (2024). "Regulation (EU) 2024/1689 — EU AI Act, Articles 10 & 53." Official Journal of the EU.